溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關怎么用python搭建一個花卉識別系統,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
使用步驟如下:
* (1)在data_set文件夾下創建新文件夾"flower_data"
* (2)點擊鏈接下載花分類數據集download.tensorflow.org/example\_im…
* (3)解壓數據集到flower_data文件夾下
* (4)執行"split_data.py"腳本自動將數據集劃分成訓練集train和驗證集val
split_data.py
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夾存在,則先刪除原文件夾在重新創建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保證隨機可復現
random.seed(0)
# 將數據集中10%的數據劃分到驗證集中
split_rate = 0.1
# 指向你解壓后的flower_photos文件夾
cwd = os.getcwd()
data_root = os.path.join(cwd, "flower_data")
origin_flower_path = os.path.join(data_root, "flower_photos")
assert os.path.exists(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 建立保存訓練集的文件夾
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每個類別對應的文件夾
mk_file(os.path.join(train_root, cla))
# 建立保存驗證集的文件夾
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每個類別對應的文件夾
mk_file(os.path.join(val_root, cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
# 隨機采樣驗證集的索引
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 將分配至驗證集中的文件復制到相應目錄
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 將分配至訓練集中的文件復制到相應目錄
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
if __name__ == '__main__':
main()model.py
import torch.nn as nn import torch class AlexNet(nn.Module): def __init__(self, num_classes=1000, init_weights=False): super(AlexNet, self).__init__() # 用nn.Sequential()將網絡打包成一個模塊,精簡代碼 self.features = nn.Sequential( # 卷積層提取圖像特征 nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55] nn.ReLU(inplace=True), # 直接修改覆蓋原值,節省運算內存 nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27] nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27] nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13] nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13] nn.ReLU(inplace=True), nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13] nn.ReLU(inplace=True), nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13] nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6] ) self.classifier = nn.Sequential( # 全連接層對圖像分類 nn.Dropout(p=0.5), # Dropout 隨機失活神經元,默認比例為0.5 nn.Linear(128 * 6 * 6, 2048), nn.ReLU(inplace=True), nn.Dropout(p=0.5), nn.Linear(2048, 2048), nn.ReLU(inplace=True), nn.Linear(2048, num_classes), ) if init_weights: self._initialize_weights() # 前向傳播過程 def forward(self, x): x = self.features(x) x = torch.flatten(x, start_dim=1) # 展平后再傳入全連接層 x = self.classifier(x) return x # 網絡權重初始化,實際上 pytorch 在構建網絡時會自動初始化權重 def _initialize_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): # 若是卷積層 nn.init.kaiming_normal_(m.weight, mode='fan_out', # 用(何)kaiming_normal_法初始化權重 nonlinearity='relu') if m.bias is not None: nn.init.constant_(m.bias, 0) # 初始化偏重為0 elif isinstance(m, nn.Linear): # 若是全連接層 nn.init.normal_(m.weight, 0, 0.01) # 正態分布初始化 nn.init.constant_(m.bias, 0) # 初始化偏重為0
train.py
# 導入包
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from model import AlexNet
import os
import json
import time
# 使用GPU訓練
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
with open(os.path.join("train.log"), "a") as log:
log.write(str(device)+"\n")
#數據預處理
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), # 隨機裁剪,再縮放成 224×224
transforms.RandomHorizontalFlip(p=0.5), # 水平方向隨機翻轉,概率為 0.5, 即一半的概率翻轉, 一半的概率不翻轉
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
#導入、加載 訓練集
# 導入訓練集
#train_set = torchvision.datasets.CIFAR10(root='./data', # 數據集存放目錄
# train=True, # 表示是數據集中的訓練集
# download=True, # 第一次運行時為True,下載數據集,下載完成后改為False
# transform=transform) # 預處理過程
# 加載訓練集
#train_loader = torch.utils.data.DataLoader(train_set, # 導入的訓練集
