溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
java集成體系中list的對比及適用場景是怎樣的,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
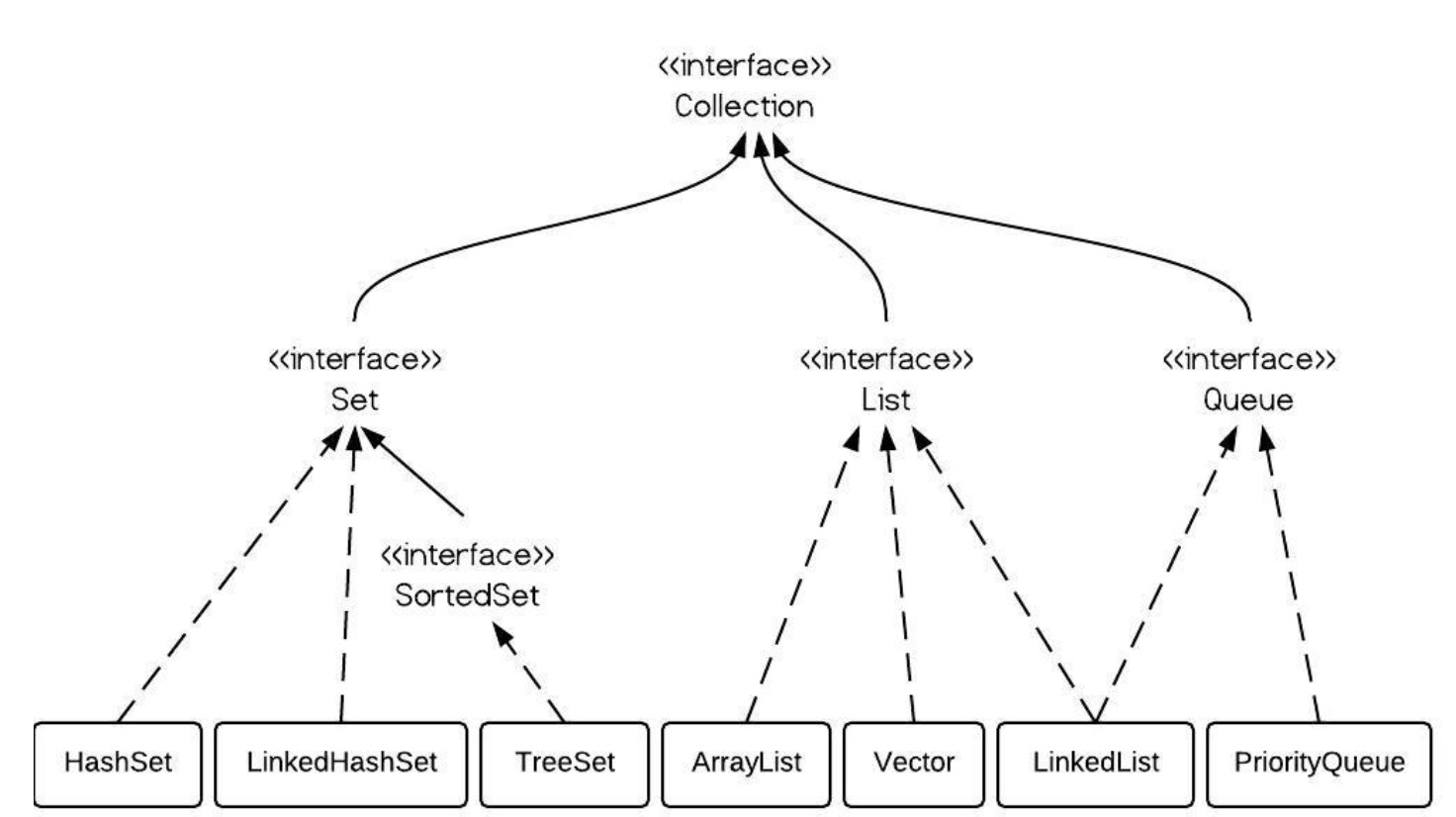
1、List,Set都是繼承自Collection接口,Map則不是
2、List特點:元素有放入順序,元素可重復 ,Set特點:元素無放入順序,元素不可重復,重復元素會覆蓋掉,(注意:元素雖然無放入順序,但是元素在set中的位置是有該元素的HashCode決定的,其位置其實是固定的,加入Set 的Object必須定義equals()方法 ,另外list支持for循環,也就是通過下標來遍歷,也可以用迭代器,但是set只能用迭代,因為他無序,無法用下標來取得想要的值。)
3.Set和List對比:
Set:檢索元素效率低下,刪除和插入效率高,插入和刪除不會引起元素位置改變。
List:和數組類似,List可以動態增長,查找元素效率高,插入刪除元素效率低,因為會引起其他元素位置改變。
4.Map適合儲存鍵值對的數據
5.線程安全集合類與非線程安全集合類
LinkedList、ArrayList、HashSet是非線程安全的,Vector是線程安全的;
HashMap是非線程安全的,HashTable是線程安全的;
StringBuilder是非線程安全的,StringBuffer是線程安全的。
Arraylist:
優點:ArrayList是實現了基于動態數組的數據結構,因為地址連續,一旦數據存儲好了,查詢操作效率會比較高(在內存里是連著放的)。
缺點:因為地址連續, ArrayList要移動數據,所以插入和刪除操作效率比較低。
LinkedList:
優點:LinkedList基于鏈表的數據結構,地址是任意的,所以在開辟內存空間的時候不需要等一個連續的地址,對于新增和刪除操作add和remove,LinedList比較占優勢。LinkedList 適用于要頭尾操作或插入指定位置的場景
缺點:因為LinkedList要移動指針,所以查詢操作性能比較低。
適用場景分析:
當需要對數據進行對此訪問的情況下選用ArrayList,當需要對數據進行多次增加刪除修改時采用LinkedList。
ArrayList有三個構造方法:
public ArrayList(int initialCapacity)//構造一個具有指定初始容量的空列表。
public ArrayList()//構造一個初始容量為10的空列表。
public ArrayList(Collection<? extends E> c)//構造一個包含指定 collection 的元素的列表
Vector有四個構造方法:
public Vector()//使用指定的初始容量和等于零的容量增量構造一個空向量。
public Vector(int initialCapacity)//構造一個空向量,使其內部數據數組的大小,其標準容量增量為零。
public Vector(Collection<? extends E> c)//構造一個包含指定 collection 中的元素的向量
