溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“django中F與Q查詢的使用方法”,在日常操作中,相信很多人在django中F與Q查詢的使用方法問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”django中F與Q查詢的使用方法”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
F查詢
Q查詢
事務
其他鮮為人知的操作
Django ORM執行原生SQL
QuerySet方法大全
在上面所有的例子中,我們構造的過濾器都只是將字段值與某個我們自己設定的常量做比較。如果我們要對兩個字段的值做比較,那該怎么做呢?
Django 提供 F() 來做這樣的比較。F() 的實例可以在查詢中引用字段,來比較同一個 model 實例中兩個不同字段的值。
示例1:
查詢出賣出數大于庫存數的商品
from django.db.models import F
ret1=models.Product.objects.filter(maichu__gt=F('kucun'))
print(ret1)F可以幫我們取到表中某個字段對應的值來當作我的篩選條件,而不是我認為自定義常量的條件了,實現了動態比較的效果
Django 支持 F() 對象之間以及 F() 對象和常數之間的加減乘除和取模的操作。基于此可以對表中的數值類型進行數學運算
將每個商品的價格提高50塊
models.Product.objects.update(price=F('price')+50)引申:
如果要修改char字段咋辦(千萬不能用上面對數值類型的操作!!!)?
如:把所有書名后面加上'新款',(這個時候需要對字符串進行拼接Concat操作,并且要加上拼接值Value)
from django.db.models.functions import Concat
from django.db.models import Value
ret3=models.Product.objects.update(name=Concat(F('name'),Value('新款')))Concat表示進行字符串的拼接操作,參數位置決定了拼接是在頭部拼接還是尾部拼接,Value里面是要新增的拼接值
filter()等方法中逗號隔開的條件是與的關系。如果你需要執行更復雜的查詢(例如OR語句),你可以使用Q對象。
示例1:
查詢 賣出數大于100 或者 價格小于100塊的
from django.db.models import Q models.Product.objects.filter(Q(maichu__gt=100)|Q(price__lt=100))
對條件包裹一層Q時候,filter即可支持交叉并的比較符
示例2:
查詢 庫存數是100 并且 賣出數不是0 的產品
models.Product.objects.filter(Q(kucun=100)&~Q(maichu=0))
我們可以組合&和|操作符以及使用括號進行分組來編寫任意復雜的Q對象。
同時,Q對象可以使用~操作符取反,這允許組合正常的查詢和取反(NOT) 查詢。
示例3:
查詢產品名包含新款, 并且庫存數大于60的
models.Product.objects.filter(Q(kucun__gt=60), name__contains="新款")
查詢函數可以混合使用Q 對象和關鍵字參數。所有提供給查詢函數的參數(關鍵字參數或Q對象)都將"AND”在一起。但是,如果出現Q對象,它必須位于所有關鍵字參數的前面。
事務的定義:將多個sql語句操作變成原子性操作,要么同時成功,有一個失敗則里面回滾到原來的狀態,保證數據的完整性和一致性(NoSQL數據庫對于事務則是部分支持)
# 事務
# 買一本 跟老男孩學Linux 書
# 在數據庫層面要做的事兒
# 1. 創建一條訂單數據
# 2. 去產品表 將賣出數+1, 庫存數-1
from django.db.models import F
from django.db import transaction
# 開啟事務處理
try:
with transaction.atomic():
# 創建一條訂單數據
models.Order.objects.create(num="110110111", product_id=1, count=1)
# 能執行成功
models.Product.objects.filter(id=1).update(kucun=F("kucun")-1, maichu=F("maichu")+1)
except Exception as e:
print(e)條件假設:就拿博客園舉例,我們寫的博客并不是按照年月日來分檔,而是按照年月來分的,而我們的DateField時間格式是年月日形式,也就是說我們需要對從數據庫拿到的時間格式的數據再進行一次處理拿到我們想要的時間格式,這樣的需求,Django是沒有給我們提供方法的,需要我們自己去寫處理語句了
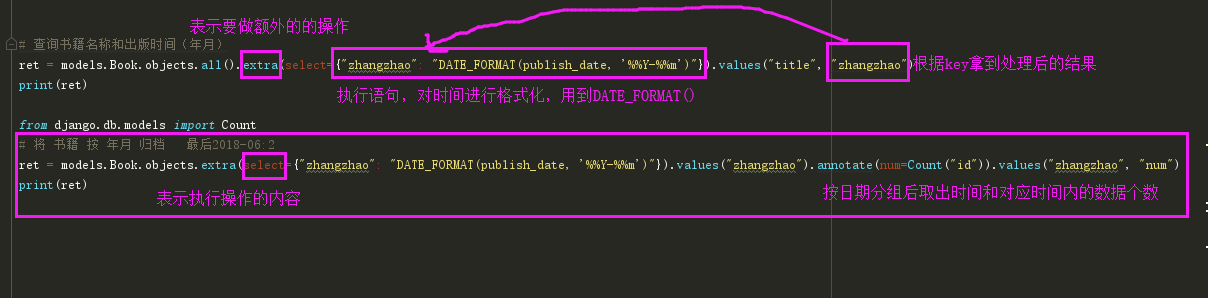
# extra
# 在QuerySet的基礎上繼續執行子語句
# extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# select和select_params是一組,where和params是一組,tables用來設置from哪個表
# Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
# Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
# Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
# Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
舉個例子:
models.UserInfo.objects.extra(
select={'newid':'select count(1) from app01_usertype where id>%s'},
select_params=[1,],
where = ['age>%s'],
params=[18,],
order_by=['-age'],
tables=['app01_usertype']
)
"""
select
app01_userinfo.id,
(select count(1) from app01_usertype where id>1) as newid
from app01_userinfo,app01_usertype