# batch_size=50, # 每批訓練的樣本數
# shuffle=False, # 是否打亂訓練集
# num_workers=0) # num_workers在windows下設置為0
# 獲取圖像數據集的路徑
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path 返回上上層目錄
image_path = data_root + "/jqsj/data_set/flower_data/" # flower data_set path
# 導入訓練集并進行預處理
train_dataset = datasets.ImageFolder(root=image_path + "/train",
transform=data_transform["train"])
train_num = len(train_dataset)
# 按batch_size分批次加載訓練集
train_loader = torch.utils.data.DataLoader(train_dataset, # 導入的訓練集
batch_size=32, # 每批訓練的樣本數
shuffle=True, # 是否打亂訓練集
num_workers=0) # 使用線程數,在windows下設置為0
#導入、加載 驗證集
# 導入驗證集并進行預處理
validate_dataset = datasets.ImageFolder(root=image_path + "/val",
transform=data_transform["val"])
val_num = len(validate_dataset)
# 加載驗證集
validate_loader = torch.utils.data.DataLoader(validate_dataset, # 導入的驗證集
batch_size=32,
shuffle=True,
num_workers=0)
# 存儲 索引:標簽 的字典
# 字典,類別:索引 {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
# 將 flower_list 中的 key 和 val 調換位置
cla_dict = dict((val, key) for key, val in flower_list.items())
# 將 cla_dict 寫入 json 文件中
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
#訓練過程
net = AlexNet(num_classes=5, init_weights=True) # 實例化網絡(輸出類型為5,初始化權重)
net.to(device) # 分配網絡到指定的設備(GPU/CPU)訓練
loss_function = nn.CrossEntropyLoss() # 交叉熵損失
optimizer = optim.Adam(net.parameters(), lr=0.0002) # 優化器(訓練參數,學習率)
save_path = './AlexNet.pth'
best_acc = 0.0
for epoch in range(150):
########################################## train ###############################################
net.train() # 訓練過程中開啟 Dropout
running_loss = 0.0 # 每個 epoch 都會對 running_loss 清零
time_start = time.perf_counter() # 對訓練一個 epoch 計時
for step, data in enumerate(train_loader, start=0): # 遍歷訓練集,step從0開始計算
images, labels = data # 獲取訓練集的圖像和標簽
optimizer.zero_grad() # 清除歷史梯度
outputs = net(images.to(device)) # 正向傳播
loss = loss_function(outputs, labels.to(device)) # 計算損失
loss.backward() # 反向傳播
optimizer.step() # 優化器更新參數
running_loss += loss.item()
# 打印訓練進度(使訓練過程可視化)
rate = (step + 1) / len(train_loader) # 當前進度 = 當前step / 訓練一輪epoch所需總step
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
with open(os.path.join("train.log"), "a") as log:
log.write(str("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss))+"\n")
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
with open(os.path.join("train.log"), "a") as log:
log.write(str('%f s' % (time.perf_counter()-time_start))+"\n")
print('%f s' % (time.perf_counter()-time_start))
########################################### validate ###########################################
net.eval() # 驗證過程中關閉 Dropout
acc = 0.0
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1] # 以output中值最大位置對應的索引(標簽)作為預測輸出
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
# 保存準確率最高的那次網絡參數
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
with open(os.path.join("train.log"), "a") as log:
log.write(str('[epoch %d] train_loss: %.3f test_accuracy: %.3f \n' %
(epoch + 1, running_loss / step, val_accurate))+"\n")
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f \n' %
(epoch + 1, running_loss / step, val_accurate))
with open(os.path.join("train.log"), "a") as log:
log.write(str('Finished Training')+"\n")
print('Finished Training')訓練結果后,準確率是94%
訓練日志如下:

predict.py
import torch
接著對其中一個花卉圖片進行識別,其結果如下:

可以看到只有一個識別結果(daisy雛菊)和準確率1.0是100%(范圍是0~1,所以1對應100%)
為了方便使用這個神經網絡,接著我們將其開發成一個可視化的界面操作
main.py
# coding:utf-8
from flask import Flask, render_template, request, redirect, url_for, make_response, jsonify
