溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Vue.js實用的性能優化技巧分享”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Vue.js實用的性能優化技巧分享”吧!
Functional components
Child component splitting
Local variables
Reuse DOM with v-show
KeepAlive
Deferred features
Time slicing
Non-reactive data
Virtual scrolling
第一個技巧,函數式組件,你可以查看這個在線示例
優化前的組件代碼如下:
<template>
<div class="cell">
<div v-if="value" class="on"></div>
<section v-else class="off"></section>
</div>
</template>
<script>
export default {
props: ['value'],
}
</script>優化后的組件代碼如下:
<template functional> <div class="cell"> <div v-if="props.value" class="on"></div> <section v-else class="off"></section> </div> </template>
然后我們在父組件各渲染優化前后的組件 800 個,并在每一幀內部通過修改數據來觸發組件的更新,開啟 Chrome 的 Performance 面板記錄它們的性能,得到如下結果。
優化前:

優化后:
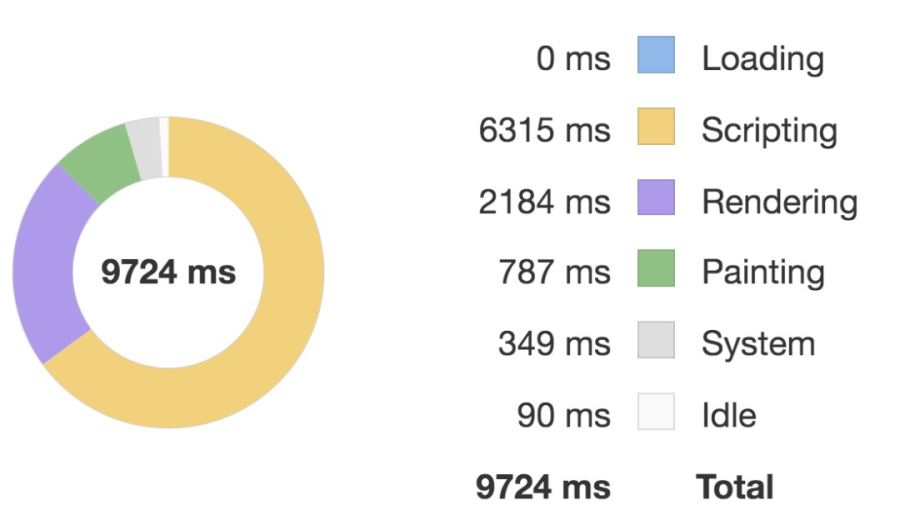
對比這兩張圖我們可以看到優化前執行 script 的時間要多于優化后的,而我們知道 JS 引擎是單線程的運行機制,JS 線程會阻塞 UI 線程,所以當腳本執行時間過長,就會阻塞渲染,導致頁面卡頓。而優化后的 script 執行時間短,所以它的性能更好。
那么,為什么用函數式組件 JS 的執行時間就變短了呢?這要從函數式組件的實現原理說起了,你可以把它理解成一個函數,它可以根據你傳遞的上下文數據渲染生成一片 DOM。
函數式組件和普通的對象類型的組件不同,它不會被看作成一個真正的組件,我們知道在 patch 過程中,如果遇到一個節點是組件 vnode,會遞歸執行子組件的初始化過程;而函數式組件的 render 生成的是普通的 vnode,不會有遞歸子組件的過程,因此渲染開銷會低很多。
因此,函數式組件也不會有狀態,不會有響應式數據,生命周期鉤子函數這些東西。你可以把它當成把普通組件模板中的一部分 DOM 剝離出來,通過函數的方式渲染出來,是一種在 DOM 層面的復用。
第二個技巧,子組件拆分,你可以查看這個在線示例。
優化前的組件代碼如下:
<template>
<div :>
<div>{{ heavy() }}</div>
</div>
</template>
<script>
export default {
props: ['number'],
methods: {
heavy () {
const n = 100000
let result = 0
for (let i = 0; i < n; i++) {
result += Math.sqrt(Math.cos(Math.sin(42)))
}
