溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Node.js + imgcook如何自動生成依賴”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!

imgcook 在淘寶內部版本提供了類似依賴管理的功能,用于在 imgcook 編輯器編寫函數時引入其他依賴包,比如 axios、underscore、@rax/video 等。
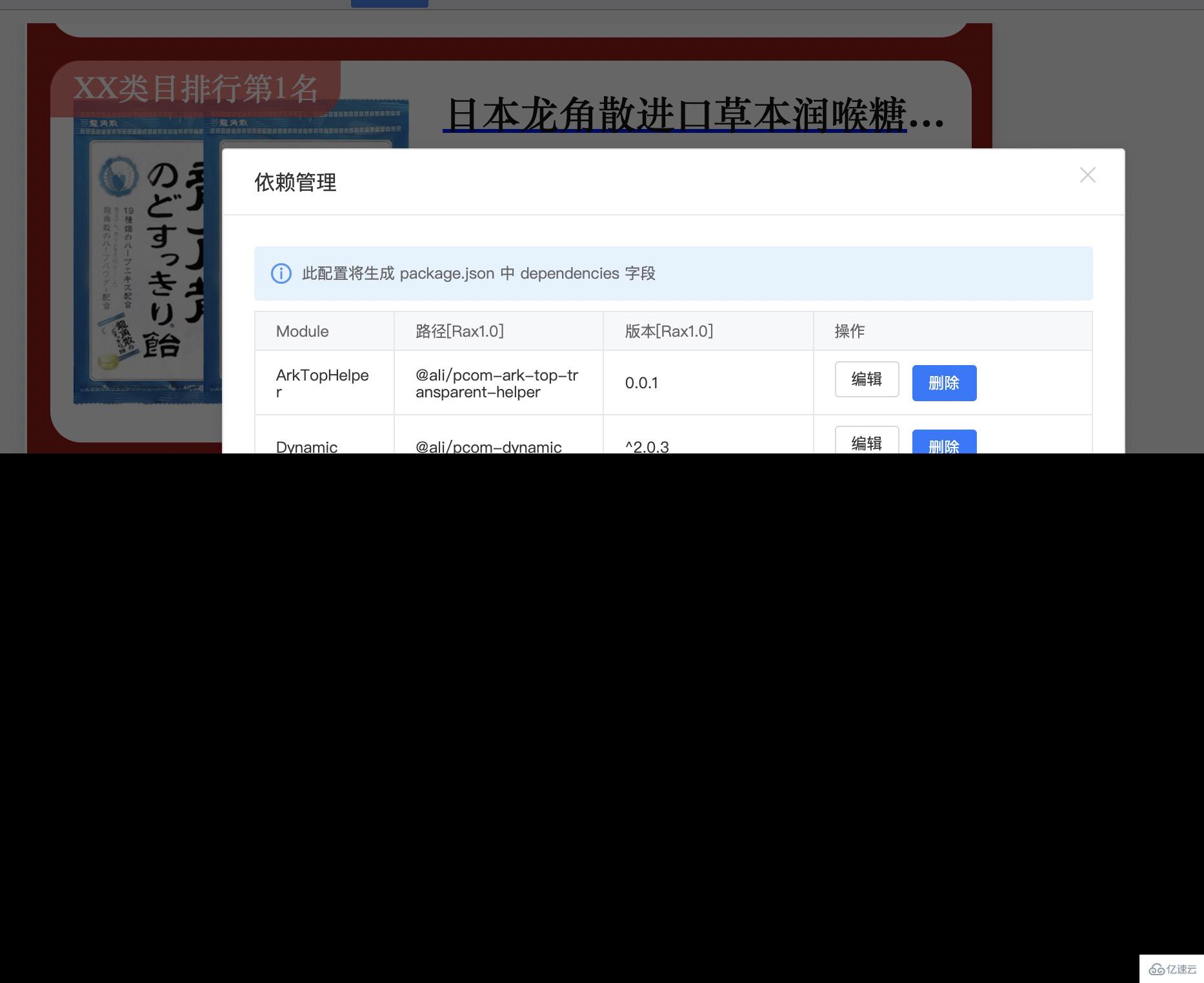
不過從使用體驗上,還是較為繁瑣,因為編輯器并沒有讓大家形成像在 package.json 聲明依賴的習慣,而且因為編輯器是 GUI 界面,所以從每個函數打開代碼,并查看依賴的操作是比較繁瑣的,這就導致每次開發完一個 imgcook 模塊后,如果依賴了其他包(大部分情況下都需要),就需要一個個打開函數并確認版本號,并在依賴管理中添加,這在我使用的過程中,往往是一次痛苦的過程。
imgcook 提供了 Schema 源碼開發模式,通過在編輯器中直接修改模塊協議(Schema)就能替代 GUI 的操作步驟,然后通過搜索 dependencies,我發現依賴管理功能是通過協議中的 imgcook.dependencies 實現的:
{
"alias": "Axios",
"packageRax1": "axios",
"versionRax1": "^0.24.0",
"packageRaxEagle": "axios",
"versionRaxEagle": "^0.24.0",
"checkDepence": true
}由于函數的代碼也存在協議中,那么是不是只需通過處理原協議文檔,掃描出對應的依賴并保存到節點中,再點擊“保存”就可以看到依賴管理中的包列表被更新了。
為此我在 @imgcook/cli 中實現了拉取模塊協議內容的功能,具體 Pull Request 有:imgcook/imgcook-cli#12 和 imgcook/imgcook-cli#15,可以通過命令行工具拉取對應模塊的協議(Schema)如下:
$ imgcook pull <id> -o json
執行后會把模塊協議內容輸出到命令行中的 stdout。
有了這個功能后,就可以實現一些命令行工具,基于 Unix Pipeline 程序,與 imgcook-cli 的數據源形成協作,舉個例子,通過 imgcook pull 輸出的 JSON 并不易讀,那么不妨寫一個 imgcook-prettyprint 來美化輸出結果,代碼實現如下:
