溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“在Redis中怎么保存時間序列數據”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
我們現在做互聯網產品的時候,都有這么一個需求:記錄用戶在網站或者App上的點擊行為數據,來分析用戶行為。這里的數據一般包括用戶ID、行為類型(例如瀏覽、登錄、下單等)、行為發生的時間戳:
UserID, Type, TimeStamp
我之前做過的一個物聯網項目的數據存取需求,和這個很相似。我們需要周期性地統計近萬臺設備的實時狀態,包括設備ID、壓力、溫度、濕度,以及對應的時間戳:
DeviceID, Pressure, Temperature, Humidity, TimeStamp
這些與發生時間相關的一組數據,就是時間序列數據。這些數據的特點是沒有嚴格的關系模型,記錄的信息可以表示成鍵和值的關系(例如,一個設備ID對應一條記錄),所以,并不需要專門用關系型數據庫(例如MySQL)來保存。而Redis的鍵值數據模型,正好可以滿足這里的數據存取需求。Redis基于自身數據結構以及擴展模塊,提供了兩種解決方案。
這節課,我就以物聯網場景中統計設備狀態指標值為例,和你聊聊不同解決方案的做法和優缺點。
俗話說,“知己知彼,百戰百勝”,我們就先從時間序列數據的讀寫特點開始,看看到底應該采用什么樣的數據類型來保存吧。
在實際應用中,時間序列數據通常是持續高并發寫入的,例如,需要連續記錄數萬個設備的實時狀態值。同時,時間序列數據的寫入主要就是插入新數據,而不是更新一個已存在的數據,也就是說,一個時間序列數據被記錄后通常就不會變了,因為它就代表了一個設備在某個時刻的狀態值(例如,一個設備在某個時刻的溫度測量值,一旦記錄下來,這個值本身就不會再變了)。
所以,這種數據的寫入特點很簡單,就是插入數據快,這就要求我們選擇的數據類型,在進行數據插入時,復雜度要低,盡量不要阻塞。看到這兒,你可能第一時間會想到用Redis的String、Hash類型來保存,因為它們的插入復雜度都是O(1),是個不錯的選擇。但是,我在第11講中說過,String類型在記錄小數據時(例如剛才例子中的設備溫度值),元數據的內存開銷比較大,不太適合保存大量數據。
那我們再看看,時間序列數據的“讀”操作有什么特點。
我們在查詢時間序列數據時,既有對單條記錄的查詢(例如查詢某個設備在某一個時刻的運行狀態信息,對應的就是這個設備的一條記錄),也有對某個時間范圍內的數據的查詢(例如每天早上8點到10點的所有設備的狀態信息)。
除此之外,還有一些更復雜的查詢,比如對某個時間范圍內的數據做聚合計算。這里的聚合計算,就是對符合查詢條件的所有數據做計算,包括計算均值、最大/最小值、求和等。例如,我們要計算某個時間段內的設備壓力的最大值,來判斷是否有故障發生。
那用一個詞概括時間序列數據的“讀”,就是查詢模式多。
弄清楚了時間序列數據的讀寫特點,接下來我們就看看如何在Redis中保存這些數據。我們來分析下:針對時間序列數據的“寫要快”,Redis的高性能寫特性直接就可以滿足了;而針對“查詢模式多”,也就是要支持單點查詢、范圍查詢和聚合計算,Redis提供了保存時間序列數據的兩種方案,分別可以基于Hash和Sorted Set實現,以及基于RedisTimeSeries模塊實現。