return result
}
}
}
</script>優化后的組件代碼如下:
<template>
<div :>
<ChildComp/>
</div>
</template>
<script>
export default {
components: {
ChildComp: {
methods: {
heavy () {
const n = 100000
let result = 0
for (let i = 0; i < n; i++) {
result += Math.sqrt(Math.cos(Math.sin(42)))
}
return result
},
},
render (h) {
return h('div', this.heavy())
}
}
},
props: ['number']
}
</script>然后我們在父組件各渲染優化前后的組件 300 個,并在每一幀內部通過修改數據來觸發組件的更新,開啟 Chrome 的 Performance 面板記錄它們的性能,得到如下結果。
優化前:
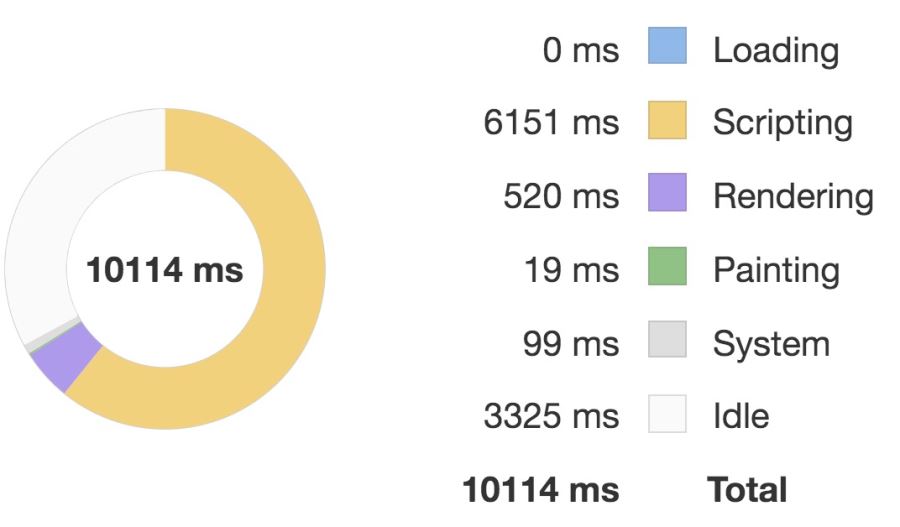
優化后:
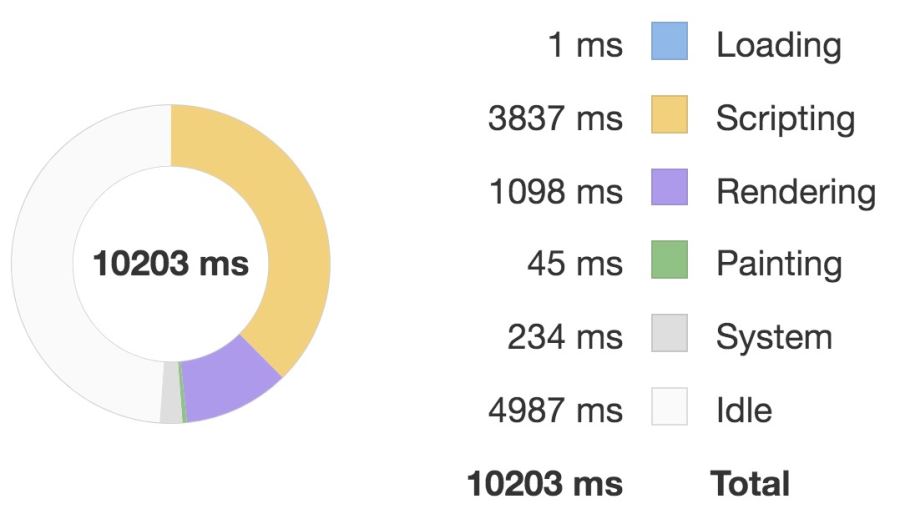
對比這兩張圖我們可以看到優化后執行 script 的時間要明顯少于優化前的,因此性能體驗更好。
那么為什么會有差異呢,我們來看優化前的組件,示例通過一個 heavy 函數模擬了一個耗時的任務,且這個函數在每次渲染的時候都會執行一次,所以每次組件的渲染都會消耗較長的時間執行 JavaScript。
而優化后的方式是把這個耗時任務 heavy 函數的執行邏輯用子組件 ChildComp 封裝了,由于 Vue 的更新是組件粒度的,雖然每一幀都通過數據修改導致了父組件的重新渲染,但是 ChildComp 卻不會重新渲染,因為它的內部也沒有任何響應式數據的變化。所以優化后的組件不會在每次渲染都執行耗時任務,自然執行的 JavaScript 時間就變少了。
不過針對這個優化的方式我提出了一些不同的看法,詳情可以點開這個 issue,我認為這個場景下的優化用計算屬性要比子組件拆分要好。得益于計算屬性自身緩存特性,耗時的邏輯也只會在第一次渲染的時候執行,而且使用計算屬性也沒有額外渲染子組件的開銷。
在實際工作中,使用計算屬性是優化性能的場景會有很多,畢竟它也體現了一種空間換時間的優化思想。
第三個技巧,局部變量,你可以查看這個在線示例。
優化前的組件代碼如下:
<template>
<div :>{{ result }}</div>
</template>
<script>
export default {
props: ['start'],
computed: {
base () {
return 42
},
result () {
let result = this.start
for (let i = 0; i < 1000; i++) {
result += Math.sqrt(Math.cos(Math.sin(this.base))) + this.base * this.base + this.base + this.base * 2 + this.base * 3
}
return result
},
},
}
</script>優化后的組件代碼如下:
<template>
<div :>{{ result }}</div>
</template>
<script>
export default {
props: ['start'],
