溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python數據分析中如何處理缺失值,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
讓我們首先創建一個示例數據框并向其中添加一些缺失值。
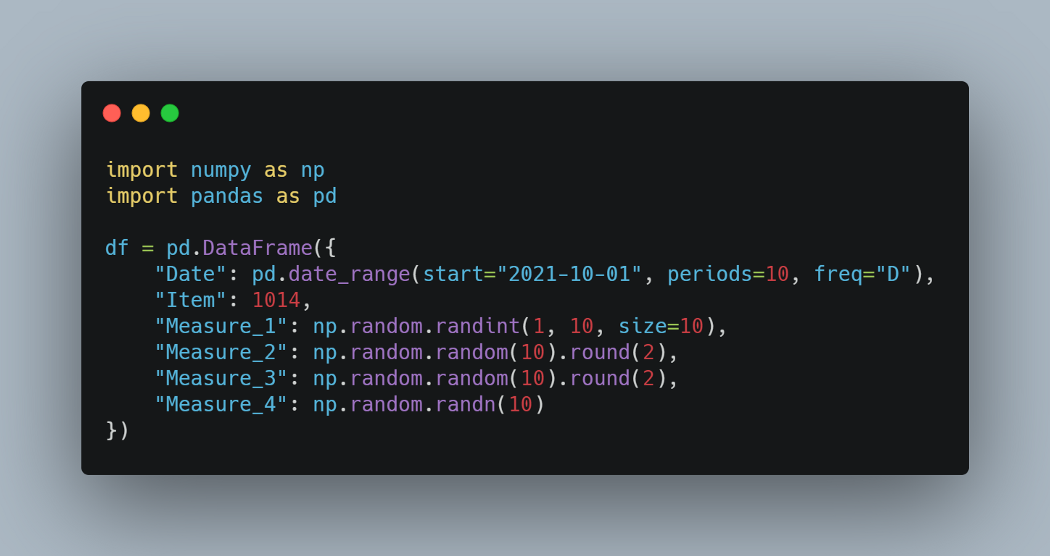
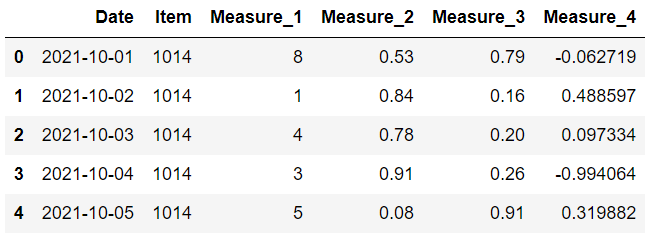
我們有一個 10 行 6 列的數據框。
下一步是添加缺失值。 我們將使用 loc 方法選擇行和列組合,并使它們等于“np.nan”,這是標準缺失值表示之一。
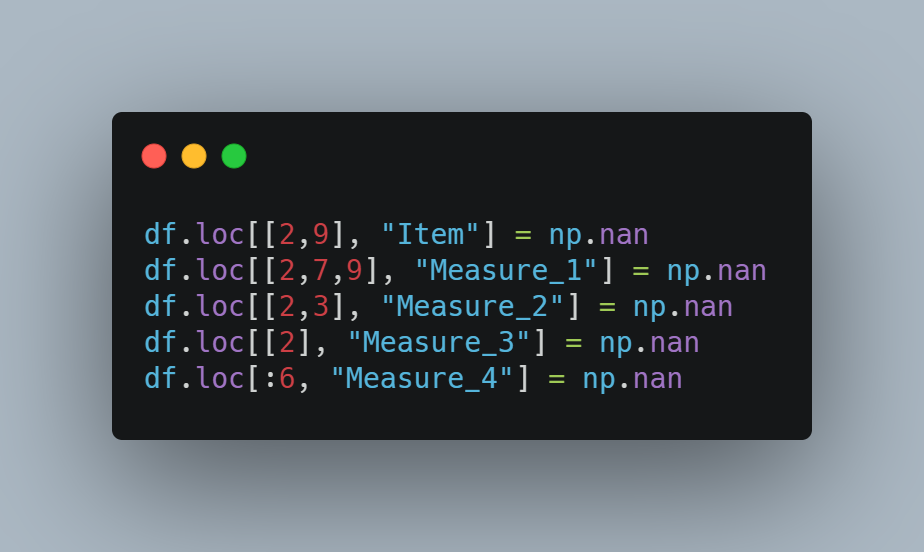
