溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“怎么理解Node.js中的Buffer模塊”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“怎么理解Node.js中的Buffer模塊”吧!

JavaScript對于字符串的操作十分友好
Buffer是一個像Array的對象,主要用于操作字節。
Buffer是一個典型的JavaScript和C++結合的模塊,將性能相關部分用C++實現,將非性能相關部分用JavaScript實現。
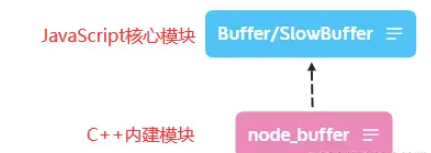
Buffer所占用的內存不是通過V8分配,屬于堆外內存。 由于V8垃圾回收性能影響,將常用的操作對象用更高效和專有的內存分配回收政策來管理是個不錯的思路。
Buffer在Node進程啟動時就已經價值,并且放在全局對象(global)上。所以使用buffer無需require引入
Buffer對象的元素未16進制的兩位數,即0-255的數值
let buf01 = Buffer.alloc(8); console.log(buf01); // <Buffer 00 00 00 00 00 00 00 00>
可以使用fill填充buf的值(默認為utf-8編碼),如果填充的值超過buffer,將不會被寫入。
如果buffer長度大于內容,則會反復填充
如果想要清空之前填充的內容,可以直接fill()
buf01.fill('12345678910')
console.log(buf01); // <Buffer 31 32 33 34 35 36 37 38>
console.log(buf01.toString()); // 12345678如果填入的內容是中文,在utf-8的影響下,中文字會占用3個元素,字母和半角標點符號占用1個元素。
let buf02 = Buffer.alloc(18, '開始我們的新路程', 'utf-8'); console.log(buf02.toString()); // 開始我們的新
Buffer受Array類型影響很大,可以訪問length屬性得到長度,也可以通過下標訪問元素,也可以通過indexOf查看元素位置。
console.log(buf02); // <Buffer e5 bc 80 e5 a7 8b e6 88 91 e4 bb ac e7 9a 84 e6 96 b0>
console.log(buf02.length) // 18字節
console.log(buf02[6]) // 230: e6 轉換后就是 230
console.log(buf02.indexOf('我')) // 6:在第7個字節位置
console.log(buf02.slice(6, 9).toString()) // 我: 取得<Buffer e6 88 91>,轉換后就是'我'如果給字節賦值不是0255之間的整數,或者賦值時小數時,賦值小于0,將該值逐次加256.直到得到0255之間的整數。如果大于255,就逐次減去255。 如果是小數,舍去小數部分(不做四舍五入)
Buffer對象的內存分配不是在V8的堆內存中,而是在Node的C++層面實現內存的申請。 因為處理大量的字節數據不能采用需要一點內存就向操作系統申請一點內存的方式。為此Node在內存上使用的是在C++層面申請內存,在JavaScript中分配內存的方式
Node采用了slab分配機制,slab是以中動態內存管理機制,目前在一些*nix操作系統用中有廣泛的應用,比如Linux
slab就是一塊申請好的固定大小的內存區域,slab具有以下三種狀態:
full:完全分配狀態
partial:部分分配狀態
empty:沒有被分配狀態
Node以8KB為界限來區分Buffer是大對象還是小對象
console.log(Buffer.poolSize); // 8192
這個8KB的值就額是每個slab的大小值,在JavaScript層面,以它作為單位單元進行內存的分配
如果指定Buffer大小小于8KB,Node會按照小對象方式進行分配
構造一個新的slab單元,目前slab處于empty空狀態
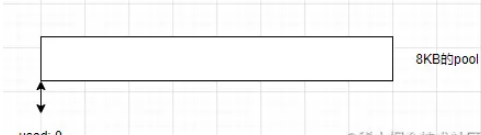
構造小buffer對象1024KB,當前的slab會被占用1024KB,并且記錄下是從這個slab的哪個位置開始使用的

這時再創建一個buffer對象,大小為3072KB。 構造過程會判斷當前slab剩余空間是否足夠,如果足夠,使用剩余空間,并更新slab的分配狀態。 3072KB空間被使用后,目前此slab剩余空間4096KB。
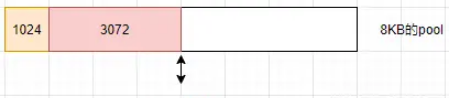
如果此時創建一個6144KB大小的buffer,當前slab空間不足,會構造新的slab(這會造成原slab剩余空間浪費)