computed: {
base () {
return 42
},
result ({ base, start }) {
let result = start
for (let i = 0; i < 1000; i++) {
result += Math.sqrt(Math.cos(Math.sin(base))) + base * base + base + base * 2 + base * 3
}
return result
},
},
}
</script>然后我們在父組件各渲染優化前后的組件 300 個,并在每一幀內部通過修改數據來觸發組件的更新,開啟 Chrome 的 Performance 面板記錄它們的性能,得到如下結果。
優化前:
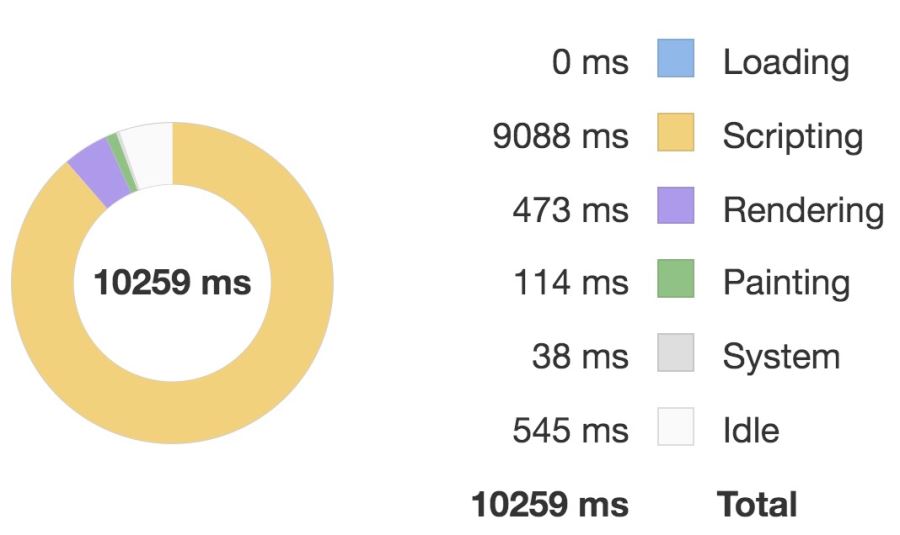
優化后:
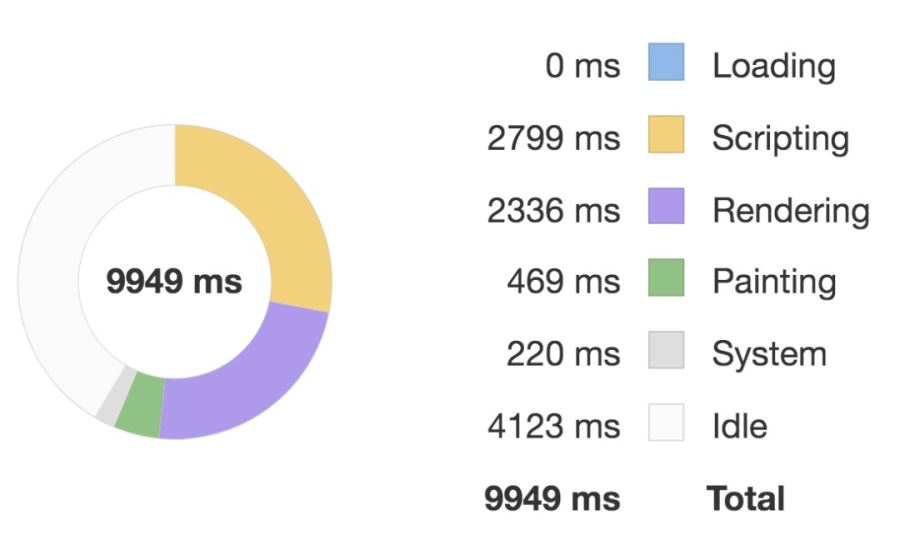
對比這兩張圖我們可以看到優化后執行 script 的時間要明顯少于優化前的,因此性能體驗更好。
這里主要是優化前后組件的計算屬性 result 的實現差異,優化前的組件多次在計算過程中訪問 this.base,而優化后的組件會在計算前先用局部變量 base 緩存 this.base,后面則直接訪問 base變量。
那么為啥這個差異會造成性能上的差異呢,原因是你每次訪問 this.base 的時候,由于 this.base 是一個響應式對象,所以會觸發它的 getter,進而會執行依賴收集相關邏輯代碼。類似的邏輯執行多了,像示例這樣,幾百次循環更新幾百個組件,每個組件觸發 computed 重新計算,然后又多次執行依賴收集相關邏輯,性能自然就下降了。
從需求上來說,this.base 執行一次依賴收集就夠了,因此我們只需要把它的 getter 求值結果返回給局部變量 base,后續再次訪問 base 的時候就不會觸發 getter,也不會走依賴收集的邏輯了,性能自然就得到了提升。
這是一個非常實用的性能優化技巧。因為很多人在開發 Vue.js 項目的時候,每當取變量的時候就習慣性直接寫 this.xxx 了,因為大部分人并不會注意到訪問 this.xxx 背后做的事情。在訪問次數不多的時候,性能問題并沒有凸顯,但是一旦訪問次數變多,比如在一個大循環中多次訪問,類似示例這種場景,就會產生性能問題了。
我之前給 ZoomUI 的 Table 組件做性能優化的時候,在 render table body 的時候就使用了局部變量的優化技巧,并寫了 benchmark 做性能對比:渲染 1000 * 10 的表格,ZoomUI Table 的更新數據重新渲染的性能要比 ElementUI 的 Table 性能提升了近一倍。
第四個技巧,使用 v-show 復用 DOM,你可以查看這個在線示例。
優化前的組件代碼如下:
<template functional> <div class="cell"> <div v-if="props.value" class="on"> <Heavy :n="10000"/> </div> <section v-else class="off"> <Heavy :n="10000"/> </section> </div> </template>
優化后的組件代碼如下:
<template functional> <div class="cell"> <div v-show="props.value" class="on"> <Heavy :n="10000"/> </div> <section v-show="!props.value" class="off"> <Heavy :n="10000"/> </section> </div> </template>