這是數據框現在的樣子:
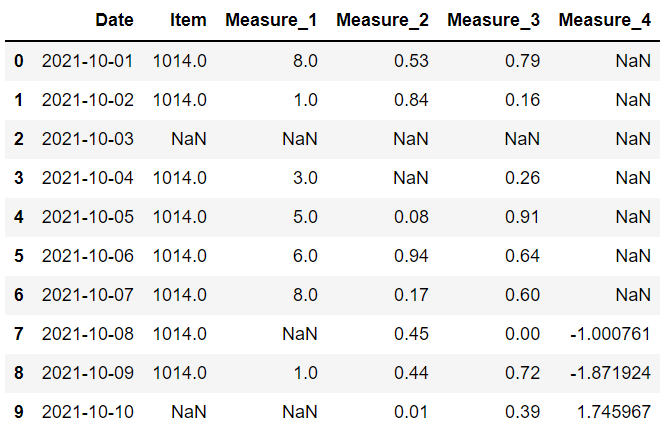
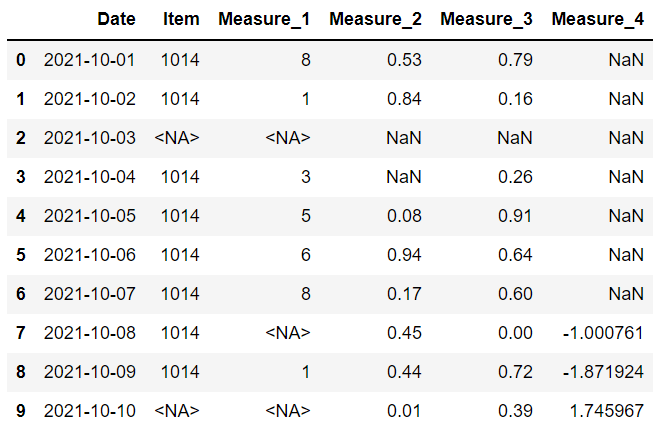
item 和 measure 1 列具有整數值,但由于缺少值,它們已被向上轉換為浮點數。
在 Pandas 1.0 中,引入了整數類型缺失值表示 (),因此我們也可以在整數列中包含缺失值。 但是,我們需要顯式聲明數據類型。
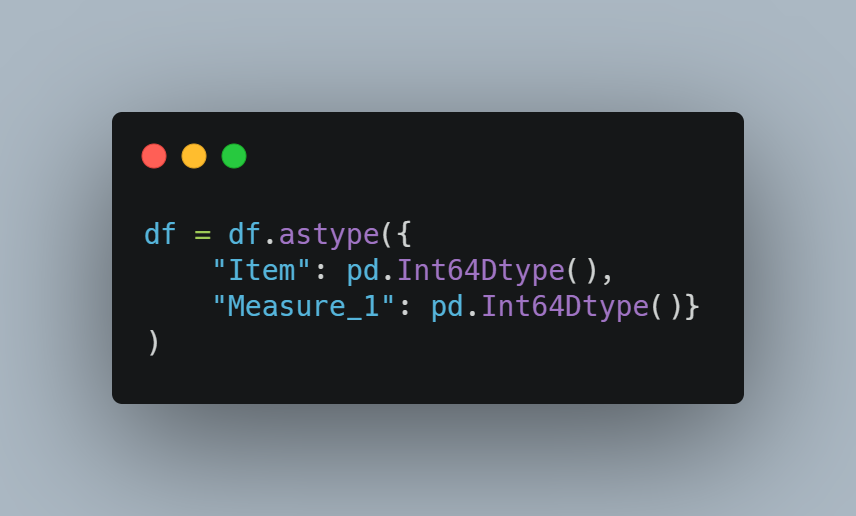
盡管有缺失值,我們現在可以保留整數列。
現在我們有一個包含一些缺失值的數據框。 是時候看看處理它們的不同方法了。
一種選擇是刪除包含缺失值的行或列。


