溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹在Scrapy中怎么利用Xpath選擇器從網頁中采集目標數據,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
/具體實現/

1、針對標題,在上篇文章中就有提及,其Xpath表達式有多種,任選其一即可,在scrapy shell腳本下進行調試,得到標題的提取方式,并寫入到爬蟲主體文件中。
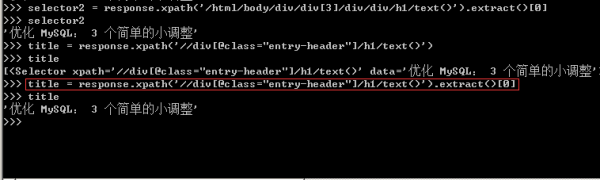
2、接下來是發布日期的提取,仍然是以交互式的方式實現網頁與源碼之間的交互,如下圖所示。
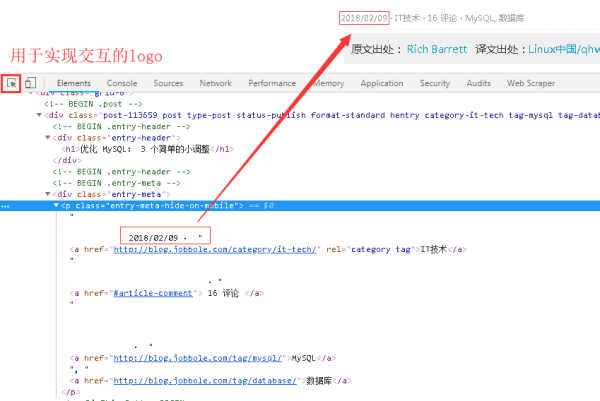
3、而且標簽“entry-meta-hide-on-mobile”具有全局唯一性,可以很方便的定位到元素。
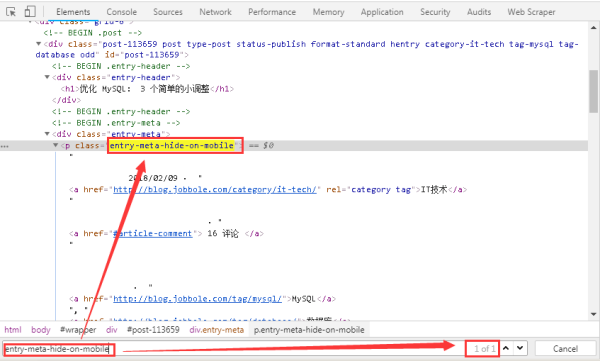
4、根據網頁結構,我們可輕易的寫出發布日期的Xpath表達式,可以在scrapy shell中先進行測試,再將選擇器表達式寫入爬蟲文件中,詳情如下圖所示。