然后我們在父組件各渲染優化前后的組件 200 個,并在每一幀內部通過修改數據來觸發組件的更新,開啟 Chrome 的 Performance 面板記錄它們的性能,得到如下結果。
優化前:
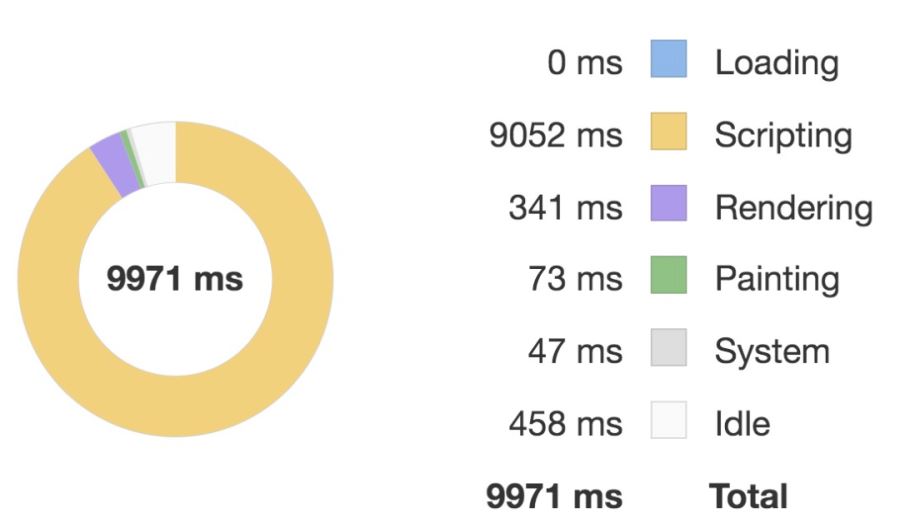
優化后:
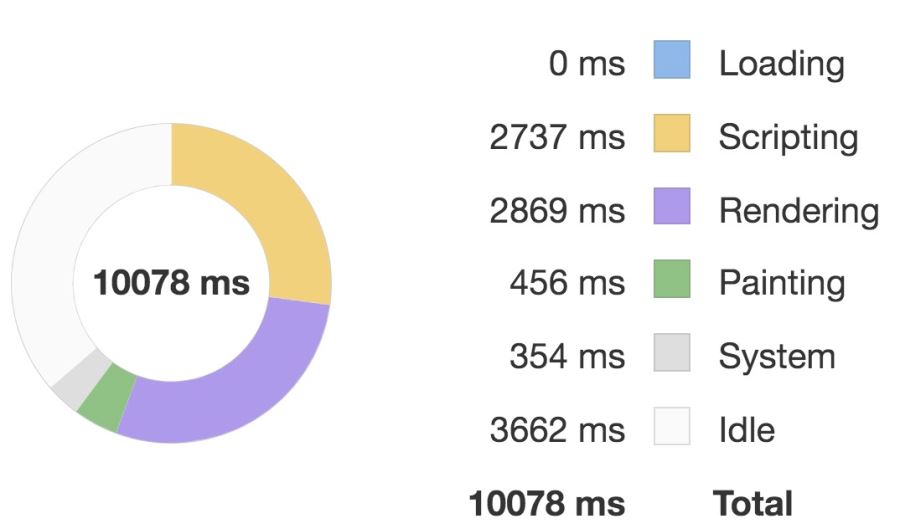
對比這兩張圖我們可以看到優化后執行 script 的時間要明顯少于優化前的,因此性能體驗更好。
優化前后的主要區別是用 v-show 指令替代了 v-if 指令來替代組件的顯隱,雖然從表現上看,v-show 和 v-if 類似,都是控制組件的顯隱,但內部實現差距還是很大的。
v-if 指令在編譯階段就會編譯成一個三元運算符,條件渲染,比如優化前的組件模板經過編譯后生成如下渲染函數:
function render() {
with(this) {
return _c('div', {
staticClass: "cell"
}, [(props.value) ? _c('div', {
staticClass: "on"
}, [_c('Heavy', {
attrs: {
"n": 10000
}
})], 1) : _c('section', {
staticClass: "off"
}, [_c('Heavy', {
attrs: {
"n": 10000
}
})], 1)])
}
}當條件 props.value 的值變化的時候,會觸發對應的組件更新,對于 v-if 渲染的節點,由于新舊節點 vnode 不一致,在核心 diff 算法比對過程中,會移除舊的 vnode 節點,創建新的 vnode 節點,那么就會創建新的 Heavy 組件,又會經歷 Heavy 組件自身初始化、渲染 vnode、patch 等過程。
因此使用 v-if 每次更新組件都會創建新的 Heavy 子組件,當更新的組件多了,自然就會造成性能壓力。
而當我們使用 v-show 指令,優化后的組件模板經過編譯后生成如下渲染函數:
function render() {
with(this) {
return _c('div', {
staticClass: "cell"
}, [_c('div', {
directives: [{
name: "show",
rawName: "v-show",
value: (props.value),
expression: "props.value"
}],
staticClass: "on"
}, [_c('Heavy', {
attrs: {
"n": 10000
}
})], 1), _c('section', {
directives: [{
name: "show",
rawName: "v-show",
value: (!props.value),
expression: "!props.value"
}],
staticClass: "off"
}, [_c('Heavy', {
attrs: {
"n": 10000
}
})], 1)])
}
}當條件 props.value 的值變化的時候,會觸發對應的組件更新,對于 v-show 渲染的節點,由于新舊 vnode 一致,它們只需要一直 patchVnode 即可,那么它又是怎么讓 DOM 節點顯示和隱藏的呢?