使用默認參數值,dropna 函數會刪除包含任何缺失值的行。數據框中只有一行沒有任何缺失值。同時我們還可以選擇使用軸參數刪除至少有一個缺失值的列。

另一種情況是有一列或一行充滿缺失值。 這樣的列或行是無用的,所以我們可以刪除它們。
dropna 函數也可以用于此目的。 我們只需要改變 how 參數的值。

基于“any”或“all”的刪除并不總是最好的選擇。 我們有時需要刪除具有“大量”或“一些”缺失值的行或列。
我們不能將這樣的表達式分配給 how 參數,但 Pandas 為我們提供了一種更準確的方法,即 thresh 參數。
例如,“thresh=4”意味著至少有 4 個非缺失值的行將被保留。 其他的將被丟棄。
我們的數據框有 6 列,因此將刪除具有 3 個或更多缺失值的行。

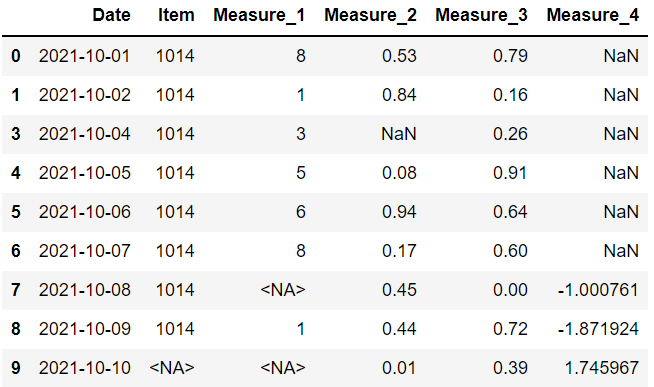
只有第三行有 2 個以上的缺失值,所以它是唯一一個被丟棄的。
在刪除列時,我們可以只考慮部分列。
dropna 函數的子集參數用于此任務。 例如,我們可以刪除在度量 1 或度量 2 列中有缺失值的行,如下所示:

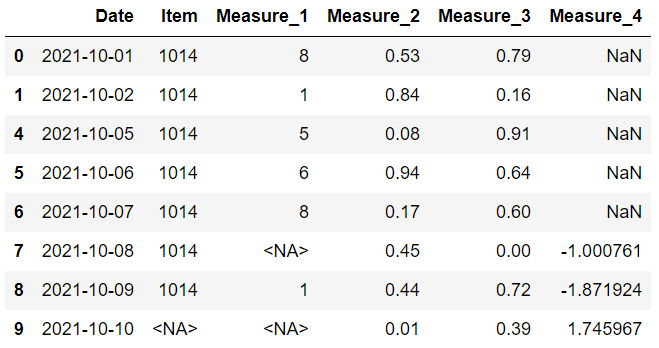
到目前為止,我們已經看到了根據缺失值刪除行或列的不同方法。放棄并不是唯一的選擇。 在某些情況下,我們可能會選擇填充缺失值而不是刪除它們。
事實上,填充可能是更好的選擇,因為數據意味著價值。 如何填補缺失值,當然取決于數據的結構和任務。
fillna 函數用于填充缺失值。
我們可以選擇一個常量值來替代缺失值。如果我們只給 fillna 函數一個常量值,它將用該值替換數據框中的所有缺失值。
更合理的方法是為不同的列確定單獨的常量值。 我們可以將它們寫入字典并將其傳遞給 values 參數。

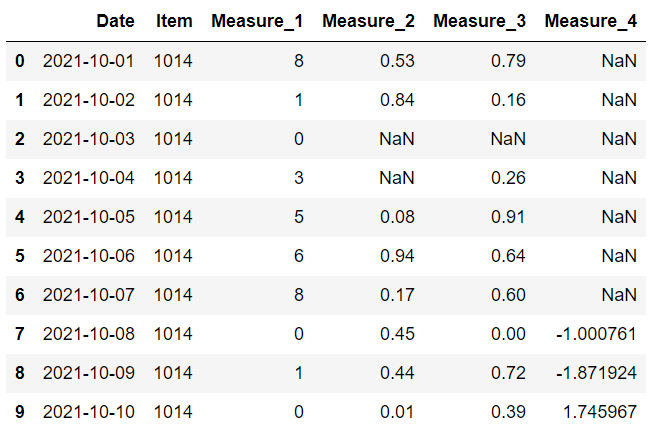
item 列中的缺失值替換為 1014,而 measure 1 列中的缺失值替換為 0。
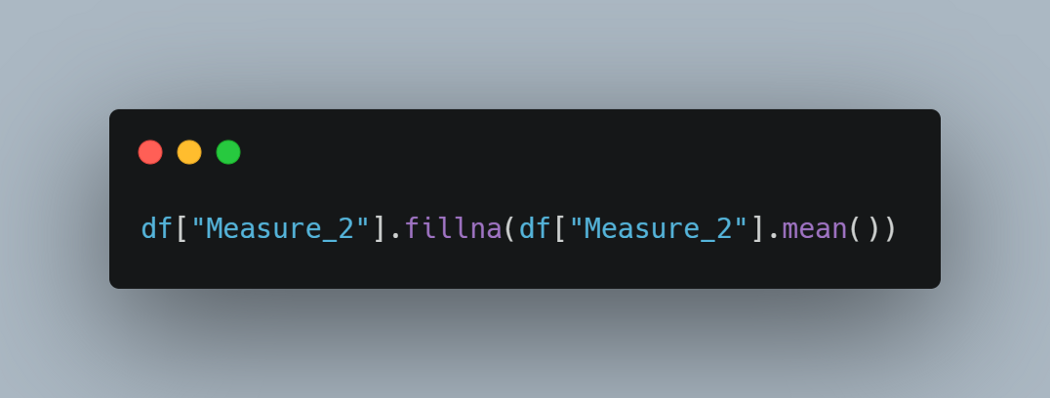
另一種選擇是使用聚合值,例如平均值、中位數或眾數。
下面這行代碼用該列的平均值替換了第 2 列中的缺失值。
可以用該列中的前一個或下一個值替換該列中的缺失值。在處理時間序列數據時,此方法可能會派上用場。 假設您有一個包含每日溫度測量值的數據框,但缺少一天的溫帶。 最佳解決方案是使用第二天或前一天的溫度。
fillna 函數的方法參數用于執行此任務。