where
app01_userinfo.age > 18
order by
app01_userinfo.age desc
"""
# 執行原生SQL
# 更高靈活度的方式執行原生SQL語句
# from django.db import connection, connections
# cursor = connection.cursor() # cursor = connections['default'].cursor()
# cursor.execute("""SELECT * from auth_user where id = %s""", [1])
# row = cursor.fetchone()幾個比較重要的方法:
update()與save()的區別
兩者都是對數據的修改保存操作,但是save()函數是將數據列的全部數據項全部重新寫一遍,而update()則是針對修改的項進行針對的更新效率高耗時少
所以以后對數據的修改保存用update()
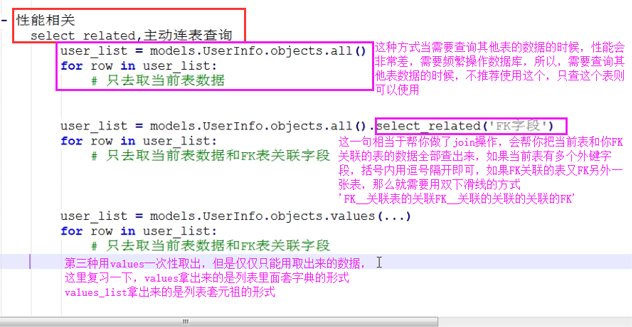
select_related和prefetch_related
def select_related(self, *fields)
性能相關:表之間進行join連表操作,一次性獲取關聯的數據。
總結:
1. select_related主要針一對一和多對一關系進行優化。
2. select_related使用SQL的JOIN語句進行優化,通過減少SQL查詢的次數來進行優化、提高性能。
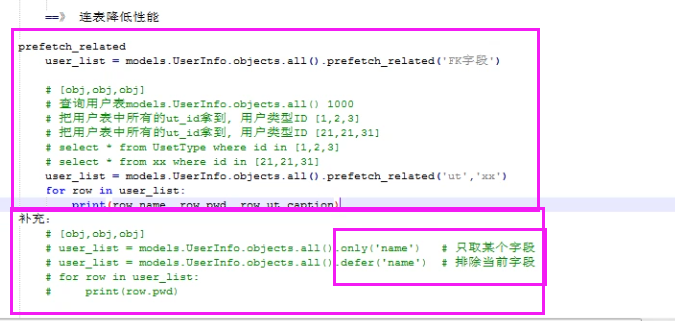
def prefetch_related(self, *lookups)
性能相關:多表連表操作時速度會慢,使用其執行多次SQL查詢在Python代碼中實現連表操作。
總結:
1. 對于多對多字段(ManyToManyField)和一對多字段,可以使用prefetch_related()來進行優化。
2. prefetch_related()的優化方式是分別查詢每個表,然后用Python處理他們之間的關系。lated
 bulk_create
bulk_create
批量插入數據
要求:一次性插入多條數據
data = ["".join([str(random.randint(65, 99)) for i in range(4)]) for j in range(100)] obj_list = [models.A(name=i) for i in data] models.A.objects.bulk_create(obj_list)

QuerySet方法大全
##################################################################
# PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET #
##################################################################
def all(self)
# 獲取所有的數據對象
def filter(self, *args, **kwargs)
# 條件查詢
# 條件可以是:參數,字典,Q
def exclude(self, *args, **kwargs)
# 條件查詢
# 條件可以是:參數,字典,Q
def select_related(self, *fields)
性能相關:表之間進行join連表操作,一次性獲取關聯的數據。
總結:
1. select_related主要針一對一和多對一關系進行優化。
2. select_related使用SQL的JOIN語句進行優化,通過減少SQL查詢的次數來進行優化、提高性能。
def prefetch_related(self, *lookups)
性能相關:多表連表操作時速度會慢,使用其執行多次SQL查詢在Python代碼中實現連表操作。
總結:
1. 對于多對多字段(ManyToManyField)和一對多字段,可以使用prefetch_related()來進行優化。
2. prefetch_related()的優化方式是分別查詢每個表,然后用Python處理他們之間的關系。
def annotate(self, *args, **kwargs)
# 用于實現聚合group by查詢
from django.db.models import Count, Avg, Max, Min, Sum
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id'))
# SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1)
# SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1)
# SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
def distinct(self, *field_names)
# 用于distinct去重
models.UserInfo.objects.values('nid').distinct()
# select distinct nid from userinfo
注:只有在PostgreSQL中才能使用distinct進行去重
def order_by(self, *field_names)
# 用于排序
models.UserInfo.objects.all().order_by('-id','age')
def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# 構造額外的查詢條件或者映射,如:子查詢
Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
def reverse(self):
# 倒序
models.UserInfo.objects.all().order_by('-nid').reverse()
# 注:如果存在order_by,reverse則是倒序,如果多個排序則一一倒序
def defer(self, *fields):
models.UserInfo.objects.defer('username','id')
或
models.UserInfo.objects.filter(...).defer('username','id')
#映射中排除某列數據
def only(self, *fields):
#僅取某個表中的數據
models.UserInfo.objects.only('username','id')