原來在 patchVnode 過程中,內部會對執行 v-show 指令對應的鉤子函數 update,然后它會根據 v-show 指令綁定的值來設置它作用的 DOM 元素的 style.display 的值控制顯隱。
因此相比于 v-if 不斷刪除和創建函數新的 DOM,v-show 僅僅是在更新現有 DOM 的顯隱值,所以 v-show 的開銷要比 v-if 小的多,當其內部 DOM 結構越復雜,性能的差異就會越大。
但是 v-show 相比于 v-if 的性能優勢是在組件的更新階段,如果僅僅是在初始化階段,v-if 性能還要高于 v-show,原因是在于它僅僅會渲染一個分支,而 v-show 把兩個分支都渲染了,通過 style.display 來控制對應 DOM 的顯隱。
在使用 v-show 的時候,所有分支內部的組件都會渲染,對應的生命周期鉤子函數都會執行,而使用 v-if 的時候,沒有命中的分支內部的組件是不會渲染的,對應的生命周期鉤子函數都不會執行。
因此你要搞清楚它們的原理以及差異,才能在不同的場景使用適合的指令。
第五個技巧,使用 KeepAlive 組件緩存 DOM,你可以查看這個在線示例。
優化前的組件代碼如下:
<template> <div id="app"> <router-view/> </div> </template>
優化后的組件代碼如下:
<template> <div id="app"> <keep-alive> <router-view/> </keep-alive> </div> </template>
我們點擊按鈕在 Simple page 和 Heavy Page 之間切換,會渲染不同的視圖,其中 Heavy Page 的渲染非常耗時。我們開啟 Chrome 的 Performance 面板記錄它們的性能,然后分別在優化前后執行如上的操作,會得到如下結果。
優化前:
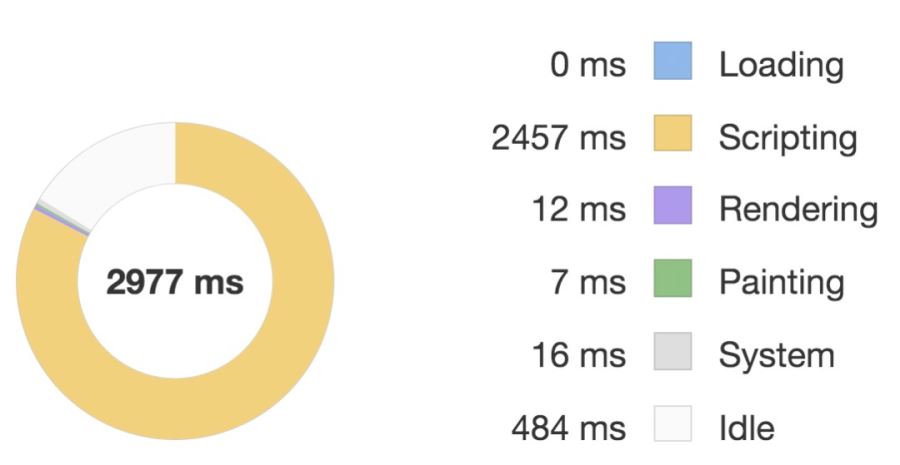

優化后:
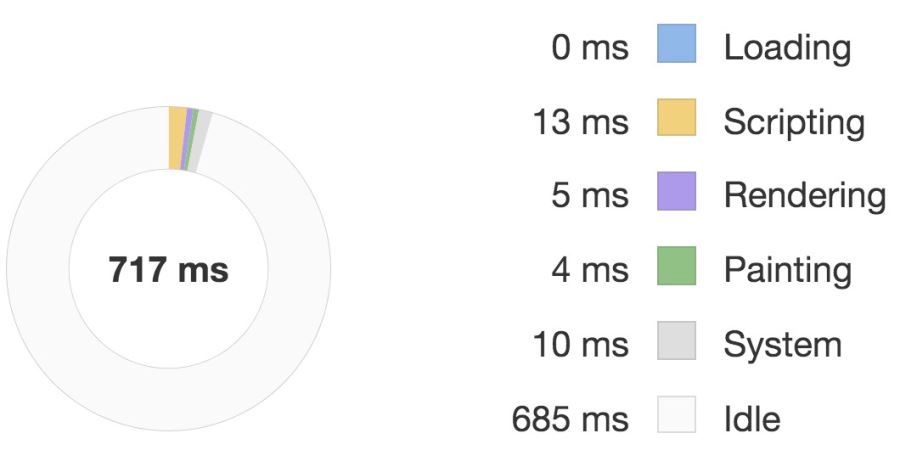
對比這兩張圖我們可以看到優化后執行 script 的時間要明顯少于優化前的,因此性能體驗更好。
在非優化場景下,我們每次點擊按鈕切換路由視圖,都會重新渲染一次組件,渲染組件就會經過組件初始化,render、patch 等過程,如果組件比較復雜,或者嵌套較深,那么整個渲染耗時就會很長。
而在使用 KeepAlive 后,被 KeepAlive 包裹的組件在經過第一次渲染后,的 vnode 以及 DOM 都會被緩存起來,然后再下一次再次渲染該組件的時候,直接從緩存中拿到對應的 vnode 和 DOM,然后渲染,并不需要再走一次組件初始化,render 和 patch 等一系列流程,減少了 script 的執行時間,性能更好。
但是使用 KeepAlive 組件并非沒有成本,因為它會占用更多的內存去做緩存,這是一種典型的空間換時間優化思想的應用。
第六個技巧,使用 Deferred 組件延時分批渲染組件,你可以查看這個在線示例。
優化前的組件代碼如下:
<template> <div class="deferred-off"> <VueIcon icon="fitness_center" class="gigantic"/> <h3>I'm an heavy page</h3> <Heavy v-for="n in 8" :key="n"/> <Heavy class="super-heavy" :n="9999999"/> </div> </template>
優化后的組件代碼如下:
<template>
<div class="deferred-on">
<VueIcon icon="fitness_center" class="gigantic"/>
<h3>I'm an heavy page</h3>
