溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“人工智能中遷移的定義和使用方法”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
隨著越來越多的機器學習應用場景的出現,而現有表現比較好的監督學習需要大量的標注數據,標注數據是一項枯燥無味且花費巨大的任務,所以遷移學習受到越來越多的關注。
傳統機器學習(主要指監督學習)
基于同分布假設
需要大量標注數據
然而實際使用過程中不同數據集可能存在一些問題,比如
數據分布差異
標注數據過期:訓練數據過期,也就是好不容易標定的數據要被丟棄,有些應用中數據是分布隨著時間推移會有變化
如何充分利用之前標注好的數據(廢物利用),同時又保證在新的任務上的模型精度?
基于這樣的問題,所以就有了對于遷移學習的研究

Transfer Learning Definition:
Ability of a system to recognize and apply knowledge and skills learned in previous domains/tasks to novel domains/tasks.
將某個領域或任務上學習到的知識或模式應用到不同但相關的領域或問題中。
從相關領域中遷移標注數據或者知識結構、完成或改進目標領域或任務的學習效果。
人在實際生活中有很多遷移學習,比如學會騎自行車,就比較容易學摩托車,學會了C語言,在學一些其它編程語言會簡單很多。那么機器是否能夠像人類一樣舉一反三呢?
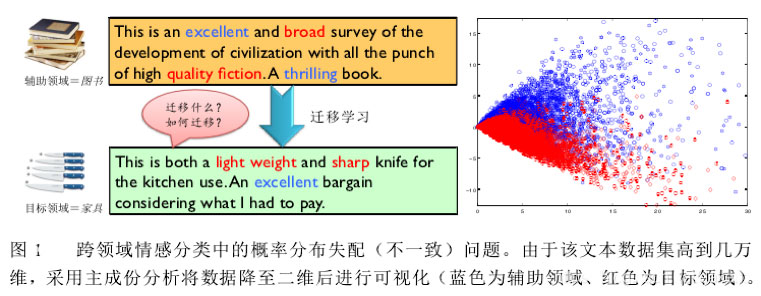
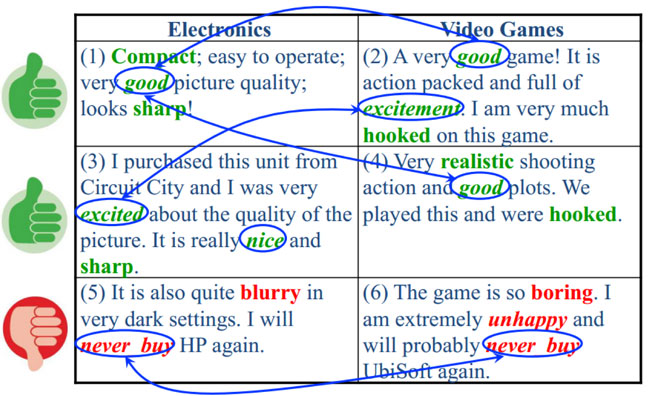
上圖是一個商品評論情感分析的例子,圖中包含兩個不同的產品領域:books 圖書領域和 furniture 家具領域;在圖書領域,通常用“broad”、“quality fiction”等詞匯來表達正面情感,而在家具領域中卻由“sharp”、“light weight”等詞匯來表達正面情感。可見此任務中,不同領域的不同情感詞多數不發生重疊、存在領域獨享詞、且詞匯在不同領域出現的頻率顯著不同,因此會導致領域間的概率分布失配問題。
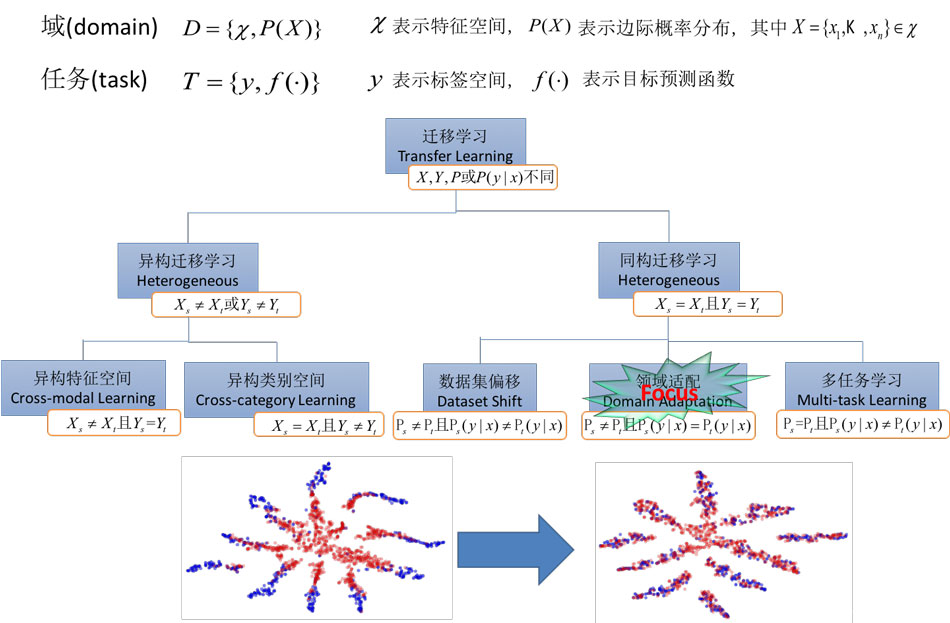
遷移學習里有兩個非常重要的概念
域(Domain)
任務(Task)
域 可以理解為某個時刻的某個特定領域,比如書本評論和電視劇評論可以看作是兩個不同的domain
任務 就是要做的事情,比如情感分析和實體識別就是兩個不同的task
