溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么利用Python快速找到最大文件”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
思路:我們遍歷目錄,將文件路徑和文件大小作為生成器返回,然后插入大小為 10 的大頂堆,最后將大頂堆的內容打印即可。
借助 Python,代碼很簡潔:
import os
import time
from os.path import join, getsize
from heapq import nlargest
def walk_files_and_sizes(start_at: str):
for root, _, files in os.walk(start_at):
for file in files:
path = join(root, file)
try:
size = getsize(path) # bytes
yield path, size
except OSError:
continue
def largest_files(n: int, start_at: str) -> None:
MB = 1024 * 1024
largest = nlargest(n, walk_files_and_sizes(start_at), key=lambda x: x[1])
for path, size in largest:
print(f'{size//MB} MB {path}')
if __name__ == '__main__':
start = time.perf_counter()
largest_files(10, "/Users/aaron/")
elapsed = time.perf_counter() - start
print(f'{elapsed} seconds elapsed')我在自己電腦上跑了下,200 GB 左右的目錄,123 秒就跑完了:
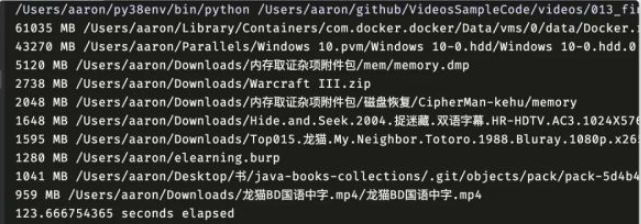
接下來刪除不需要的文件就可以了。
如果是 Windows 系統也是可以的:
largest_files(10, "C:/Users/xxx/")
“怎么利用Python快速找到最大文件”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