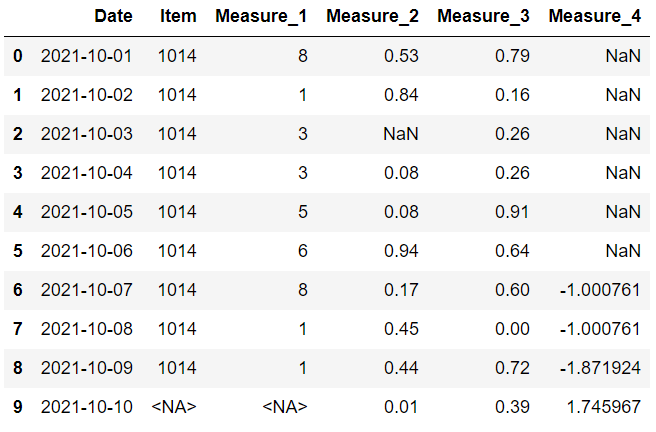
“bfill”向后填充缺失值,以便將它們替換為下一個值。看看最后一欄。 缺失值被替換到第一行。 這可能不適合某些情況。
值得慶幸的是,我們可以限制用這種方法替換的缺失值的數量。 如果我們將 limit 參數設置為 1,那么一個缺失值只能用它的下一個值替換。 后面的第二個或第三個值將不會用于替換。
我們還可以將另一個數據幀傳遞給 fillna 函數。 新數據框中的值將用于替換當前數據框中的缺失值。
將根據行索引和列名稱選擇值。 例如,如果 item 列的第二行中存在缺失值,則將使用新數據框中相同位置的值。
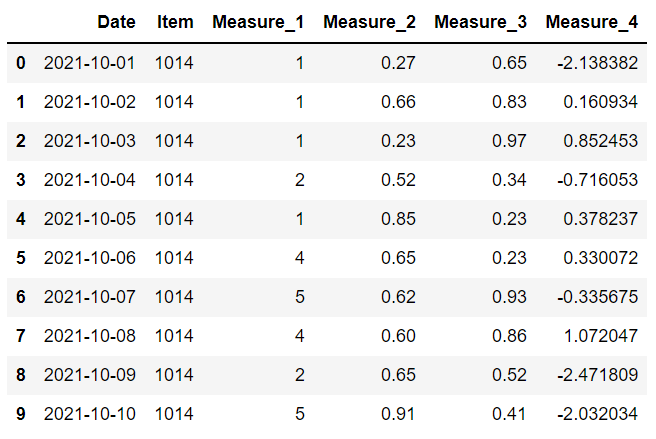
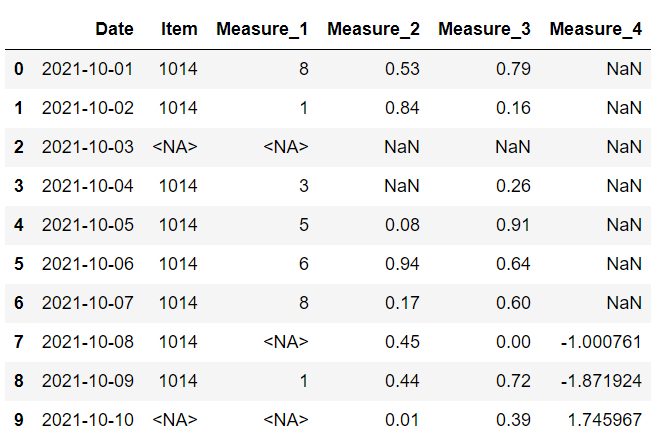
以上是具有相同列的兩個數據框。 第一個 沒有任何缺失值。
我們可以使用 fillna 函數如下:
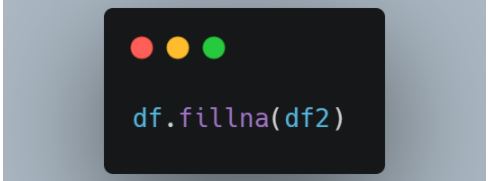
df 中的值將替換為 df2 中關于列名和行索引的值。
看完了這篇文章,相信你對“Python數據分析中如何處理缺失值”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