接下來,我們先學習下第一種方案。
Hash和Sorted Set組合的方式有一個明顯的好處:它們是Redis內在的數據類型,代碼成熟和性能穩定。所以,基于這兩個數據類型保存時間序列數據,系統穩定性是可以預期的。
不過,在前面學習的場景中,我們都是使用一個數據類型來存取數據,那么,為什么保存時間序列數據,要同時使用這兩種類型?這是我們要回答的第一個問題。
關于Hash類型,我們都知道,它有一個特點是,可以實現對單鍵的快速查詢。這就滿足了時間序列數據的單鍵查詢需求。我們可以把時間戳作為Hash集合的key,把記錄的設備狀態值作為Hash集合的value。
可以看下用Hash集合記錄設備的溫度值的示意圖:

當我們想要查詢某個時間點或者是多個時間點上的溫度數據時,直接使用HGET命令或者HMGET命令,就可以分別獲得Hash集合中的一個key和多個key的value值了。
舉個例子。我們用HGET命令查詢202008030905這個時刻的溫度值,使用HMGET查詢202008030905、202008030907、202008030908這三個時刻的溫度值,如下所示:
HGET device:temperature 202008030905 "25.1" HMGET device:temperature 202008030905 202008030907 202008030908 1) "25.1" 2) "25.9" 3) "24.9"
你看,用Hash類型來實現單鍵的查詢很簡單。但是,Hash類型有個短板:它并不支持對數據進行范圍查詢。
雖然時間序列數據是按時間遞增順序插入Hash集合中的,但Hash類型的底層結構是哈希表,并沒有對數據進行有序索引。所以,如果要對Hash類型進行范圍查詢的話,就需要掃描Hash集合中的所有數據,再把這些數據取回到客戶端進行排序,然后,才能在客戶端得到所查詢范圍內的數據。顯然,查詢效率很低。
為了能同時支持按時間戳范圍的查詢,可以用Sorted Set來保存時間序列數據,因為它能夠根據元素的權重分數來排序。我們可以把時間戳作為Sorted Set集合的元素分數,把時間點上記錄的數據作為元素本身。
我還是以保存設備溫度的時間序列數據為例,進行解釋。下圖顯示了用Sorted Set集合保存的結果。
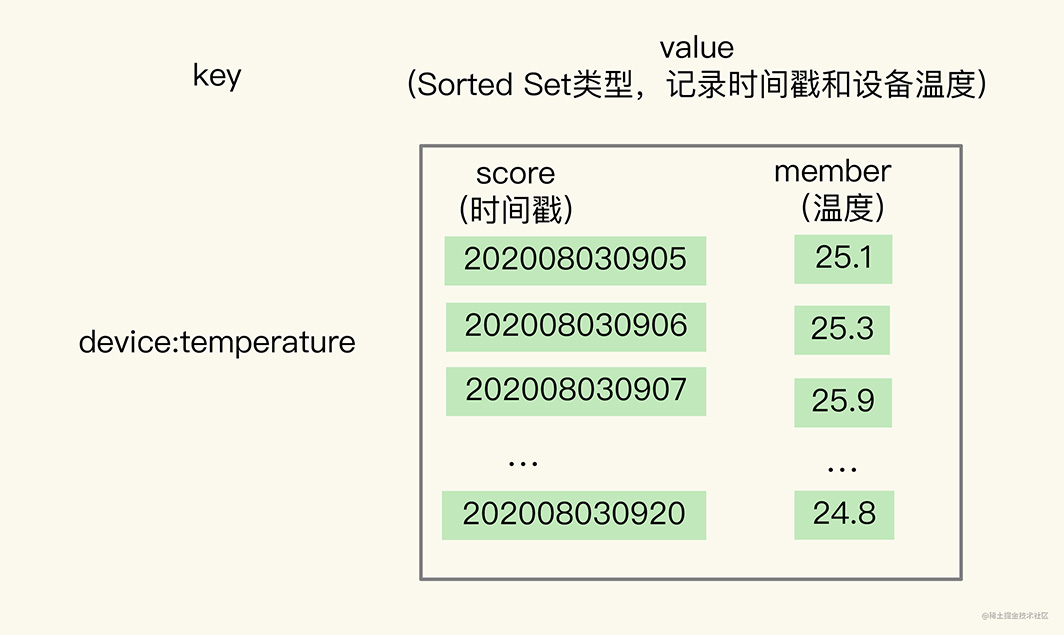
使用Sorted Set保存數據后,我們就可以使用ZRANGEBYSCORE命令,按照輸入的最大時間戳和最小時間戳來查詢這個時間范圍內的溫度值了。如下所示,我們來查詢一下在2020年8月3日9點7分到9點10分間的所有溫度值:
ZRANGEBYSCORE device:temperature 202008030907 202008030910 1) "25.9" 2) "24.9" 3) "25.3" 4) "25.2"
現在我們知道了,同時使用Hash和Sorted Set,可以滿足單個時間點和一個時間范圍內的數據查詢需求了,但是我們又會面臨一個新的問題,也就是我們要解答的第二個問題:如何保證寫入Hash和Sorted Set是一個原子性的操作呢?