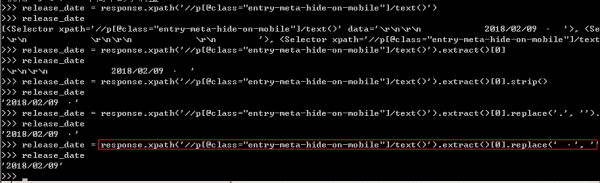
這里有部分雜質信息,需要利用strip()和replace()函數剔除多余的雜質,還日期一個“清白”。
5、關于文章主題標簽的Xpath表達式,可以看到其在網頁結構上處于日期的下方,如下圖所示。
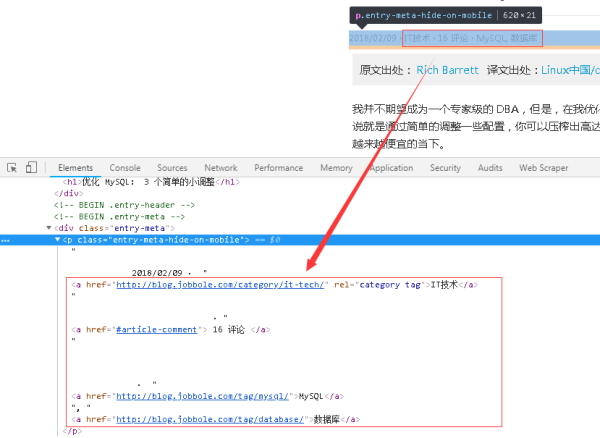
因此可以通過更改一下發布日期的Xpath表達式,即可獲取到文章主題標簽。
6、文章主題標簽處于a標簽下,如下圖所示。
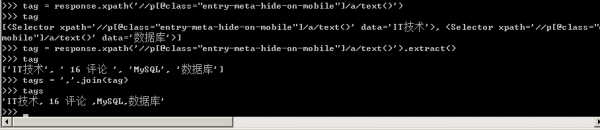
獲取到整個列表之后,利用join函數將數組中的元素以逗號連接生成一個新的字符串叫tags,然后寫入Scrapy爬蟲文件中去。
7、對于點贊數,其分析方法同之前一致,找到唯一的一個標簽“vote-post-up”即可定位到數據。
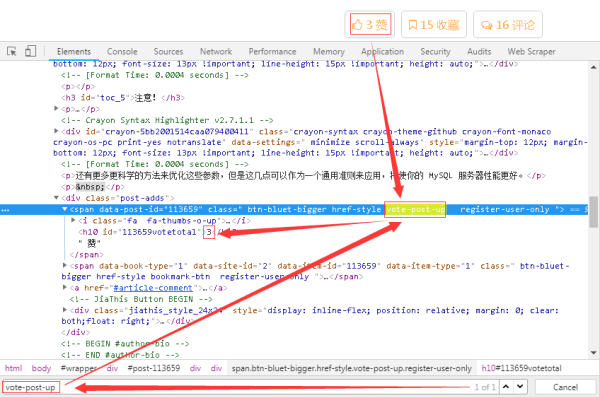
8、細心的小伙伴可能會看到“vote-post-up”屬性并不是class標簽中唯一一個屬性,所以一開始的Xpath表達式匹配的內容為空。