或
models.UserInfo.objects.filter(...).only('username','id')
def using(self, alias):
指定使用的數據庫,參數為別名(setting中的設置)
##################################################
# PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS #
##################################################
def raw(self, raw_query, params=None, translations=None, using=None):
# 執行原生SQL
models.UserInfo.objects.raw('select * from userinfo')
# 如果SQL是其他表時,必須將名字設置為當前UserInfo對象的主鍵列名
models.UserInfo.objects.raw('select id as nid from 其他表')
# 為原生SQL設置參數
models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,])
# 將獲取的到列名轉換為指定列名
name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'}
Person.objects.raw('SELECT * FROM some_other_table', translations=name_map)
# 指定數據庫
models.UserInfo.objects.raw('select * from userinfo', using="default")
################### 原生SQL ###################
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..)
def values(self, *fields):
# 獲取每行數據為字典格式
def values_list(self, *fields, **kwargs):
# 獲取每行數據為元祖
def dates(self, field_name, kind, order='ASC'):
# 根據時間進行某一部分進行去重查找并截取指定內容
# kind只能是:"year"(年), "month"(年-月), "day"(年-月-日)
# order只能是:"ASC" "DESC"
# 并獲取轉換后的時間
- year : 年-01-01
- month: 年-月-01
- day : 年-月-日
models.DatePlus.objects.dates('ctime','day','DESC')
def datetimes(self, field_name, kind, order='ASC', tzinfo=None):
# 根據時間進行某一部分進行去重查找并截取指定內容,將時間轉換為指定時區時間
# kind只能是 "year", "month", "day", "hour", "minute", "second"
# order只能是:"ASC" "DESC"
# tzinfo時區對象
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC)
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai'))
"""
pip3 install pytz
import pytz
pytz.all_timezones
pytz.timezone(‘Asia/Shanghai')
"""
def none(self):
# 空QuerySet對象
####################################
# METHODS THAT DO DATABASE QUERIES #
####################################
def aggregate(self, *args, **kwargs):
# 聚合函數,獲取字典類型聚合結果
from django.db.models import Count, Avg, Max, Min, Sum
result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid'))
===> {'k': 3, 'n': 4}
def count(self):
# 獲取個數
def get(self, *args, **kwargs):
# 獲取單個對象
def create(self, **kwargs):
# 創建對象
def bulk_create(self, objs, batch_size=None):
# 批量插入
# batch_size表示一次插入的個數
objs = [
models.DDD(name='r11'),
models.DDD(name='r22')
]
models.DDD.objects.bulk_create(objs, 10)
def get_or_create(self, defaults=None, **kwargs):
# 如果存在,則獲取,否則,創建
# defaults 指定創建時,其他字段的值
obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2})
def update_or_create(self, defaults=None, **kwargs):
# 如果存在,則更新,否則,創建
# defaults 指定創建時或更新時的其他字段
obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1})
def first(self):
# 獲取第一個
def last(self):
# 獲取最后一個
def in_bulk(self, id_list=None):
# 根據主鍵ID進行查找
id_list = [11,21,31]
models.DDD.objects.in_bulk(id_list)
def delete(self):
# 刪除
def update(self, **kwargs):
# 更新
def exists(self):
# 是否有結果到此,關于“django中F與Q查詢的使用方法”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