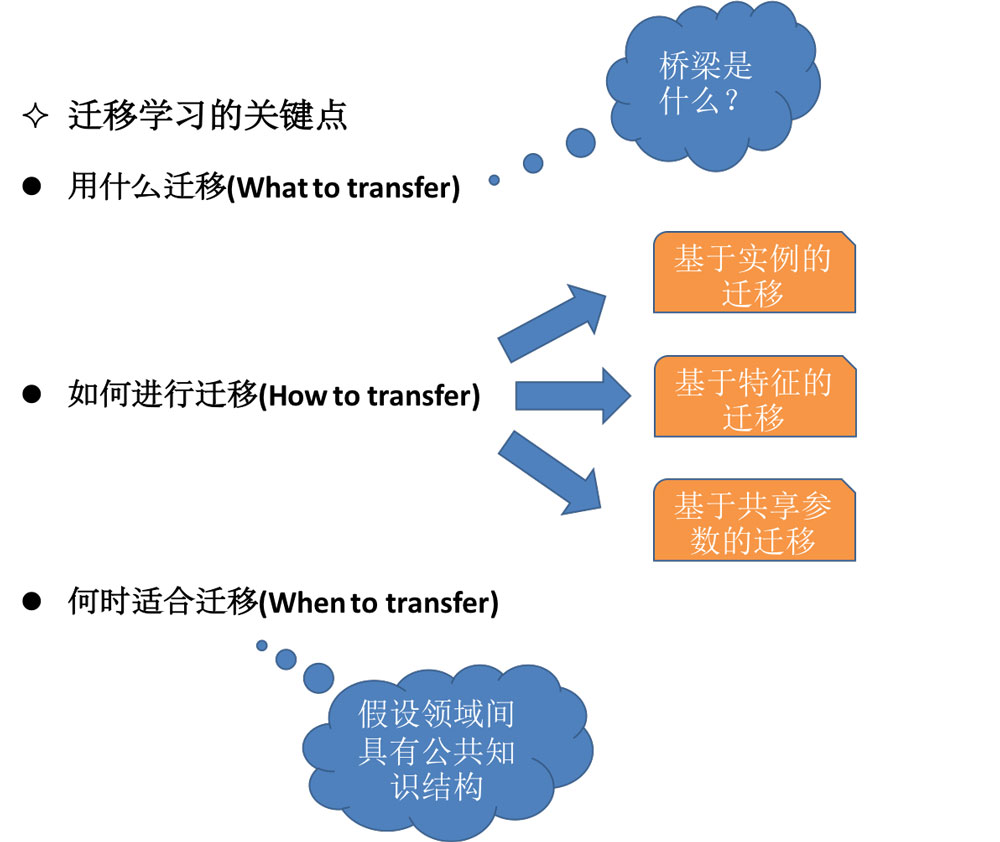
1.研究可以用哪些知識在不同的領域或者任務中進行遷移學習,即不同領域之間有哪些共有知識可以遷移。
2.研究在找到了遷移對象之后,針對具體問題所采用哪種遷移學習的特定算法,即如何設計出合適的算法來提取和遷移共有知識。
3.研究什么情況下適合遷移,遷移技巧是否適合具體應用,其中涉及到負遷移的問題。
當領域間的概率分布差異很大時,上述假設通常難以成立,這會導致嚴重的負遷移問題。
負遷移是舊知識對新知識學習的阻礙作用,比如學習了三輪車之后對騎自行車的影響,和學習漢語拼音對學英文字母的影響
研究如何利用正遷移,避免負遷移
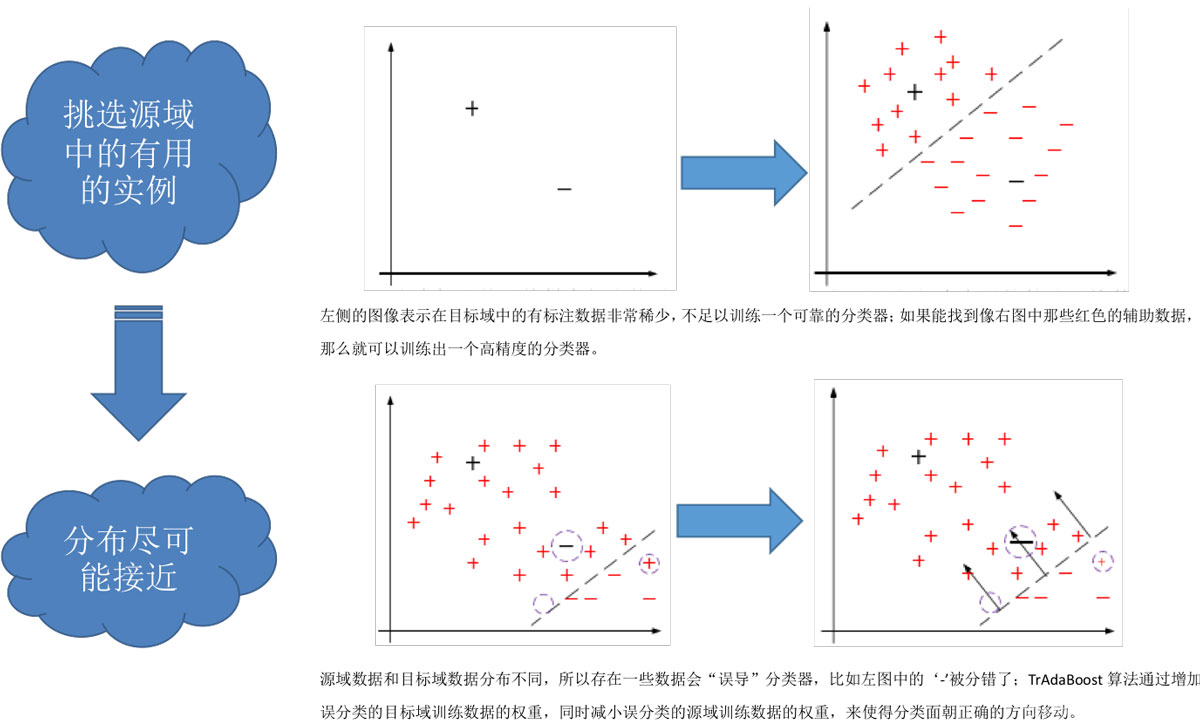
基于實例的遷移學習研究的是,如何從源領域中挑選出,對目標領域的訓練有用的實例,比如對源領域的有標記數據實例進行有效的權重分配,讓源域實例分布接近目標域的實例分布,從而在目標領域中建立一個分類精度較高的、可靠地學習模型。
因為,遷移學習中源領域與目標領域的數據分布是不一致,所以源領域中所有有標記的數據實例不一定都對目標領域有用。戴文淵等人提出的TrAdaBoost算法就是典型的基于實例的遷移。
基于特征選擇的遷移學習算法,關注的是如何找出源領域與目標領域之間共同的特征表示,然后利用這些特征進行知識遷移。