這里給大家安利一個小技巧,如果標簽中存在多個屬性,且屬性是唯一的時候,可以利用contains函數進行助攻,其用法是'//span[contains(@class,"vote-post-up"),務必要多加練習,否則容易忘記。根據網頁結構寫出Xpath表達式,調試的過程如下圖所示。
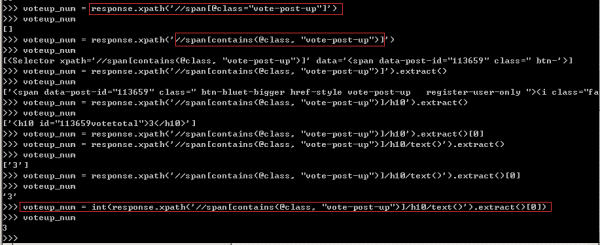
取出的點贊數是個字符串,需要利用int()將其強制轉換為數字。
/具體實現/
9、根據點贊數采集的方法,我們可以很快的定位到收藏數,其對應的網頁結構稍微有些不同,但是分析方法是一致的,不再贅述,如下圖所示。
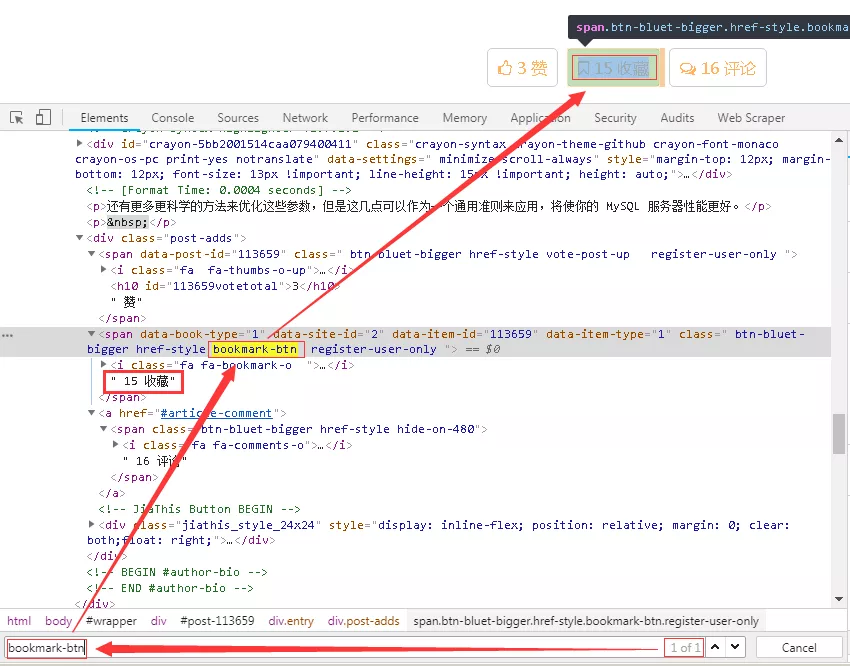
10、這里直接給出調試的代碼,如下圖所示。

11、不過我們需要的是其中的數字,這時候就可以利用正則表達式進行匹配,關于正則表達式的文章,之前有過連載,不熟悉正則表達式的小伙伴可以翻看歷史文章,有詳細說明的。在Pycharm中進行調試,代碼也很簡單,如下圖所示。
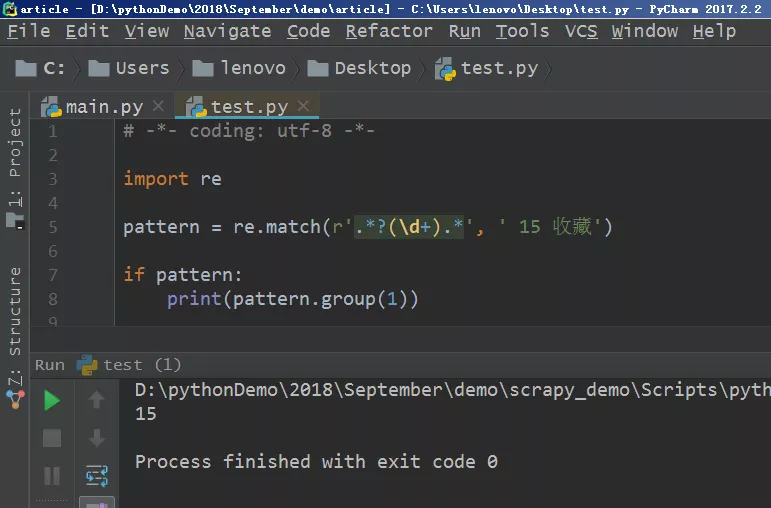
