溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Python中如何實現MNIST手寫體識別,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
本實驗采用的軟硬件實驗環境如表所示:

在Windows操作系統下,采用基于Tensorflow的Keras的深度學習框架,對MNIST進行訓練和測試。
采用keras的深度學習框架,keras是一個專為簡單的神經網絡組裝而設計的Python庫,具有大量預先包裝的網絡類型,包括二維和三維風格的卷積網絡、短期和長期的網絡以及更廣泛的一般網絡。使用keras構建網絡是直接的,keras在其Api設計中使用的語義是面向層次的,網絡組建相對直觀,所以本次選用Keras人工智能框架,其專注于用戶友好,模塊化和可擴展性。
MNIST(官方網站)是非常有名的手寫體數字識別數據集。它由手寫體數字的圖片和相對應的標簽組成,如:

MNIST數據集分為訓練圖像和測試圖像。訓練圖像60000張,測試圖像10000張,每一個圖片代表0-9中的一個數字,且圖片大小均為28*28的矩陣。
train-images-idx3-ubyte.gz: training set images (9912422 bytes) 訓練圖片
train-labels-idx1-ubyte.gz: training set labels (28881 bytes) 訓練標簽
t10k-images-idx3-ubyte.gz: test set images (1648877 bytes) 測試圖片
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes) 測試標簽
數據預處理階段對圖像進行歸一化處理,我們將圖片中的這些值縮小到 0 到 1 之間,然后將其饋送到神經網絡模型。為此,將圖像組件的數據類型從整數轉換為浮點數,然后除以 255。這樣更容易訓練,以下是預處理圖像的函數:務必要以相同的方式對訓練集和測試集進行預處理:
之后對標簽進行one-hot編碼處理:將離散特征的取值擴展到了歐式空間,離散特征的某個取值就對應歐式空間的某個點;機器學習算法中,特征之間距離的計算或相似度的常用計算方法都是基于歐式空間的;將離散型特征使用one-hot編碼,會讓特征之間的距離計算更加合理
# Build MLP model = Sequential() model.add(Dense(units=256, input_dim=784, kernel_initializer='normal', activation='relu')) model.add(Dense(units=128, kernel_initializer='normal', activation='relu')) model.add(Dense(units=64, kernel_initializer='normal', activation='relu')) model.add(Dense(units=10, kernel_initializer='normal', activation='softmax')) model.summary()
# Build LeNet-5 model = Sequential() model.add(Conv2D(filters=6, kernel_size=(5, 5), padding='valid', input_shape=(28, 28, 1), activation='relu')) # C1 model.add(MaxPooling2D(pool_size=(2, 2))) # S2 model.add(Conv2D(filters=16, kernel_size=(5, 5), padding='valid', activation='relu')) # C3 model.add(MaxPooling2D(pool_size=(2, 2))) # S4 model.add(Flatten()) model.add(Dense(120, activation='tanh')) # C5 model.add(Dense(84, activation='tanh')) # F6 model.add(Dense(10, activation='softmax')) # output model.summary()
模型訓練過程中,我們用到LENET-5的卷積神經網絡結構。