#!/usr/bin/env node
let originJson = '';
process.stdin.on('data', (buf) => {
originJson += buf.toString('utf8');
});
process.stdin.on('end', () => {
const origin = JSON.parse(originJson);
console.log(JSON.stringify(origin, null, 2));
});上面的程序通過 process.stdin 接收管線(Pipeline)上游的數據,即 imgcook 模塊協議內容,然后在 end 事件中解析并美化輸出,運行如下命令:
$ imgcook pull <id> -o json | imgcook-prettyprint
就能看到美化后的輸出結果了,這就是一個 Unix Pipeline 程序的簡單示例。
接下來就來看下如何通過這種方式,完成依賴的自動生成。與上面例子類似,我們再創建一個文件 ckdeps:
#!/usr/bin/env node
let originJson = '';
process.stdin.on('data', (buf) => {
originJson += buf.toString('utf8');
});
process.stdin.on('end', () => {
transform();
});
async function transform() {
const origin = JSON.parse(originJson);
const funcs = origin.imgcook?.functions || [];
if (funcs.length === 0) {
process.stdout.write(originJson);
return;
}
console.log(JSON.stringify(origin));
}通過 origin.imgcook.functions,可以獲取到函數的代碼內容,比如:
{
"content": "export default function mounted() {\n\n}",
"name": "mounted",
"type": "lifeCycles"
}那么接下來就是通過解析 content,獲取到代碼中的 import 語句,再生成對應的依賴對象到 origin.imgcook.dependencies 中,那么我們需要引用 @swc/core 來解析 JavaScript 代碼:
const swc = require('@swc/core');
await Promise.all(funcs.map(async ({ content }) => {
const ast = await swc.parse(content);
// the module AST(Abstract Syntax Tree)
}));獲取到 ast 后,就能通過代碼獲取 import 語句的信息了,不過由于 ast 比較復雜,@swc/core 提供了專用的遍歷機制如下:
const { Visitor } = require('@swc/core/visitor');
/**
* 用于保存通過函數解析, 獲得的依賴對象列表
*/
const liveDependencies = [];
/** * 定義訪問器 */
class ImportsExtractor extends Visitor {
visitImportDeclaration(node) {
let alias = 'Default';
liveDependencies.push({
alias,
packageRax1: node.source.value,
versionRax1: '',
packageRaxEagle: node.source.value,
versionRaxEagle: '',
checkDepence: true,
});
return node;
}
}
// 使用方式
const importsExtractor = new ImportsExtractor();
importsExtractor.visitModule(ast);類 ImportsExtractor 繼承自 @swc/core/visitor 的 Visitor,由于是要遍歷 import 聲明語句,它的語法類型名稱是 ImportDeclaration,因此只需要實現 visitImportDeclaration(node) 方法,即可在方法內獲得所有的 import 語句,再按照對應節點的結構轉換成依賴對象并更新就好。定義好抽取器后,剩下的事情就是把 ast 喂給抽取器,這樣就能把模塊所有的依賴都收集起來,用于后面依賴的生成。
從上面的代碼可以看到,版本號目前使用了空字符串,這會導致我們如果更新協議內容,依賴的版本信息會丟失,因此我們需要定義一種獲取版本的方法。
由于前端的依賴都是存儲在 NPM Registry 上的,因此我們可以通過 HTTP 接口來獲取版本,比如:
const axios = require('axios');
async function fillVersions(dep) {
const pkgJson = await axios.get(`https://registry.npmjs.org/${dep.packageRax1}`, { type: 'json' });
if (pkgJson.data['dist-tags']) {
const latestVersion = pkgJson.data['dist-tags'].latest;
dep.versionRax1 = `^${latestVersion}`;
dep.versionRaxEagle = `^${latestVersion}`;
}
return dep;
}我們按照 https://registry.npmjs.org/${packageName} 的規則,就能拿到存儲在 Registry 中的包信息,然后 data['dist-tags'].latest 代表的是 latest 標簽對應的版本,簡單來說就是當前包的最新版本,然后再基于這個版本號增加一個 ^ 版本前綴即可(你也可以按照自己的訴求修改最終的版本以及 NPM Registry)。
最后一步,就是把我們從函數代碼中抓取的依賴信息更新,并輸出出來:
async function transform() {
// ...
origin.imgcook.dependencies = newDeps;
console.log(JSON.stringify(origin));
}然后通過運行:
$ imgcook pull <id> -o json | ckdeps
> { ..., "dependencies": [{ ...<updated dependencies> }] }然后,開發者只需要把輸出的 JSON 拷貝到編輯器中保存。哦,等等,在編輯器中并不能直接使用 JSON 保存,而是需要使用 ECMAScript Module 的方式(export default { ... }),那這樣是不是意味著每次都需要手動編輯一下呢,答案是否,Unix Pipeline 的思路非常利于解決這種流程問題,我們只需要再新建一個節點腳本 imgcook-save 即可:
#!/usr/bin/env node
let originJson = '';
process.stdin.on('data', (buf) => {
originJson += buf.toString('utf8');
});
