溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文內容主要在于,整體把握Hadoop體系各個組成部分,及其各個組件的功能,宏觀上闡述,為進一步學習hadoop,打下基礎。
1.開源免費,因為開源,所以用的也放心。
2.社區活躍,容易溝通
3.設計分布式存儲和計算的方方面面
4.已經在企業中良好運作
Hadoop目前已經更新到二代,較之一代有很大改進:
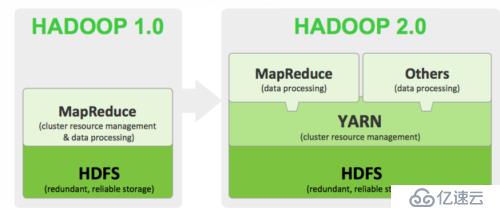
最為主要的區別就是在HDFS之上和MapReduce之間添加了一個新的參與則YARN。
到這里,首先說明一下,Hadoop最為重要的就兩部分:一分布式存儲(HDFS)二大數據計算(MapRudece)。一代Hadoop運行在FDHS之上的計算框架只有MapReduce,應用受到了很大限制,到了二代,YARN就橫空出世。
這里可以簡單理解YARN就像一個擴展巢,在YARN上面可以運行很多的計算框架了。YARN負責集群資源的統一管理和調度
1分布式存儲系統HDFS(Hadoop Distributed FileSystem)
分布式存儲系統
提供了高可靠性、高擴展性和高吞吐率的數據存儲服務
2.資源管理系統YARN(Yet Another Resource Negotiator):
負責集群資源統一管理和調度
3.分布式計算框架 MapReduce
分布式計算框架
具有易于編程、高容錯性和高擴展性等優點
簡單分層模型如下圖所示:

HDFS特點:
良好的擴展性
高容錯性
適合PB級以上的海量數據的存儲
基本原理:
將文件切割分成瞪大的數據塊,存儲到多臺機器上
將數據切分、容錯,負責均衡等功能對用戶透明化(具體如何實現,不用開發者過問) 可將HDFS看成一個容量巨大,且具有高容錯性的磁盤
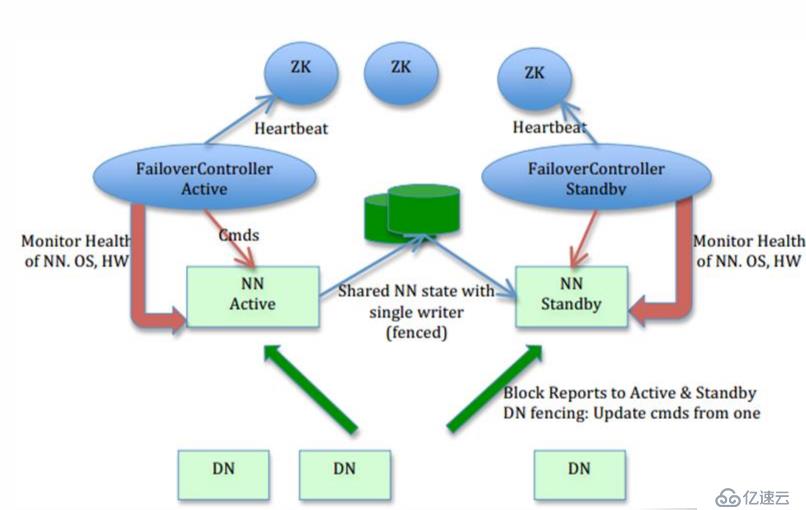
上圖所展示的就是HDFS的工作劃分:可以看出,HDFS主要有兩個部分組成:
NAMENODE節點(NN)和DATA NODE(DN)節點
大數據中,HDFS集群以Master-Slave模式運行,主要有兩類節點:一個Namenode(即Master)和多個Datanode(即Slave)。Namenode管理者文件系統的Namespace。它維護著文件系統樹(filesystem tree)以及文件樹中所有的文件和文件夾的元數據(metadata)。
以上還能看出,ZooKeeper在這里扮演者調度管理者,同時也在監控著HDFS各個節點的狀態。
因為,本文主要是宏觀說Haoop這里不不展開說了
Hadoop2.0新增的一個角色
負責集群的資源管理和調度
使得多種計算框架可以運行在一個集群中
Yarn的特點:
良好的擴展性,高可用性
對多種類型的應用程序進行統一的管理和調度
自帶了多種多用戶調度器,適合共享集群環境
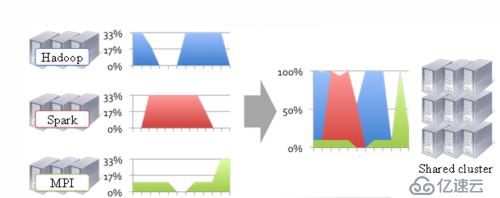
上圖比較直觀反映了,在這個集群上,不同時段上
Hadoop(主要指MapReduce) Spark(基于內存的計算框架, in-memory) MPI (也是一種計算框架)三者上都有性能不足時候,這樣通過YARN可以進行干預,讓他們之間互補,如在MapReduce性能不能完全發揮是,可以分配少一點資源,讓Spark頂上去,協調集群的資源調度。
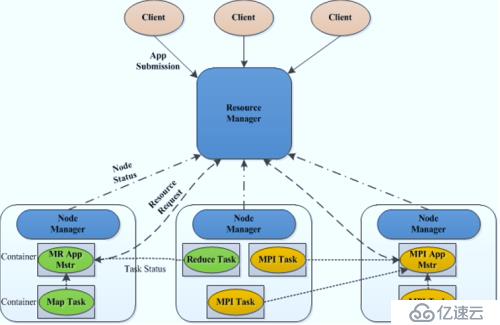
上圖,則反映YARN 的工作機制,依然能看出Master-Slave的模式運行機制
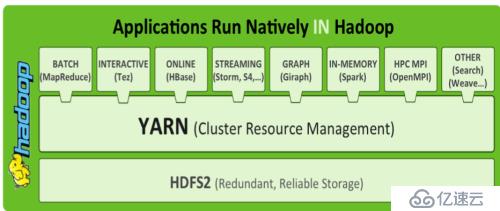
這張圖更為直觀,顯示,YARN就像插排一一樣,上面可以擴展多種分布式計算框架,
如批處理的MapReduce、交互式的Tez、流式處理的Storm ,圖處理的Giraph,內存處理計算的Spark等等
良好的擴展性
高容錯性
適合PB級以上海量數據的離線處理
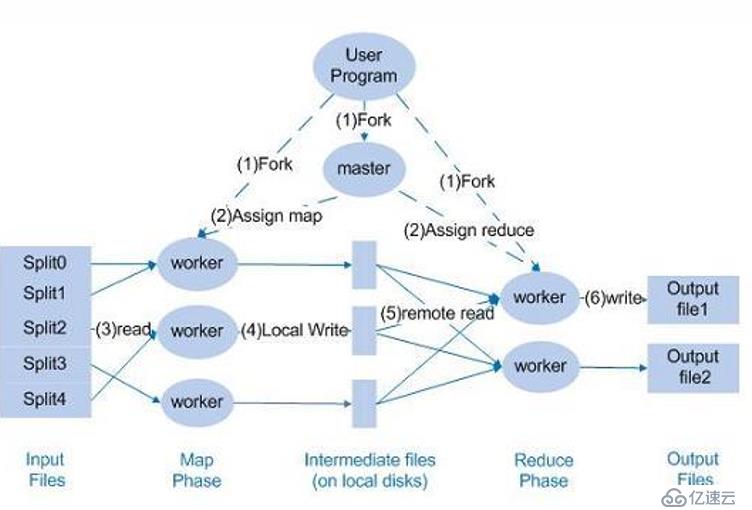
上圖,可以看出 MapReduce工作分成兩塊,Map 和 Rudece :
首先用戶書寫程序,經由master分配工作,首先將用戶提交的數據Split 成若干塊,每塊放入一個MapWorker 作業,這樣就可以并行處理數據,這個過程可以看成分發處理;處理的結果先放入本地磁盤中,然后再由 Reduce部分中的worker在計算,最終輸出結果,傳入HDFS中去。這里值得注意的是,輸入的文件格式和最終處理的格式始終保持一致的,這也包括中間處理的結果文件格式。
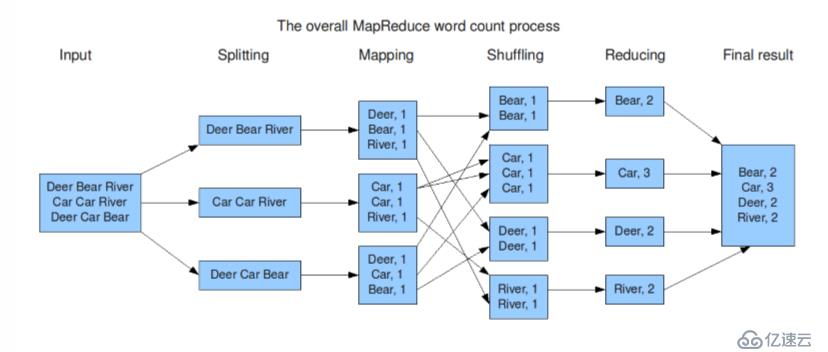
這張圖,反映的是MapReduce對文件中出現的單詞統計的程序,先將文件中的詞拆分幾個部分,然后在Map作業處理統計,經shuff 洗牌,然后交由Rudce處理作業,這個時候可以看出,中間處理的數據已經有所變化,已經做了歸并的處理,這個時候只要在歸并的基礎上再進行統計,將最終的結果輸出。
下面我們通過兩張Hadoop生態系統總圖來比交一下1.0和2.0的差異:
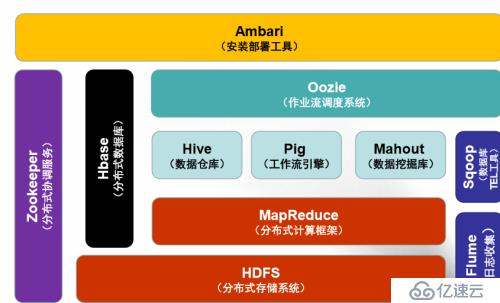
Hadoop1.0
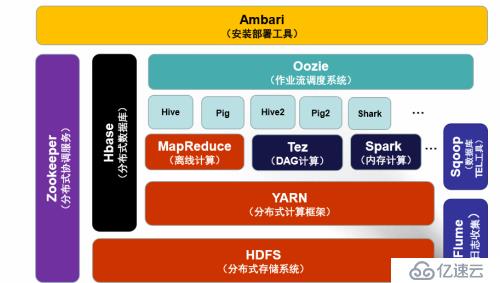
Hadoop2.0
簡單說明:
各個組件功能圖中都有標明,這里不贅述了。
主要說一下Hive,Pig ,Mahout