<template v-if="defer(2)">
<Heavy v-for="n in 8" :key="n"/>
</template>
<Heavy v-if="defer(3)" class="super-heavy" :n="9999999"/>
</div>
</template>
<script>
import Defer from '@/mixins/Defer'
export default {
mixins: [
Defer(),
],
}
</script>我們點擊按鈕在 Simple page 和 Heavy Page 之間切換,會渲染不同的視圖,其中 Heavy Page 的渲染非常耗時。我們開啟 Chrome 的 Performance 面板記錄它們的性能,然后分別在優化前后執行如上的操作,會得到如下結果。
優化前:
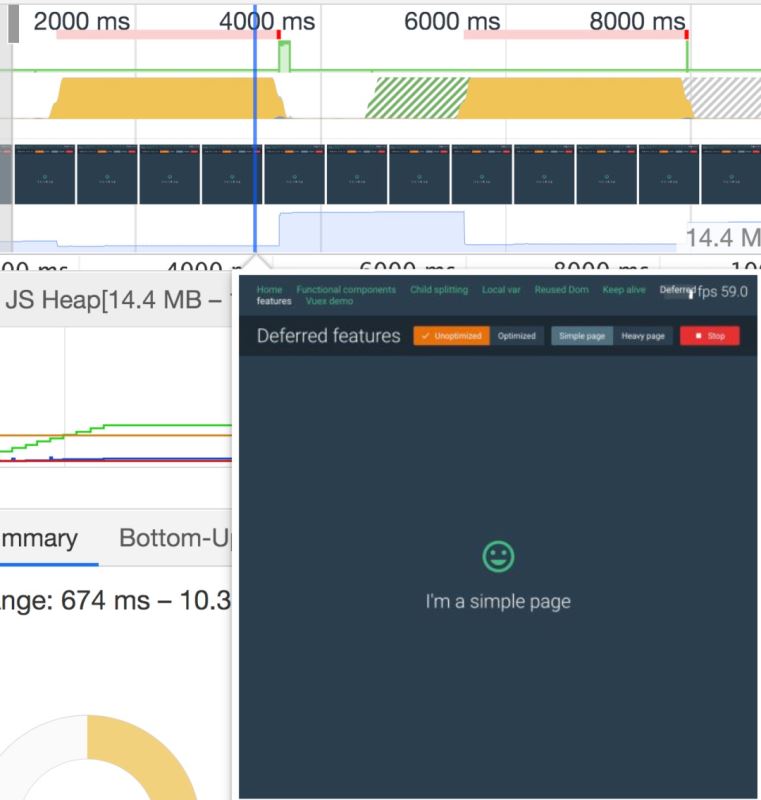
優化后:
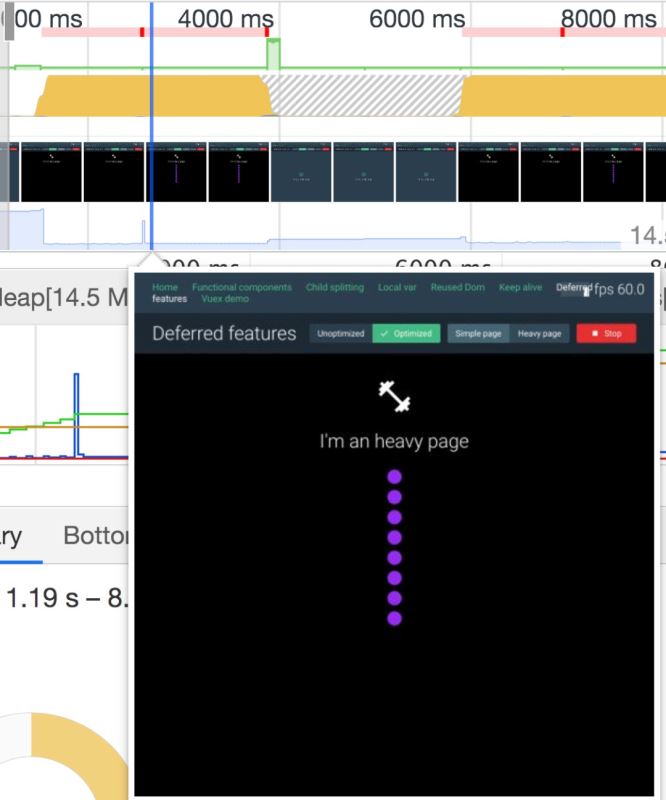
對比這兩張圖我們可以發現,優化前當我們從 Simple Page 切到 Heavy Page 的時候,在一次 Render 接近結尾的時候,頁面渲染的仍然是 Simple Page,會給人一種頁面卡頓的感覺。而優化后當我們從 Simple Page 切到 Heavy Page 的時候,在一次 Render 靠前的位置頁面就已經渲染了 Heavy Page 了,并且 Heavy Page 是漸進式渲染出來的。
優化前后的差距主要是后者使用了 Defer 這個 mixin,那么它具體是怎么工作的,我們來一探究竟:
export default function (count = 10) {
return {
data () {
return {
displayPriority: 0
}
},
mounted () {
this.runDisplayPriority()
},
methods: {
runDisplayPriority () {
const step = () => {
requestAnimationFrame(() => {
this.displayPriority++
if (this.displayPriority < count) {
step()
}
})
}
step()
},
defer (priority) {
return this.displayPriority >= priority
}
}
}
}Defer 的主要思想就是把一個組件的一次渲染拆成多次,它內部維護了 displayPriority 變量,然后在通過 requestAnimationFrame 在每一幀渲染的時候自增,最多加到 count。然后使用 Defer mixin 的組件內部就可以通過 v-if="defer(xxx)" 的方式來控制在 displayPriority 增加到 xxx 的時候渲染某些區塊了。
當你有渲染耗時的組件,使用 Deferred 做漸進式渲染是不錯的注意,它能避免一次 render 由于 JS 執行時間過長導致渲染卡住的現象。
第七個技巧,使用 Time slicing 時間片切割技術,你可以查看這個在線示例。
優化前的代碼如下:
fetchItems ({ commit }, { items }) {
commit('clearItems')
commit('addItems', items)
}優化后的代碼如下:
fetchItems ({ commit }, { items, splitCount }) {
commit('clearItems')
const queue = new JobQueue()
splitArray(items, splitCount).forEach(
chunk => queue.addJob(done => {