比如下面的例子中:
Buffer.alloc(1) Buffer.alloc(8192)
第一個slab中只會存在1字節的buffer對象,而后一個buffer對象會構建一個新的slab存放
由于一個slab可能分配給多個Buffer對象使用,只有這些小buffer對象在作用域釋放并都可以回收時,slab的空間才會被回收。 盡管只創建1字節的buffer對象,但是如果不釋放,實際是8KB的內存都沒有釋放
小結:
真正的內存是在Node的C++層面提供,JavaScript層面只是使用。當進行小而頻繁的Buffer操作時,采用slab的機制進行預先申請和時候分配,使得JavaScript到操作系統之間不必有過多的內存申請方面的系統調用。 對于大塊的buffer,直接使用C++層面提供的內存即可,無需細膩的分配操作。
buffer在使用場景中,通常是以一段段的方式進行傳輸。
const fs = require('fs');
let rs = fs.createReadStream('./靜夜思.txt', { flags:'r'});
let str = ''
rs.on('data', (chunk)=>{
str += chunk;
})
rs.on('end', ()=>{
console.log(str);
})以上是讀取流的范例,data時間中獲取到的chunk對象就是buffer對象。
但是當輸入流中有寬字節編碼(一個字占多個字節)時,問題就會暴露。在str += chunk中隱藏了toString()操作。等價于str = str.toString() + chunk.toString()。
下面將可讀流的每次讀取buffer長度限制為11.
fs.createReadStream('./靜夜思.txt', { flags:'r', highWaterMark: 11});輸出得到:
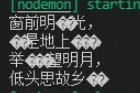
上面出現了亂碼,上面限制了buffer長度為11,對于任意長度的buffer而言,寬字節字符串都有可能存在被截斷的情況,只不過buffer越長出現概率越低。
但是如果設置了encoding為utf-8,就不會出現此問題了。
fs.createReadStream('./靜夜思.txt', { flags:'r', highWaterMark: 11, encoding:'utf-8'});
原因: 雖然無論怎么設置編碼,流的觸發次數都是一樣,但是在調用setEncoding時,可讀流對象在內部設置了一個decoder對象。每次data事件都會通過decoder對象進行buffer到字符串的解碼,然后傳遞給調用者。
string_decoder 模塊提供了用于將 Buffer 對象解碼為字符串(以保留編碼的多字節 UTF-8 和 UTF-16 字符的方式)的 API
const { StringDecoder } = require('string_decoder');
let s1 = Buffer.from([0xe7, 0xaa, 0x97, 0xe5, 0x89, 0x8d, 0xe6, 0x98, 0x8e, 0xe6, 0x9c])
let s2 = Buffer.from([0x88, 0xe5, 0x85, 0x89, 0xef, 0xbc, 0x8c, 0x0d, 0x0a, 0xe7, 0x96])
console.log(s1.toString());
console.log(s2.toString());
console.log('------------------');
const decoder = new StringDecoder('utf8');
console.log(decoder.write(s1));
console.log(decoder.write(s2));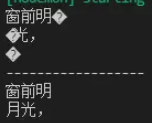
StringDecoder在得到編碼之后,知道了寬字節字符串在utf-8編碼下是以3個字節的方式存儲的,所以第一次decoder.write只會輸出前9個字節轉碼的字符,后兩個字節會被保留在StringDecoder內部。
buffer在文件I/O和網絡I/O中運用廣泛,尤其在網絡傳輸中,性能舉足輕重。在應用中,通常會操作字符串,但是一旦在網絡中傳輸,都需要轉換成buffer,以進行二進制數據傳輸。 在web應用中,字符串轉換到buffer是時時刻刻發生的,提高字符串到buffer的轉換效率,可以很大程度地提高網絡吞吐率。
如果通過純字符串的方式向客戶端發送,性能會比發送buffer對象更差,因為buffer對象無須在每次響應時進行轉換。通過預先轉換靜態內容為buffer對象,可以有效地減少CPU重復使用,節省服務器資源。
可以選擇將頁面中動態和靜態內容分離,靜態內容部分預先轉換為buffer的方式,使得性能得到提升。
在文件的讀取時,highWaterMark設置對性能影響至關重要。在理想狀態下,每次讀取的長度就是用戶指定的highWaterMark。
highWaterMark大小對性能有兩個影響的點:
對buffer內存的分配和使用有一定影響
設置過小,可能導致系統調用次數過多
感謝各位的閱讀,以上就是“怎么理解Node.js中的Buffer模塊”的內容了,經過本文的學習后,相信大家對怎么理解Node.js中的Buffer模塊這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