public Vector(int initialCapacity,int capacityIncrement)//使用指定的初始容量和容量增量構造一個空的向量
ArrayList和Vector都是用數組實現的,主要有這么三個區別:
1.Vector是多線程安全的,線程安全就是說多線程訪問同一代碼,不會產生不確定的結果。而ArrayList不是,這個可以從源碼中看出,Vector類中的方法很多有synchronized進行修飾,這樣就導致了Vector在效率上無法與ArrayList相比;
2.兩個都是采用的線性連續空間存儲元素,但是當空間不足的時候,兩個類的增加方式是不同。
3.Vector可以設置增長因子,而ArrayList不可以。
4.Vector是一種老的動態數組,是線程同步的,效率很低,一般不贊成使用。
適用場景分析:
1.Vector是線程同步的,所以它也是線程安全的,而ArrayList是線程異步的,是不安全的。如果不考慮到線程的安全因素,一般用ArrayList效率比較高。
2.如果集合中的元素的數目大于目前集合數組的長度時,在集合中使用數據量比較大的數據,用Vector有一定的優勢。
1.TreeSet 是二差樹(紅黑樹的樹據結構)實現的,Treeset中的數據是自動排好序的,不允許放入null值
2.HashSet 是哈希表實現的,HashSet中的數據是無序的,可以放入null,但只能放入一個null,兩者中的值都不能重復,就如數據庫中唯一約束
3.HashSet要求放入的對象必須實現HashCode()方法,放入的對象,是以hashcode碼作為標識的,而具有相同內容的String對象,hashcode是一樣,所以放入的內容不能重復。但是同一個類的對象可以放入不同的實例
適用場景分析:
HashSet是基于Hash算法實現的,其性能通常都優于TreeSet。為快速查找而設計的Set,我們通常都應該使用HashSet,在我們需要排序的功能時,我們才使用TreeSet。
HashMap 非線程安全
HashMap:基于哈希表實現。使用HashMap要求添加的鍵類明確定義了hashCode()和equals()[可以重寫hashCode()和equals()],為了優化HashMap空間的使用,您可以調優初始容量和負載因子。
TreeMap:非線程安全基于紅黑樹實現。TreeMap沒有調優選項,因為該樹總處于平衡狀態。
適用場景分析:
HashMap和HashTable:HashMap去掉了HashTable的contains方法,但是加上了containsValue()和containsKey()方法。HashTable同步的,而HashMap是非同步的,效率上比HashTable要高。HashMap允許空鍵值,而HashTable不允許。
HashMap:適用于Map中插入、刪除和定位元素。
Treemap:適用于按自然順序或自定義順序遍歷鍵(key)。
關于java集成體系中list的對比及適用場景是怎樣的問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





