溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
字數統計:
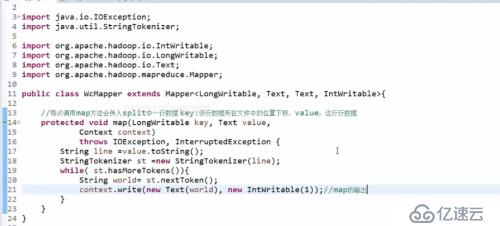
MapReduce過程:
寫一個繼承mapper的類,聲明輸入(基本固定)輸出(看需求)類型
重寫map(K,V,context),map方法會被調用多次,每次調用map方法讀取split傳過來的一行數據,需要將這一行數據切割(StringTokeizer類,默認看空格切割)
While遍歷,通過context輸出
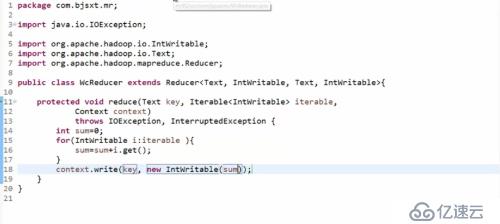
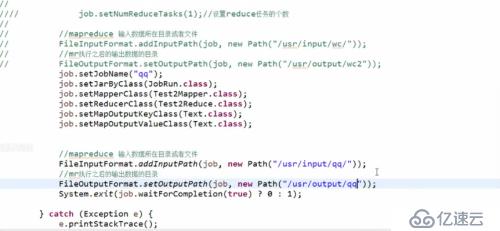
要書寫一個程序主入口類,將程序打包發給JobTracker(移動計算而不是移動數據)
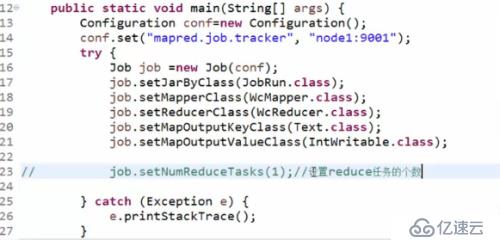

注意,這里因為是本地的程序,將程序打成xxx.jar包,放入namenode節點的服務器上執行
Hadoop/bin有個hadoop命令
#./hadoop (回車) 展開所有和hadoop組合的命令
#./hadoop jar path/xxx.jar ww.cola.JobRun
------------------------------------------------------------------
好友推薦系統:笛卡爾積運算
一對朋友的關系,每個個體既是主又是從,即一個人又做K又做V,
因此map處理后的數據會增加,每調用一次map方法,輸出兩次數據,且K和V
對調。
Map過程:
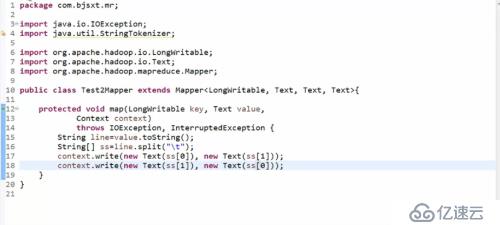
在經過系統默認shuff處理,對相同K值得數據進行了合并
出現如下形式:(Key和Value用冒號隔開):
A:B C D E //要處理他們之間可能的關系,只要將Value值做笛卡爾積
B: G
C:F
。。。
。。
Reduce過程:
用Set存儲因為可以去重
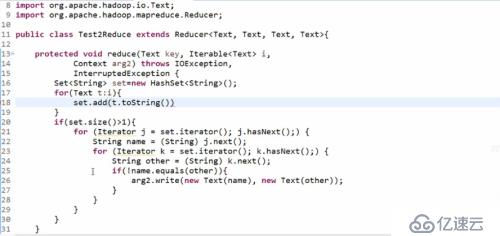
---------------------------------------------------------------------------------
精準廣告推送:并且按照關注度由高到底排序
案例:在新浪微博中給小米手機打廣告,找到那些關注手機的人,這些用在一登錄后就彈出廣告,并按關注度高低排序。
關注度權重公式:W=TF*Log(N/DF) (打分)
TF:當前的關鍵字在該片微博內容中出現的次數
DF:當前的關鍵字在所有微博中內容中出現的條數,比如,“小米”,在某條微博中出現4次,只記為1條數據
N:微博總數
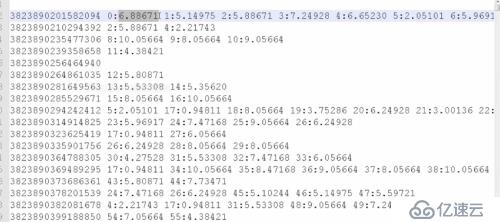
結果顯示:(為了減少磁盤內容的開銷,將不同關鍵詞用唯一數字標識)
微博的id 關鍵詞1:分數 關鍵詞2:分數 關鍵詞3:分數 ….
之后我會專門寫一篇博客
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