爾后將該代碼放入到爬蟲主體文件中即可,記得將“15 收藏”這部分替換成collection_num即可。
12、評論數相對簡單一些,其有專門的一個標簽,如下圖所示。
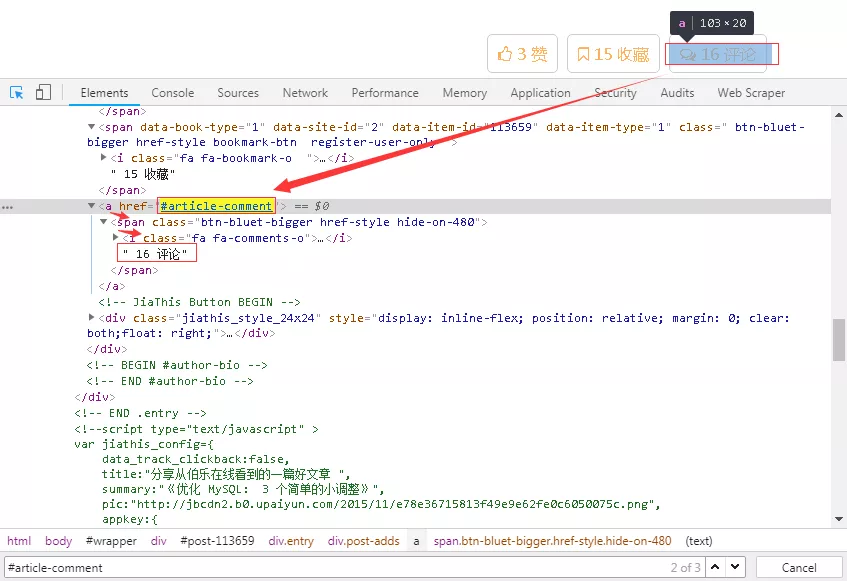
13、需要注意的是評論數這里的標簽不是class,而是href,需要和網頁上對應,否則取出的值為空列表。
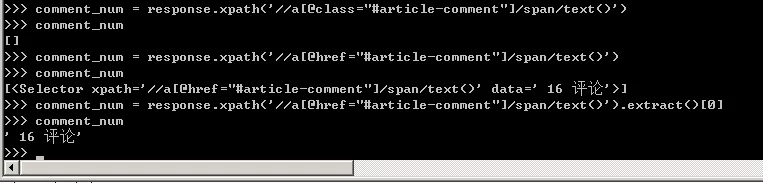
14、同收藏數一樣,仍然要以正則表達式的形式去匹配數字,可以直接復制收藏數的代碼,然后將收藏數collection_num改為評論數的comment_num即可。

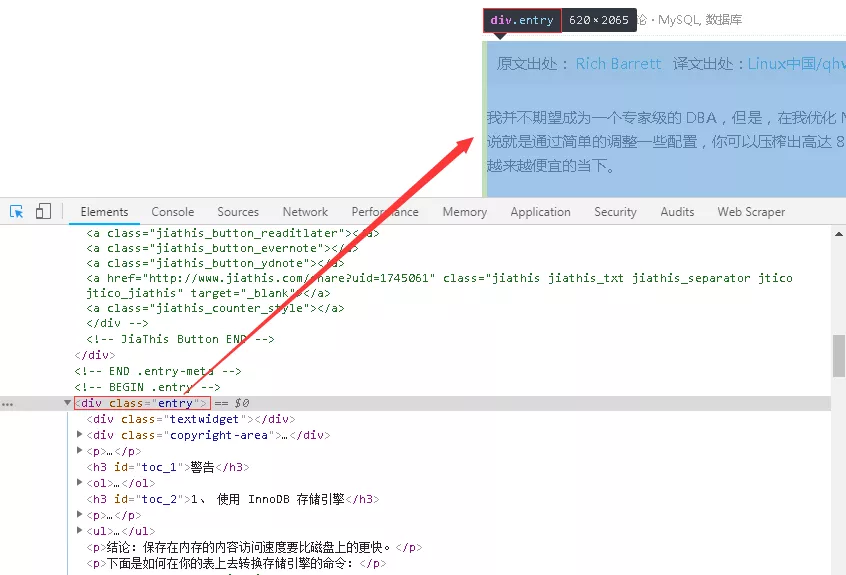
15、關于正文的提取,不同的網頁有不同的結構,而且相對復雜,這里不做細究,整體目標是將網頁內容和標簽均提取出來。分析網頁結構,發現正文內容在“entry”標簽下,如下圖所示。
\
16、之后在scrapyshell調試,可以得到內容的Xpath表達式,如下圖所示。
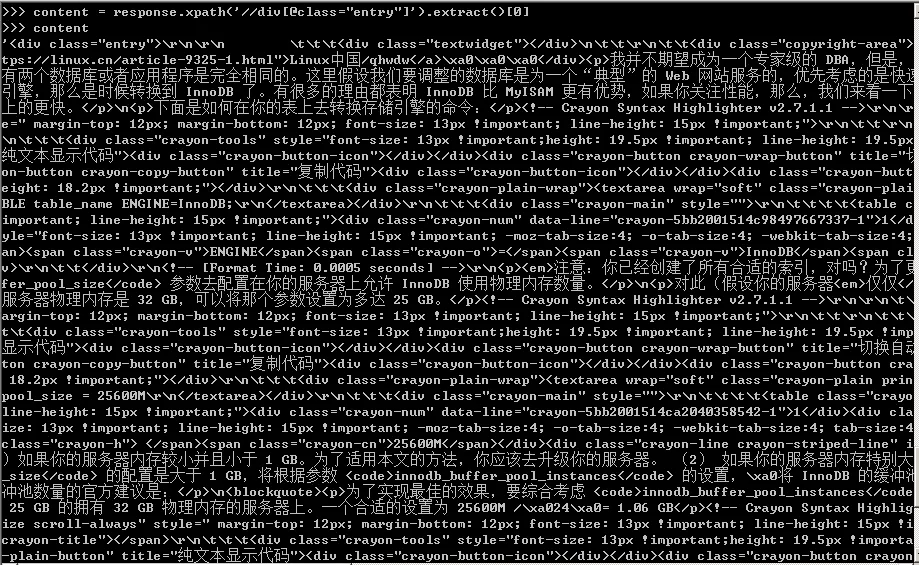