所謂“原子性的操作”,就是指我們執行多個寫命令操作時(例如用HSET命令和ZADD命令分別把數據寫入Hash和Sorted Set),這些命令操作要么全部完成,要么都不完成。
只有保證了寫操作的原子性,才能保證同一個時間序列數據,在Hash和Sorted Set中,要么都保存了,要么都沒保存。否則,就可能出現Hash集合中有時間序列數據,而Sorted Set中沒有,那么,在進行范圍查詢時,就沒有辦法滿足查詢需求了。
那Redis是怎么保證原子性操作的呢?這里就涉及到了Redis用來實現簡單的事務的MULTI和EXEC命令。當多個命令及其參數本身無誤時,MULTI和EXEC命令可以保證執行這些命令時的原子性。關于Redis的事務支持和原子性保證的異常情況,我會在第30講中向你介紹,這節課,我們只要了解一下MULTI和EXEC這兩個命令的使用方法就行了。
MULTI命令:表示一系列原子性操作的開始。收到這個命令后,Redis就知道,接下來再收到的命令需要放到一個內部隊列中,后續一起執行,保證原子性。
EXEC命令:表示一系列原子性操作的結束。一旦Redis收到了這個命令,就表示所有要保證原子性的命令操作都已經發送完成了。此時,Redis開始執行剛才放到內部隊列中的所有命令操作。
你可以看下下面這張示意圖,命令1到命令N是在MULTI命令后、EXEC命令前發送的,它們會被一起執行,保證原子性。

以保存設備狀態信息的需求為例,我們執行下面的代碼,把設備在2020年8月3日9時5分的溫度,分別用HSET命令和ZADD命令寫入Hash集合和Sorted Set集合。
127.0.0.1:6379> MULTI OK 127.0.0.1:6379> HSET device:temperature 202008030911 26.8 QUEUED 127.0.0.1:6379> ZADD device:temperature 202008030911 26.8 QUEUED 127.0.0.1:6379> EXEC 1) (integer) 1 2) (integer) 1
可以看到,首先,Redis收到了客戶端執行的MULTI命令。然后,客戶端再執行HSET和ZADD命令后,Redis返回的結果為“QUEUED”,表示這兩個命令暫時入隊,先不執行;執行了EXEC命令后,HSET命令和ZADD命令才真正執行,并返回成功結果(結果值為1)。
到這里,我們就解決了時間序列數據的單點查詢、范圍查詢問題,并使用MUTLI和EXEC命令保證了Redis能原子性地把數據保存到Hash和Sorted Set中。接下來,我們需要繼續解決第三個問題:如何對時間序列數據進行聚合計算?