// 分時間片提交數據
requestAnimationFrame(() => {
commit('addItems', chunk)
done()
})
})
)
await queue.start()
}我們先通過點擊 Genterate items 按鈕創建 10000 條假數據,然后分別在開啟和關閉 Time-slicing 的情況下點擊 Commit items 按鈕提交數據,開啟 Chrome 的 Performance 面板記錄它們的性能,會得到如下結果。
優化前:
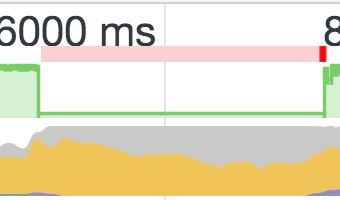
優化后:

對比這兩張圖我們可以發現,優化前總的 script 執行時間要比優化后的還要少一些,但是從實際的觀感上看,優化前點擊提交按鈕,頁面會卡死 1.2 秒左右,在優化后,頁面不會完全卡死,但仍然會有渲染卡頓的感覺。
那么為什么在優化前頁面會卡死呢?因為一次性提交的數據過多,內部 JS 執行時間過長,阻塞了 UI 線程,導致頁面卡死。
優化后,頁面仍有卡頓,是因為我們拆分數據的粒度是 1000 條,這種情況下,重新渲染組件仍然有壓力,我們觀察 fps 只有十幾,會有卡頓感。通常只要讓頁面的 fps 達到 60,頁面就會非常流暢,如果我們把數據拆分粒度變成 100 條,基本上 fps 能達到 50 以上,雖然頁面渲染變流暢了,但是完成 10000 條數據總的提交時間還是變長了。
使用 Time slicing技術可以避免頁面卡死,通常我們在這種耗時任務處理的時候會加一個 loading 效果,在這個示例中,我們可以開啟 loading animation,然后提交數據。對比發現,優化前由于一次性提交數據過多,JS 一直長時間運行,阻塞 UI 線程,這個 loading 動畫是不會展示的,而優化后,由于我們拆成多個時間片去提交數據,單次 JS 運行時間變短了,這樣 loading 動畫就有機會展示了。
這里要注意的一點,雖然我們拆時間片使用了
requestAnimationFrameAPI,但是使用requestAnimationFrame本身是不能保證滿幀運行的,requestAnimationFrame保證的是在瀏覽器每一次重繪后會執行對應傳入的回調函數,想要保證滿幀,只能讓 JS 在一個 Tick 內的運行時間不超過 17ms。
第八個技巧,使用 Non-reactive data ,你可以查看這個在線示例。
優化前代碼如下:
const data = items.map(
item => ({
id: uid++,
data: item,
vote: 0
})
)優化后代碼如下:
const data = items.map(
item => optimizeItem(item)
)
function optimizeItem (item) {
const itemData = {
id: uid++,
vote: 0
}
Object.defineProperty(itemData, 'data', {
// Mark as non-reactive
configurable: false,
value: item
})
return itemData
}還是前面的示例,我們先通過點擊 Genterate items 按鈕創建 10000 條假數據,然后分別在開啟和關閉 Partial reactivity 的情況下點擊 Commit items 按鈕提交數據,開啟 Chrome 的 Performance 面板記錄它們的性能,會得到如下結果。
優化前:

優化后:
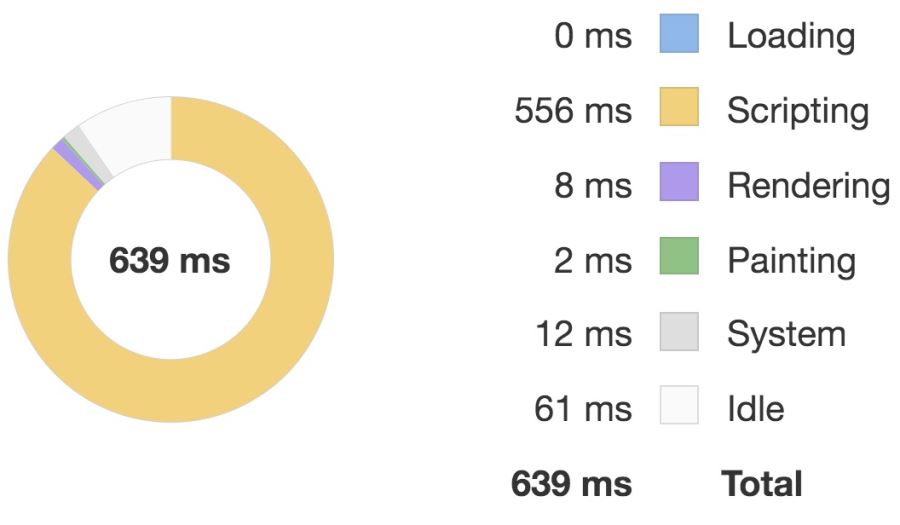
對比這兩張圖我們可以看到優化后執行 script 的時間要明顯少于優化前的,因此性能體驗更好。