首先,我們要處理數據,一般是通過書寫MapReduce程序來處理輸入的數據,其代碼是有java書寫。這樣就導致了那些沒有java基礎但又想要做大數據處理的工作者犯難了。
這樣Hive和Pig就登場了,這里可以理解他們是兩位翻譯官。
Hive(Facebook提出)提供了一種類似于傳統Sql語句的Hql語言,來書寫要處理的數據代碼。通過Hive就可以實現將Hql寫的代碼,自動轉變成MapReduce程序。
同理,Pig提出了一種新PigLatin的語言,書寫處理數據的程序。他也能轉成MapReduce程序
Mahout提供了數據挖掘庫,這里包含了大量算法,主要包括三大類:
推薦(Recommendation)
聚類(Clustering)
分類(Classification)
這樣,開發人員就不發費大量時間在構筑算中,提高工作效率。
Oozie它使得開發人員能夠調度電子郵件通知方面的重復作業,或者調度使用 Java、UNIX Shell、Apache Hive、Apache Pig 和 Apache Sqoop 等各種編程語言編寫的重復作業。
目前計算框架和作業繁多:
MapReduce Storm Hive Pig 等
這樣就會存在以下問題:
1. 不同作業之間存在依賴關系(DAG)
2. 有的作業周期執行
3. 有的作業需要定時執行
4. 作業執行狀態需要監控與報警(發郵件,短信)
這個時候就需要Oozie進行統一管理和調度
HBase:Hadoop的數據庫
高可靠性
高性能
面向列
良好的擴展性
組成:
Table表:類似傳統數據中的表
ColumnFamily :列族
table在水平方向有一個或者多個Column Family組成
一個column family 中可以由任意多個Column組成
RowKey:行鍵
Table的主鍵
Table中的記錄按照RowKey排序
TimeStamp:時間戳
每個行數據均對應一個時間戳
版本號
Zookeeper:它是一個為分布式應用提供一致性服務的軟件,提供的功能包括:配置維護、域名服務、分布式同步、組服務等。
ZooKeeper的目標就是封裝好復雜易出錯的關鍵服務,將簡單易用的接口和性能高效、功能穩定的系統提供給用戶。
覆蓋范圍:HDFS YARN Storm HBaseFlume Dubbo(阿里巴巴) Metaq(阿里巴巴)
Sqoop:(數據同步工具)
連接Hadoop與傳統數據庫之間的橋梁
支持多種數據庫,包括MySql、DB2等
插拔式,用戶可根據需要支持新的數據庫
本質上一個MapReduce程序:
充分利用MapReduce分布式并行的特點MapReduce容錯性
Flume(日志搜集工具):
分布式
高可靠性
高容錯性
易于定制與擴展
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