第一層,卷積層
這一層的輸入是原始的圖像像素,LeNet-5 模型接受的輸入層大小是28x28x1。第一卷積層的過濾器的尺寸是5x5,深度(卷積核種類)為6,不使用全0填充,步長為1。因為沒有使用全0填充,所以這一層的輸出的尺寸為32-5+1=28,深度為6。這一層卷積層參數個數是5x5x1x6+6=156個參數(可訓練參數),其中6個為偏置項參數。因為下一層的節點矩陣有有28x28x6=4704個節點(神經元數量),每個節點和5x5=25個當前層節點相連,所以本層卷積層總共有28x28x6x(5x5+1)個連接。
第二層,池化層
這一層的輸入是第一層的輸出,是一個28x28x6=4704的節點矩陣。本層采用的過濾器為2x2的大小,長和寬的步長均為2,所以本層的輸出矩陣大小為14x14x6。原始的LeNet-5 模型中使用的過濾器和這里將用到的過濾器有些許的差別,這里不過多介紹。
第三層,卷積層
本層的輸入矩陣大小為14x14x6,使用的過濾器大小為5x5,深度為16。本層不使用全0填充,步長為1。本層的輸出矩陣大小為10x10x16。按照標準卷積層本層應該有5x5x6x16+16=2416個參數(可訓練參數),10x10x16x(5x5+1)=41600個連接。
第四層,池化層
本層的輸入矩陣大小是10x10x16,采用的過濾器大小是2x2,步長為2,本層的輸出矩陣大小為5x5x16。
第五層,全連接層
本層的輸入矩陣大小為5x5x16。如果將此矩陣中的節點拉成一個向量,那么這就和全連接層的輸入一樣了。本層的輸出節點個數為120,總共有5x5x16x120+120=48120個參數。
第六層,全連接層
本層的輸入節點個數為120個,輸出節點個數為84個,總共參數為120x84+84=10164個。
第七層,全連接層
LeNet-5 模型中最后一層輸出層的結構和全連接層的結構有區別,但這里我們用全連接層近似的表示。本層的輸入節點為84個,輸出節點個數為10個,總共有參數84x10+10=850個。
初始參數設定好之后開始訓練,每次訓練需要微調參數以得到更好的訓練結果,經過多次嘗試,最終設定參數為:
優化器:adam優化器
訓練輪數:10
每次輸入的數據量:500
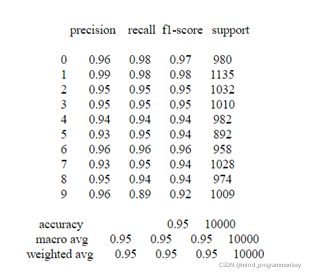
LENET-5的卷積神經網絡對MNIST數據集進行訓練,并采用上述的模型參數,進行10輪訓練,在訓練集上達到了95%的準確率

為了驗證模型的魯棒性,在上述最優參數下保存在驗證集上性能最好的模型,在測試集上進行最終的測試,得到最終的準確率為:95.13%.
為了更好的分析我們的結果,這里用混淆矩陣來評估我們的模型性能。在模型評估之前,先學習一些指標。
TP(True Positive):將正類預測為正類數,真實為0,預測也為0FN(False Negative):將正類預測為負類數,真實為0,預測為1FP(False Positive):將負類預測為正類數, 真實為1,預測為0。TN(True Negative):將負類預測為負類數,真實為1,預測也為1混淆矩陣定義及表示含義:
混淆矩陣是機器學習中總結分類模型預測結果的情形分析表,以矩陣形式將數據集中的記錄按照真實的類別與分類模型預測的類別判斷兩個標準進行匯總。其中矩陣的行表示真實值,矩陣的列表示預測值,下面以本次案例為例,看下矩陣表現形式,如下:

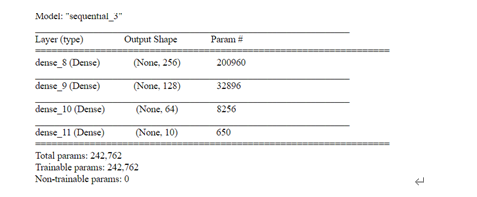
并與四層全連接層模型進行對比,全連接層的模型結構如下:
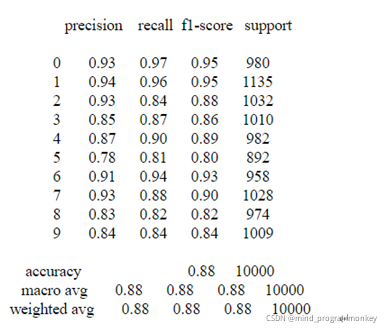
其結果如下:
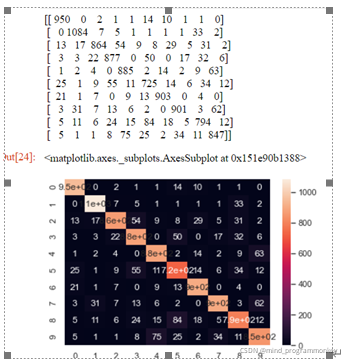
總之,從結果上來看,最后經過不斷地參數調優最終訓練出了一個分類正確率在95%左右的模型,并且通過實驗證明了模型具有很強的魯棒性。
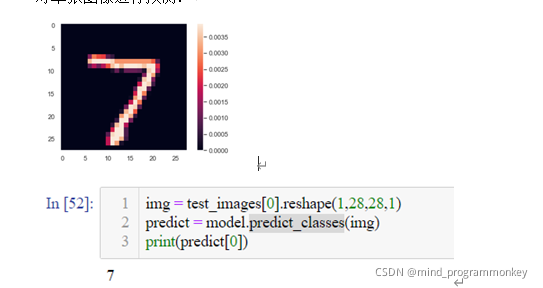
對單張圖像進行預測:
以上是“Python中如何實現MNIST手寫體識別”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