聚合計算一般被用來周期性地統計時間窗口內的數據匯總狀態,在實時監控與預警等場景下會頻繁執行。
因為Sorted Set只支持范圍查詢,無法直接進行聚合計算,所以,我們只能先把時間范圍內的數據取回到客戶端,然后在客戶端自行完成聚合計算。這個方法雖然能完成聚合計算,但是會帶來一定的潛在風險,也就是大量數據在Redis實例和客戶端間頻繁傳輸,這會和其他操作命令競爭網絡資源,導致其他操作變慢。
在我們這個物聯網項目中,就需要每3分鐘統計一下各個設備的溫度狀態,一旦設備溫度超出了設定的閾值,就要進行報警。這是一個典型的聚合計算場景,我們可以來看看這個過程中的數據體量。
假設我們需要每3分鐘計算一次的所有設備各指標的最大值,每個設備每15秒記錄一個指標值,1分鐘就會記錄4個值,3分鐘就會有12個值。我們要統計的設備指標數量有33個,所以,單個設備每3分鐘記錄的指標數據有將近400個(33 * 12 = 396),而設備總數量有1萬臺,這樣一來,每3分鐘就有將近400萬條(396 * 1萬 = 396萬)數據需要在客戶端和Redis實例間進行傳輸。
為了避免客戶端和Redis實例間頻繁的大量數據傳輸,我們可以使用RedisTimeSeries來保存時間序列數據。
RedisTimeSeries支持直接在Redis實例上進行聚合計算。還是以剛才每3分鐘算一次最大值為例。在Redis實例上直接聚合計算,那么,對于單個設備的一個指標值來說,每3分鐘記錄的12條數據可以聚合計算成一個值,單個設備每3分鐘也就只有33個聚合值需要傳輸,1萬臺設備也只有33萬條數據。數據量大約是在客戶端做聚合計算的十分之一,很顯然,可以減少大量數據傳輸對Redis實例網絡的性能影響。
所以,如果我們只需要進行單個時間點查詢或是對某個時間范圍查詢的話,適合使用Hash和Sorted Set的組合,它們都是Redis的內在數據結構,性能好,穩定性高。但是,如果我們需要進行大量的聚合計算,同時網絡帶寬條件不是太好時,Hash和Sorted Set的組合就不太適合了。此時,使用RedisTimeSeries就更加合適一些。
好了,接下來,我們就來具體學習下RedisTimeSeries。
RedisTimeSeries是Redis的一個擴展模塊。它專門面向時間序列數據提供了數據類型和訪問接口,并且支持在Redis實例上直接對數據進行按時間范圍的聚合計算。
因為RedisTimeSeries不屬于Redis的內建功能模塊,在使用時,我們需要先把它的源碼單獨編譯成動態鏈接庫redistimeseries.so,再使用loadmodule命令進行加載,如下所示:
loadmodule redistimeseries.so
當用于時間序列數據存取時,RedisTimeSeries的操作主要有5個:
用TS.CREATE命令創建時間序列數據集合;
用TS.ADD命令插入數據;
用TS.GET命令讀取最新數據;
用TS.MGET命令按標簽過濾查詢數據集合;
用TS.RANGE支持聚合計算的范圍查詢。
下面,我來介紹一下如何使用這5個操作。
在TS.CREATE命令中,我們需要設置時間序列數據集合的key和數據的過期時間(以毫秒為單位)。此外,我們還可以為數據集合設置標簽,來表示數據集合的屬性。
例如,我們執行下面的命令,創建一個key為device:temperature、數據有效期為600s的時間序列數據集合。也就是說,這個集合中的數據創建了600s后,就會被自動刪除。最后,我們給這個集合設置了一個標簽屬性{device_id:1},表明這個數據集合中記錄的是屬于設備ID號為1的數據。
TS.CREATE device:temperature RETENTION 600000 LABELS device_id 1 OK
我們可以用TS.ADD命令往時間序列集合中插入數據,包括時間戳和具體的數值,并使用TS.GET命令讀取數據集合中的最新一條數據。
例如,我們執行下列TS.ADD命令時,就往device:temperature集合中插入了一條數據,記錄的是設備在2020年8月3日9時5分的設備溫度;再執行TS.GET命令時,就會把剛剛插入的最新數據讀取出來。
TS.ADD device:temperature 1596416700 25.1 1596416700 TS.GET device:temperature 25.1
在保存多個設備的時間序列數據時,我們通常會把不同設備的數據保存到不同集合中。此時,我們就可以使用TS.MGET命令,按照標簽查詢部分集合中的最新數據。在使用TS.CREATE創建數據集合時,我們可以給集合設置標簽屬性。當我們進行查詢時,就可以在查詢條件中對集合標簽屬性進行匹配,最后的查詢結果里只返回匹配上的集合中的最新數據。