17、到這里,該網頁中的信息提取的差不多了,結合上面的分析和Xpath表達式,我們得到的整體代碼如下圖所示。
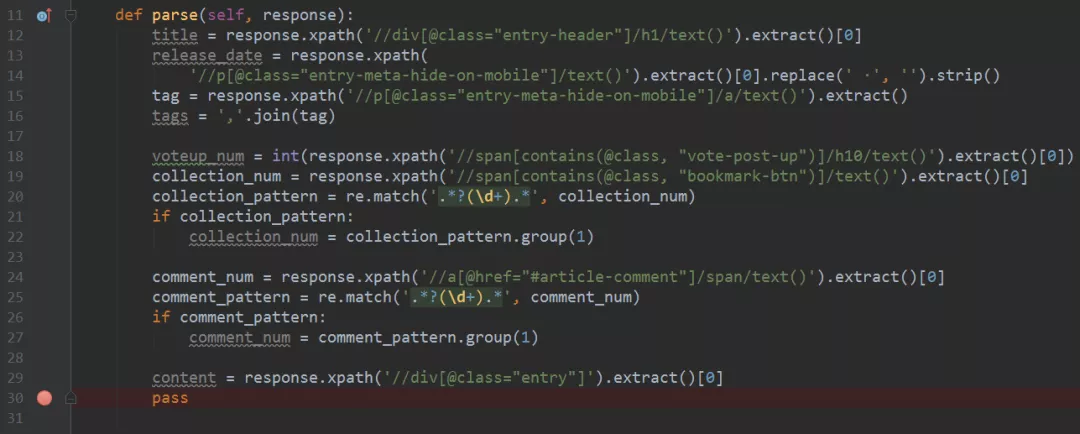
18、爾后進行Debug調試,查看代碼中獲取的內容,如下圖所示,十分清晰。
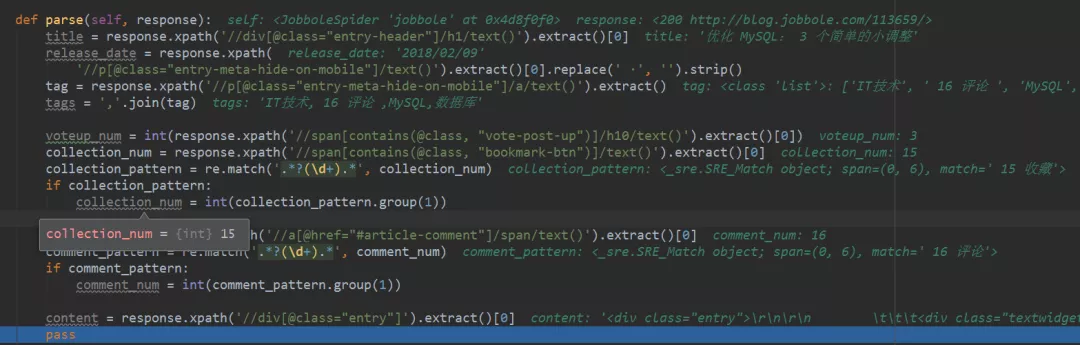
19、下圖是控制臺部分顯示出的變量結果,與代碼中顯示的內容和網頁上的信息都是保持一致的。
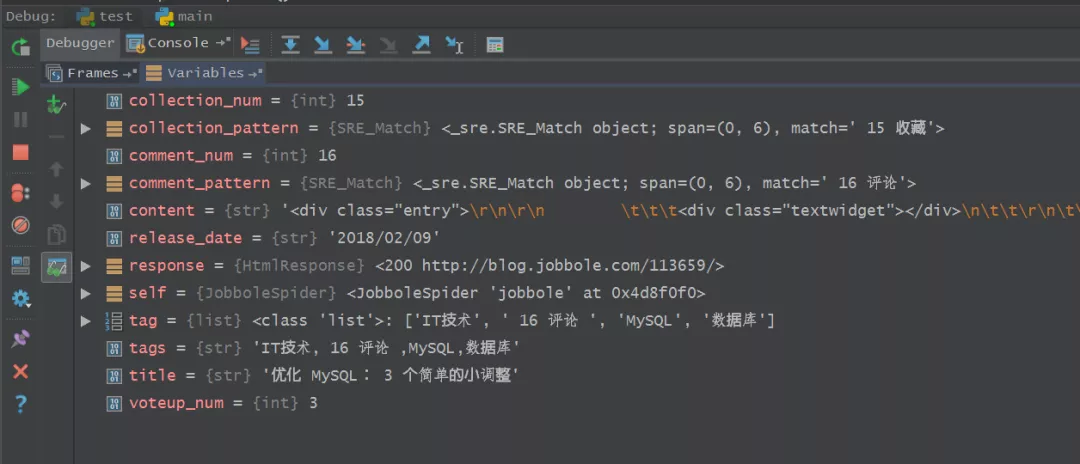
至此,關于Xpath表達式的具體應用教程先告一段落。總體來看,我們需要利用F12快捷鍵來審查網頁元素,爾后分析網頁結構并進行交互,然后根據網頁結構寫出Xpath表達式,習慣性的結合scrapy shell進行調試,得到調優的表達式,寫入爬蟲文件中去,最后執行爬蟲程序或者Debug調試查看最終的數據采集結果。
以上是“在Scrapy中怎么利用Xpath選擇器從網頁中采集目標數據”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