基于特征映射的遷移學習算法,關注的是如何將源領域和目標領域的數據從原始特征空間映射到新的特征空間中去。
這樣,在該空間中,源領域數據與的目標領域的數據分布相同,從而可以在新的空間中,更好地利用源領域已有的有標記數據樣本進行分類訓練,最終對目標領域的數據進行分類測試。
基于共享參數的遷移研究的是如何找到源數據和目標數據的空間模型之間的共同參數或者先驗分布,從而可以通過進一步處理,達到知識遷移的目的,假設前提是,學習任務中的的每個相關模型會共享一些相同的參數或者先驗分布。
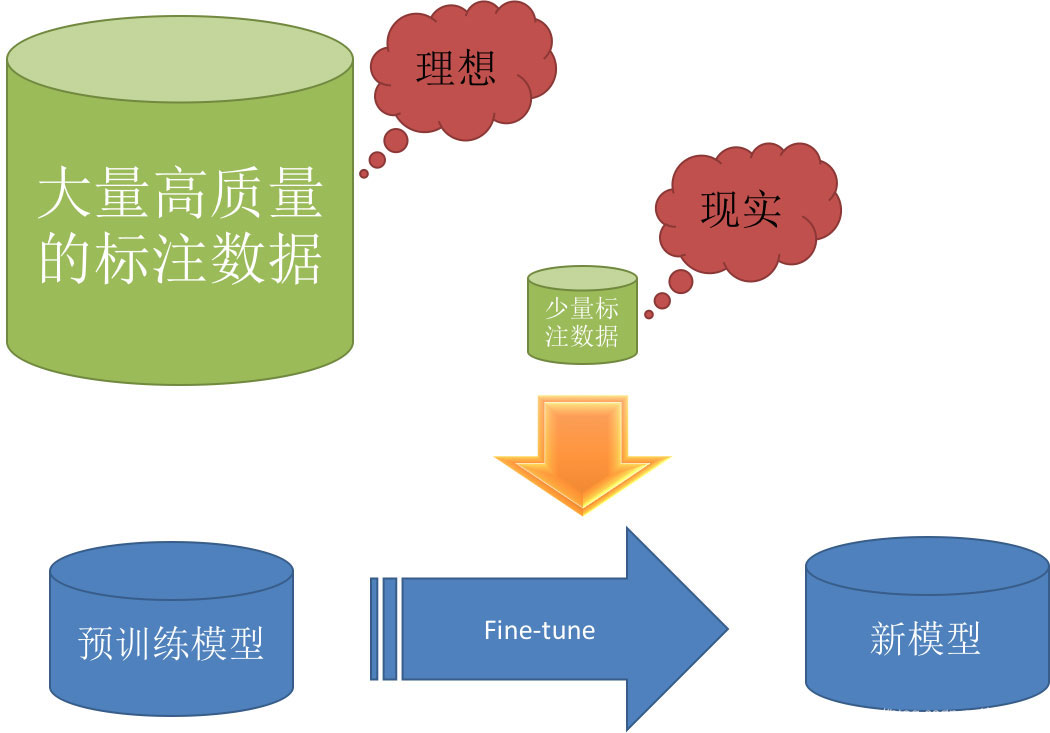
深度學習需要大量的高質量標注數據,Pre-training + fine-tuning 是現在深度學習中一個非常流行的trick,尤其是以圖像領域為代表,很多時候會選擇預訓練的ImageNet對模型進行初始化。
下面將主要通過一些paper對深度學習中的遷移學習應用進行探討
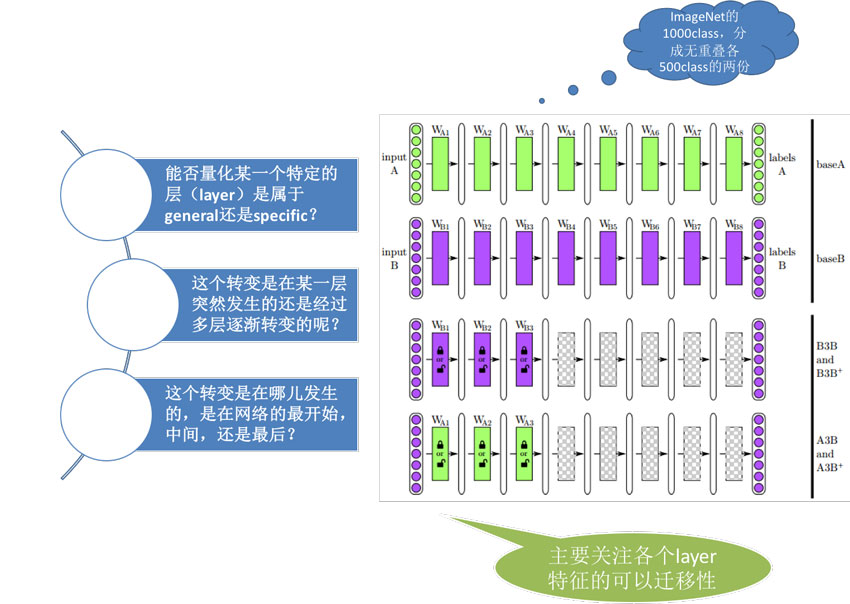
2014年Bengio等人在NIPS上發表論文 How transferable are features in deep neural networks,研究深度學習中各個layer特征的可遷移性(或者說通用性)
文章中進行了如下圖所示的實驗,有四種模型