舉個例子。假設我們一共用4個集合為4個設備保存時間序列數據,設備的ID號是1、2、3、4,我們在創建數據集合時,把device_id設置為每個集合的標簽。此時,我們就可以使用下列TS.MGET命令,以及FILTER設置(這個配置項用來設置集合標簽的過濾條件),查詢device_id不等于2的所有其他設備的數據集合,并返回各自集合中的最新的一條數據。
TS.MGET FILTER device_id!=2 1) 1) "device:temperature:1" 2) (empty list or set) 3) 1) (integer) 1596417000 2) "25.3" 2) 1) "device:temperature:3" 2) (empty list or set) 3) 1) (integer) 1596417000 2) "29.5" 3) 1) "device:temperature:4" 2) (empty list or set) 3) 1) (integer) 1596417000 2) "30.1"
最后,在對時間序列數據進行聚合計算時,我們可以使用TS.RANGE命令指定要查詢的數據的時間范圍,同時用AGGREGATION參數指定要執行的聚合計算類型。RedisTimeSeries支持的聚合計算類型很豐富,包括求均值(avg)、求最大/最小值(max/min),求和(sum)等。
例如,在執行下列命令時,我們就可以按照每180s的時間窗口,對2020年8月3日9時5分和2020年8月3日9時12分這段時間內的數據進行均值計算了。
TS.RANGE device:temperature 1596416700 1596417120 AGGREGATION avg 180000 1) 1) (integer) 1596416700 2) "25.6" 2) 1) (integer) 1596416880 2) "25.8" 3) 1) (integer) 1596417060 2) "26.1"
與使用Hash和Sorted Set來保存時間序列數據相比,RedisTimeSeries是專門為時間序列數據訪問設計的擴展模塊,能支持在Redis實例上直接進行聚合計算,以及按標簽屬性過濾查詢數據集合,當我們需要頻繁進行聚合計算,以及從大量集合中篩選出特定設備或用戶的數據集合時,RedisTimeSeries就可以發揮優勢了。
在這節課,我們一起學習了如何用Redis保存時間序列數據。時間序列數據的寫入特點是要能快速寫入,而查詢的特點有三個:
點查詢,根據一個時間戳,查詢相應時間的數據;
范圍查詢,查詢起始和截止時間戳范圍內的數據;
聚合計算,針對起始和截止時間戳范圍內的所有數據進行計算,例如求最大/最小值,求均值等。
關于快速寫入的要求,Redis的高性能寫特性足以應對了;而針對多樣化的查詢需求,Redis提供了兩種方案。
第一種方案是,組合使用Redis內置的Hash和Sorted Set類型,把數據同時保存在Hash集合和Sorted Set集合中。這種方案既可以利用Hash類型實現對單鍵的快速查詢,還能利用Sorted Set實現對范圍查詢的高效支持,一下子滿足了時間序列數據的兩大查詢需求。
不過,第一種方案也有兩個不足:一個是,在執行聚合計算時,我們需要把數據讀取到客戶端再進行聚合,當有大量數據要聚合時,數據傳輸開銷大;另一個是,所有的數據會在兩個數據類型中各保存一份,內存開銷不小。不過,我們可以通過設置適當的數據過期時間,釋放內存,減小內存壓力。
我們學習的第二種實現方案是使用RedisTimeSeries模塊。這是專門為存取時間序列數據而設計的擴展模塊。和第一種方案相比,RedisTimeSeries能支持直接在Redis實例上進行多種數據聚合計算,避免了大量數據在實例和客戶端間傳輸。不過,RedisTimeSeries的底層數據結構使用了鏈表,它的范圍查詢的復雜度是O(N)級別的,同時,它的TS.GET查詢只能返回最新的數據,沒有辦法像第一種方案的Hash類型一樣,可以返回任一時間點的數據。
所以,組合使用Hash和Sorted Set,或者使用RedisTimeSeries,在支持時間序列數據存取上各有優劣勢。我給你的建議是:
如果你的部署環境中網絡帶寬高、Redis實例內存大,可以優先考慮第一種方案;
如果你的部署環境中網絡、內存資源有限,而且數據量大,聚合計算頻繁,需要按數據集合屬性查詢,可以優先考慮第二種方案。
“在Redis中怎么保存時間序列數據”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