from werkzeug.utils import secure_filename
import os
import time
###################
#模型所需庫包
import torch
from model import AlexNet
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model
model = AlexNet(num_classes=5)
# load model weights
model_weight_path = "./AlexNet.pth"
#, map_location='cpu'
model.load_state_dict(torch.load(model_weight_path, map_location='cpu'))
# 關閉 Dropout
model.eval()
###################
from datetime import timedelta
# 設置允許的文件格式
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'JPG', 'PNG', 'bmp'])
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS
app = Flask(__name__)
# 設置靜態文件緩存過期時間
app.send_file_max_age_default = timedelta(seconds=1)
#圖片裝換操作
def tran(img_path):
# 預處理
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img = Image.open("pgy2.jpg")
#plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
return img
@app.route('/upload', methods=['POST', 'GET']) # 添加路由
def upload():
path=""
if request.method == 'POST':
f = request.files['file']
if not (f and allowed_file(f.filename)):
return jsonify({"error": 1001, "msg": "請檢查上傳的圖片類型,僅限于png、PNG、jpg、JPG、bmp"})
basepath = os.path.dirname(__file__) # 當前文件所在路徑
path = secure_filename(f.filename)
upload_path = os.path.join(basepath, 'static/images', secure_filename(f.filename)) # 注意:沒有的文件夾一定要先創建,不然會提示沒有該路徑
# upload_path = os.path.join(basepath, 'static/images','test.jpg') #注意:沒有的文件夾一定要先創建,不然會提示沒有該路徑
print(path)
img = tran('static/images'+path)
##########################
#預測圖片
with torch.no_grad():
# predict class
output = torch.squeeze(model(img)) # 將輸出壓縮,即壓縮掉 batch 這個維度
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
res = class_indict[str(predict_cla)]
pred = predict[predict_cla].item()
#print(class_indict[str(predict_cla)], predict[predict_cla].item())
res_chinese = ""
if res=="daisy":
res_chinese="雛菊"
if res=="dandelion":
res_chinese="蒲公英"
if res=="roses":
res_chinese="玫瑰"
if res=="sunflower":
res_chinese="向日葵"
if res=="tulips":
res_chinese="郁金香"
#print('result:', class_indict[str(predict_class)], 'accuracy:', prediction[predict_class])
##########################
f.save(upload_path)
pred = pred*100
return render_template('upload_ok.html', path=path, res_chinese=res_chinese,pred = pred, val1=time.time())
return render_template('upload.html')
if __name__ == '__main__':
# app.debug = True
app.run(host='127.0.0.1', port=80,debug = True)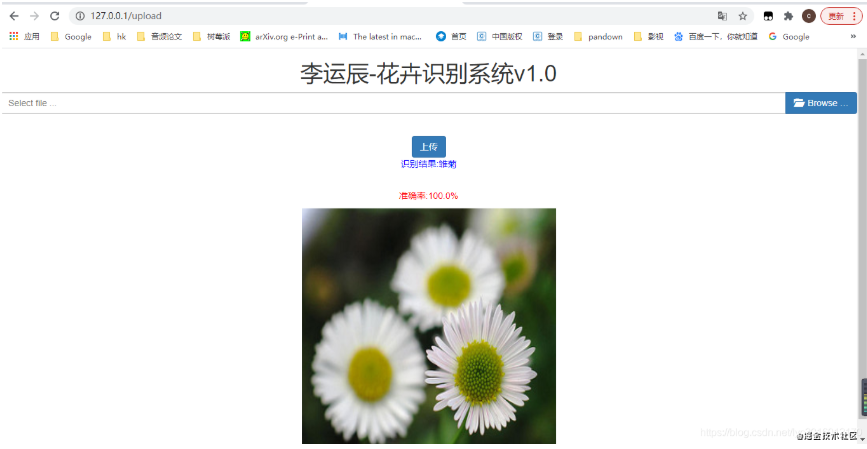
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>李運辰-花卉識別系統v1.0</title>
<link rel="stylesheet" type="text/css" href="../static/css/bootstrap.min.css" rel="external nofollow" >
<link rel="stylesheet" type="text/css" href="../static/css/fileinput.css" rel="external nofollow" >
<script src="../static/js/jquery-2.1.4.min.js"></script>
<script src="../static/js/bootstrap.min.js"></script>
<script src="../static/js/fileinput.js"></script>
<script src="../static/js/locales/zh.js"></script>
</head>
<body>
<h2 align="center">李運辰-花卉識別系統v1.0</h2>
<div align="center">
<form action="" enctype='multipart/form-data' method='POST'>
<input type="file" name="file" class="file" data-show-preview="false" />
<br>
<input type="submit" value="上傳" class="button-new btn btn-primary" />
</form>
<p >識別結果:{{res_chinese}}</p>
</br>
<p >準確率:{{pred}}%</p>
<img src="{{ './static/images/'+path }}" width="400" height="400" />
</div>
</body>
</html>python main.py
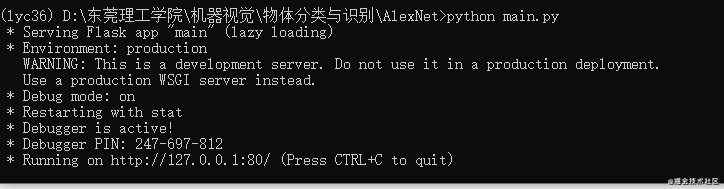
接著在瀏覽器在瀏覽器里面訪問
http://127.0.0.1/upload
出現如下界面:
最后來一個識別過程的動圖

關于“怎么用python搭建一個花卉識別系統”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