Domain A上的基本模型BaseA
Domain B上的基本模型BaseB
Domain B上前n層使用BaseB的參數初始化(后續有frozen和fine-tuning兩種方式)
Domain B上前n層使用BaseA的參數初始化(后續有frozen和fine-tuning兩種方式)
將深度學習應用在圖像處理領域中時,會觀察到第一層(first-layer)中提取的features基本上是類似于Gabor濾波器(Gabor filters)和色彩斑點(color blobs)之類的。
通常情況下第一層與具體的圖像數據集關系不是特別大,而網絡的最后一層則是與選定的數據集及其任務目標緊密相關的;文章中將第一層feature稱之為一般(general)特征,最后一層稱之為特定(specific)特征
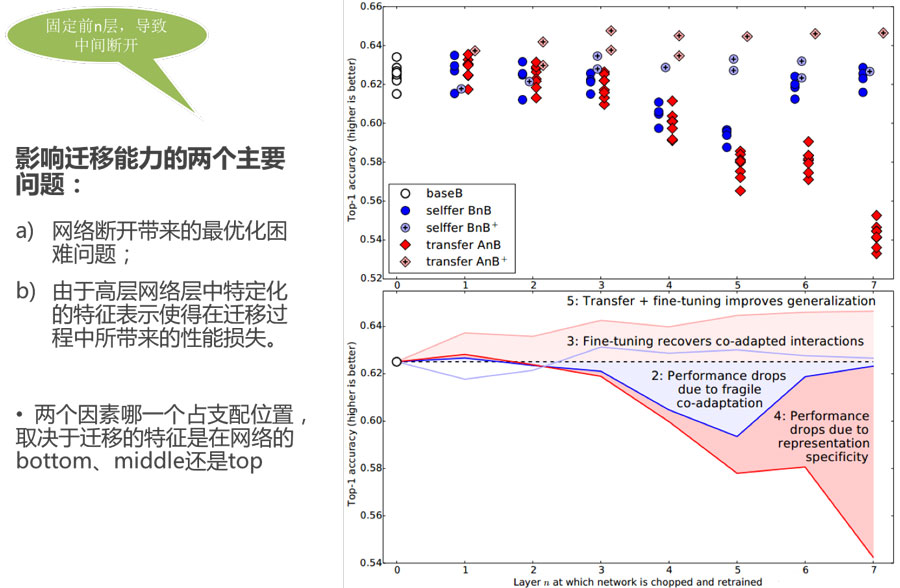
特征遷移使得模型的泛化性能有所提升,即使目標數據集非常大的時候也是如此。
隨著參數被固定的層數n的增長,兩個相似度小的任務之間的transferability gap的增長速度比兩個相似度大的兩個任務之間的transferability gap增長更快 兩個數據集越不相似特征遷移的效果就越差
即使從不是特別相似的任務中進行遷移也比使用隨機filters(或者說隨機的參數)要好