之所以有這種差異,是因為內部提交的數據的時候,會默認把新提交的數據也定義成響應式,如果數據的子屬性是對象形式,還會遞歸讓子屬性也變成響應式,因此當提交數據很多的時候,這個過程就變成了一個耗時過程。
而優化后我們把新提交的數據中的對象屬性 data 手動變成了 configurable 為 false,這樣內部在 walk 時通過 Object.keys(obj) 獲取對象屬性數組會忽略 data,也就不會為 data 這個屬性 defineReactive,由于 data 指向的是一個對象,這樣也就會減少遞歸響應式的邏輯,相當于減少了這部分的性能損耗。數據量越大,這種優化的效果就會更明顯。
其實類似這種優化的方式還有很多,比如我們在組件中定義的一些數據,也不一定都要在 data 中定義。有些數據我們并不是用在模板中,也不需要監聽它的變化,只是想在組件的上下文中共享這個數據,這個時候我們可以僅僅把這個數據掛載到組件實例 this 上,例如:
export default {
created() {
this.scroll = null
},
mounted() {
this.scroll = new BScroll(this.$el)
}
}這樣我們就可以在組件上下文中共享 scroll 對象了,即使它不是一個響應式對象。
第九個技巧,使用 Virtual scrolling ,你可以查看這個在線示例。
優化前組件的代碼如下:
<div class="items no-v"> <FetchItemViewFunctional v-for="item of items" :key="item.id" :item="item" @vote="voteItem(item)" /> </div>
優化后代碼如下:
<recycle-scroller
class="items"
:items="items"
:item-size="24"
>
<template v-slot="{ item }">
<FetchItemView
:item="item"
@vote="voteItem(item)"
/>
</template>
</recycle-scroller>還是前面的示例,我們需要開啟 View list,然后點擊 Genterate items 按鈕創建 10000 條假數據(注意,線上示例最多只能創建 1000 條數據,實際上 1000 條數據并不能很好地體現優化的效果,所以我修改了源碼的限制,本地運行,創建了 10000 條數據),然后分別在 Unoptimized 和 RecycleScroller 的情況下點擊 Commit items 按鈕提交數據,滾動頁面,開啟 Chrome 的 Performance 面板記錄它們的性能,會得到如下結果。
優化前:

優化后:
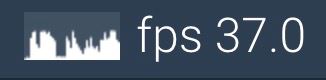
對比這兩張圖我們發現,在非優化的情況下,10000 條數據在滾動情況下 fps 只有個位數,在非滾動情況下也就十幾,原因是非優化場景下渲染的 DOM 太多,渲染本身的壓力很大。優化后,即使 10000 條數據,在滾動情況下的 fps 也能有 30 多,在非滾動情況下可以達到 60 滿幀。
之所以有這個差異,是因為虛擬滾動的實現方式:是只渲染視口內的 DOM。這樣總共渲染的 DOM 數量就很少了,自然性能就會好很多。
虛擬滾動組件也是 Guillaume Chau 寫的,感興趣的同學可以去研究它的源碼實現。它的基本原理就是監聽滾動事件,動態更新需要顯示的 DOM 元素,計算出它們在視圖中的位移。
虛擬滾動組件也并非沒有成本,因為它需要在滾動的過程中實時去計算,所以會有一定的 script 執行的成本。因此如果列表的數據量不是很大的情況,我們使用普通的滾動就足夠了。
到此,相信大家對“Vue.js實用的性能優化技巧分享”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