process.stdin.on('end', () => {
transform();
});
async function transform() {
const origin = JSON.parse(originJson);
console.log(`export default ${JSON.stringify(origin, null, 2)}`);
}最后完整的命令是:
$ imgcook pull <id> -o json | ckdeps | imgcook-save
> export default { ... }這樣,我們就可以直接拷貝內容到編輯器。
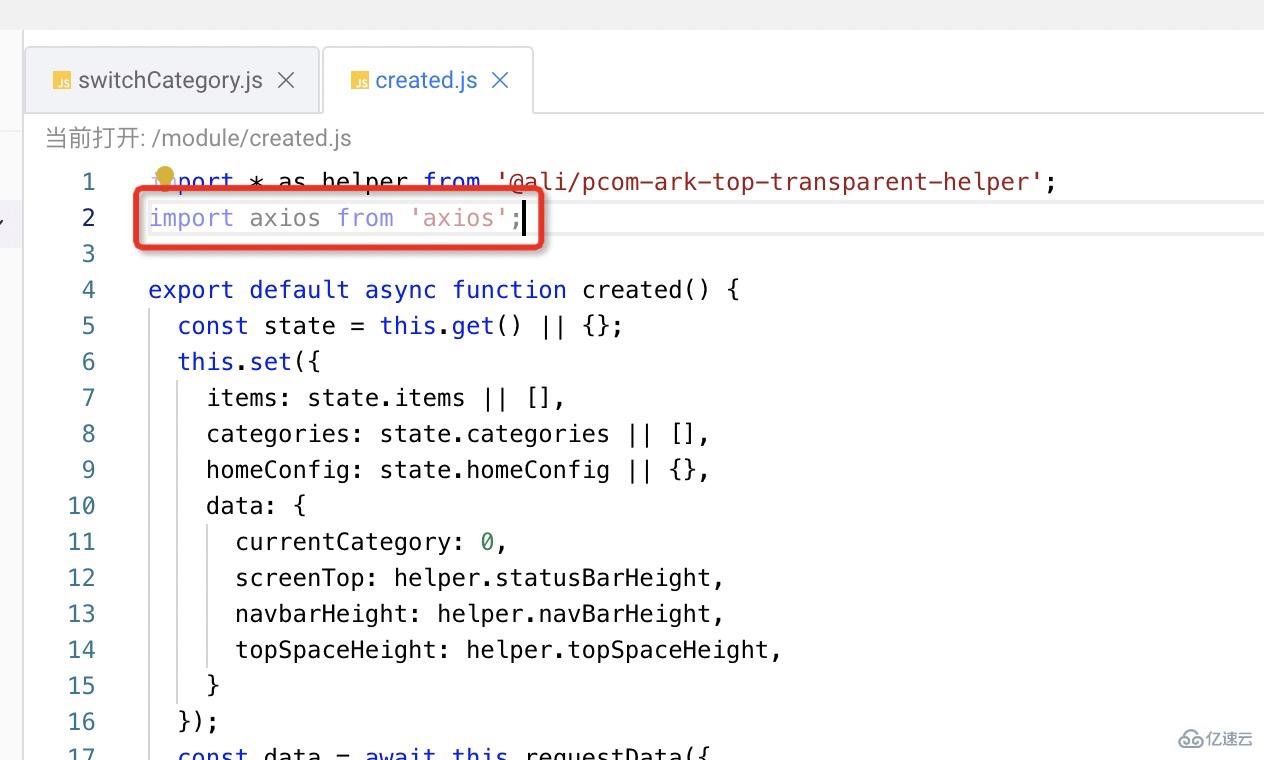
比如,我在喔其中一個項目的 created 函數中增加了 axios 的依賴,關閉窗口后點擊保存(確保 Schema 保存),然后通過命令:
$ imgcook pull <id> -o json | ckdeps -f | imgcook-save
然后在編輯器中打開 Schema 編輯,復制生成的內容并保存,然后打開“依賴管理”可以看到:
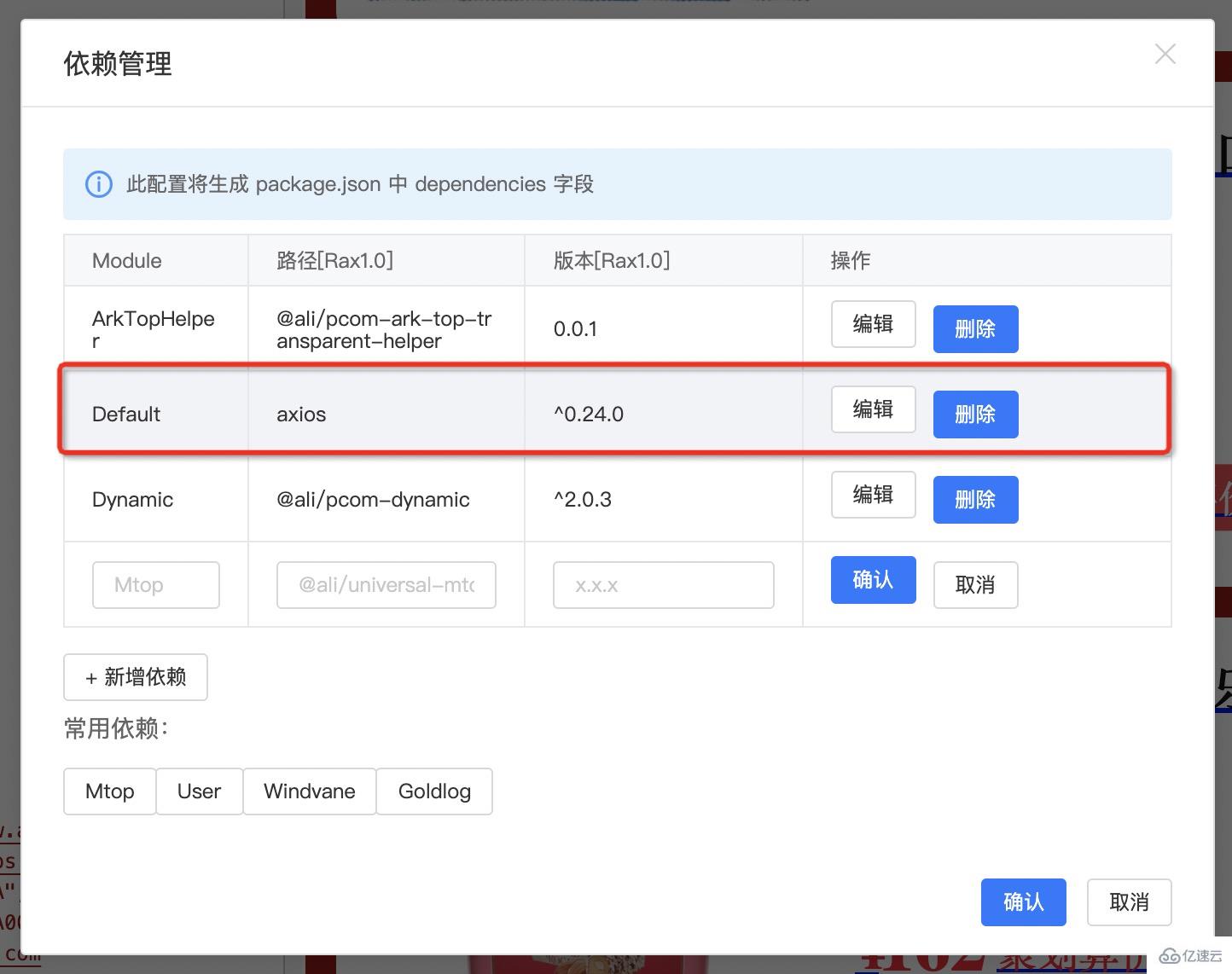
通過解析生成的代碼已經更新到依賴面板了,這下終于可以解放雙手,去做其他的事情了。
是不是這樣就結束了呢?在 macOS 中,提供了 pbcopy 命令,可以復制 stdin 到剪貼板,那么跟 imgcook 的例子結合一下:
$ imgcook pull <id> -o json | ckdeps | imgcook-save | pbcopy
這樣就省掉了自己拷貝的工作,命令執行完直接打開編輯器 ?V 即可。
最后的最后,我要升華一下主題,在 @imgcook/cli 支持了輸出 JSON 文本的功能后,就意味著 imgcook 接入了 Unix Pipeline 的生態,通過這種方式,我們可以在這個過程中構建很多有趣實用的工具,并與很多 Unix 工具協作使用(比如 bpcopy、grep、cat、sort 等)。
本文只是通過依賴的自動生成為例,使用 Unix Pipeline 的方式,驗證了其可行性以及和 imgcook 編輯器配合使用的體驗,目前來說,我可以通過這種方式,彌補不少編輯器上的體驗缺失,讓我更方便地使用 imgcook 的核心功能。
“Node.js + imgcook如何自動生成依賴”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