使用遷移參數初始化網絡能夠提升泛化性能,即使目標task經過了大量的調整依然如此。
這篇paper將近兩年流行的對抗網絡思想引入到遷移學習中,從而提出了DANN
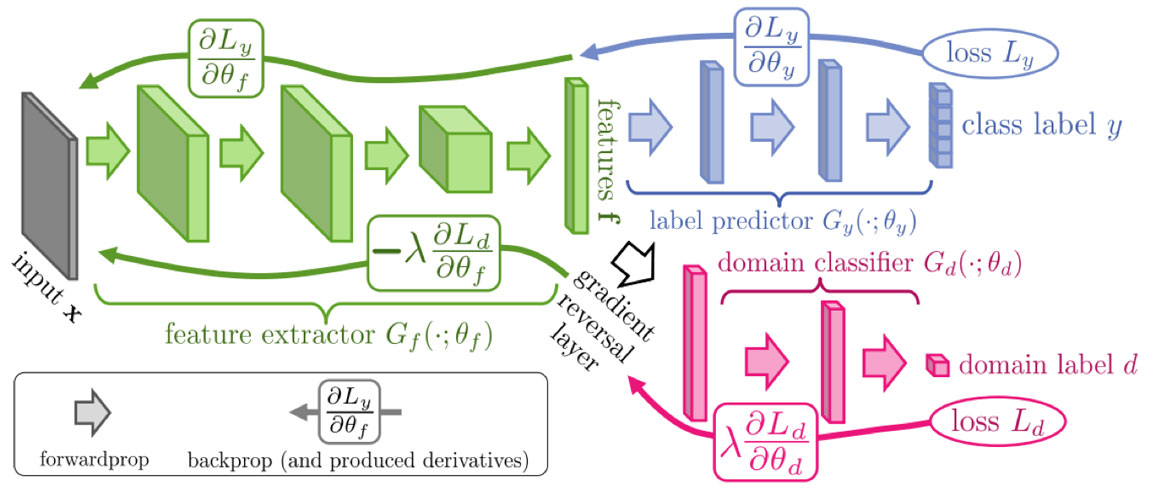
圖中所展示的即為DANN的結構圖,框架由feature extractor、label predictor和domain classifier三個部分組成,并且在feature extractor和domain classifier 之間有一個gradient reversal layer;其中domain classifier只在訓練過程中發揮作用
DANN將領域適配和特征學習整合到一個訓練過程中,將領域適配嵌入在特征表示的學習過程中;所以模型最后的分類決策是基于既有區分力又對領域變換具有不變性的特征。
優化特征映射參數的目的是為了最小化label classifier的損失函數,最大化domain classifier的損失函數,前者是為了提取出具有區分能力的特征,后者是為了提取出具有領域不變性的特征,最終優化得到的特征兼具兩種性質。
“人工智能中遷移的定義和使用方法”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





