溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“什么是Little's Law”,在日常操作中,相信很多人在什么是Little's Law問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”什么是Little's Law”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
在引出今天的主角Little's Law之前,有必要先統一一下我們描述“性能”的“基本語言”,畢竟語言不通是沒法交流的不是。
不同的服務設備對性能的定義也不同,例如CPU主要看主頻,磁盤主要看IOPS。本文主要針對后端的軟件服務性能(比如api服務,數據庫服務等)展開討論。限定好范圍后就應該給出一個性能的定義了:性能就是服務的處理請求的能力。衡量性能的指標常見的有三個:并發用戶數、吞吐量、響應時間。
指真正對服務發送請求的用戶數量,需要注意和在線用戶數的區別; 比如,某一時刻,在線用戶數為1000,其中只有100個用戶的操作觸發了與遠端服務的交互, 那么這時對遠端服務來說,并發用戶數是100,而不是1000。
單位時間內處理的請求數。
對應的英文是response time,也有的地方用 latency表示,即延遲。 需要統計一個時間段內的響應時間,求出特征值來表示響應時間。 常見的特征值包括平均值、最大值、最小值、分位值。
穩定的系統中同時被服務的用戶數量等于用戶到達系統的速度乘以每個用戶在系統中駐留的時間,適用于所有需要排隊的場景。 對應公式表示為:
N = X * R,其中 N 表示系統中同時活動的用戶, X 表示用戶相繼到達系統的速率,在穩定(這個詞非常重要!!!)狀態(用戶到達系統的速度等于用戶離開系統的速度)時即為系統吞吐量, R 表示每個用戶在系統中平均的駐留時間。
比如說,你正在排隊進入一個體檢中心,你可以通過估計人們進入的速率來知道自己還要等待多長時間。
體檢中心能容納約600人,每個人完成體檢的時間是2個小時, 即R=2小時,N=600人,根據公式計算: X=N/R=600人/2小時=300人/小時 所以以每小時300人的速度進入。 如果現在你的前面還有300個人,那么大約還要等上一個小時才會進入體檢中心。
前一部分說的三個指標的關系可以用Little's Law來表示,因為對用戶請求不斷發送到服務端進行處理的情況來說,就是一種排隊的場景,把Little's Law具體到這種場景那么對應的公式為:
并發數=吞吐量*響應時間
下面主要從接口服務和mysql服務兩個實例來觀察Little's Law的存在。
基于springboot暴露一個接口 接口本身會根據參數值休眠一段時間,這樣客戶端的壓測工具就可以控制接口的響應時間了。
@RestController
public class ApiLatency {
@RequestMapping("/test/latency/{ms}")
public String latency(@PathVariable long ms) {
try {
Thread.sleep(ms);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "Hello World!";
}
}通過jmeter設置不同的并發數對上面的接口進行壓測 

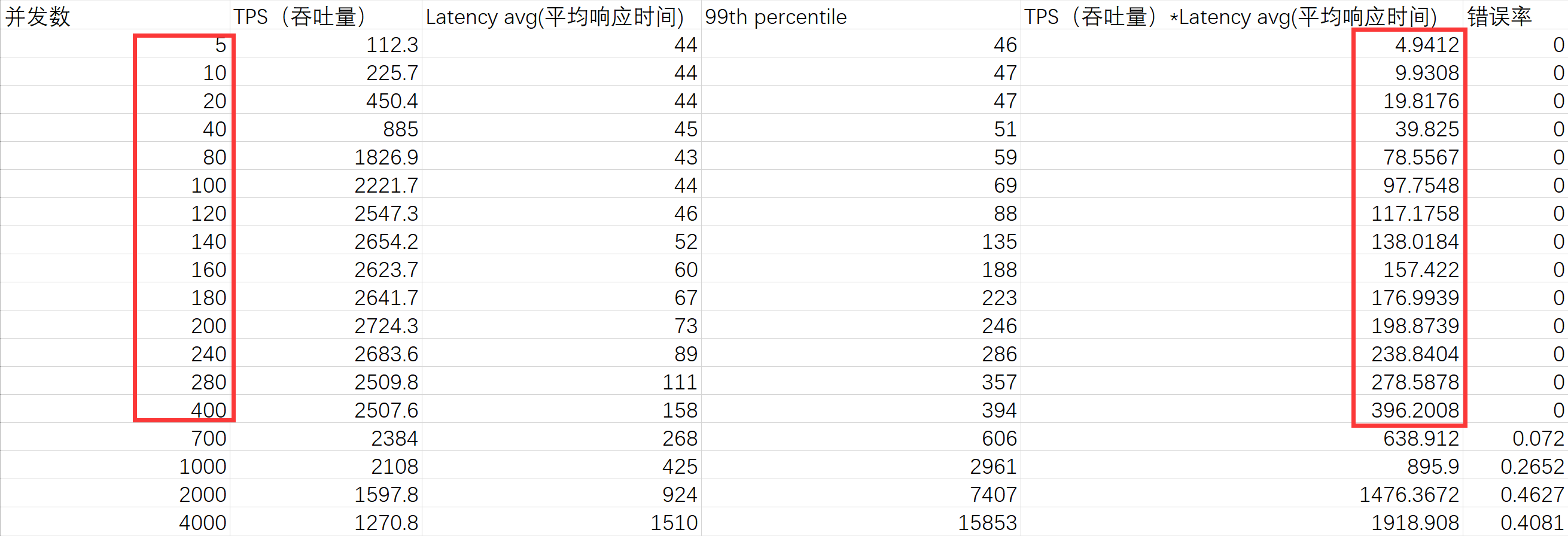
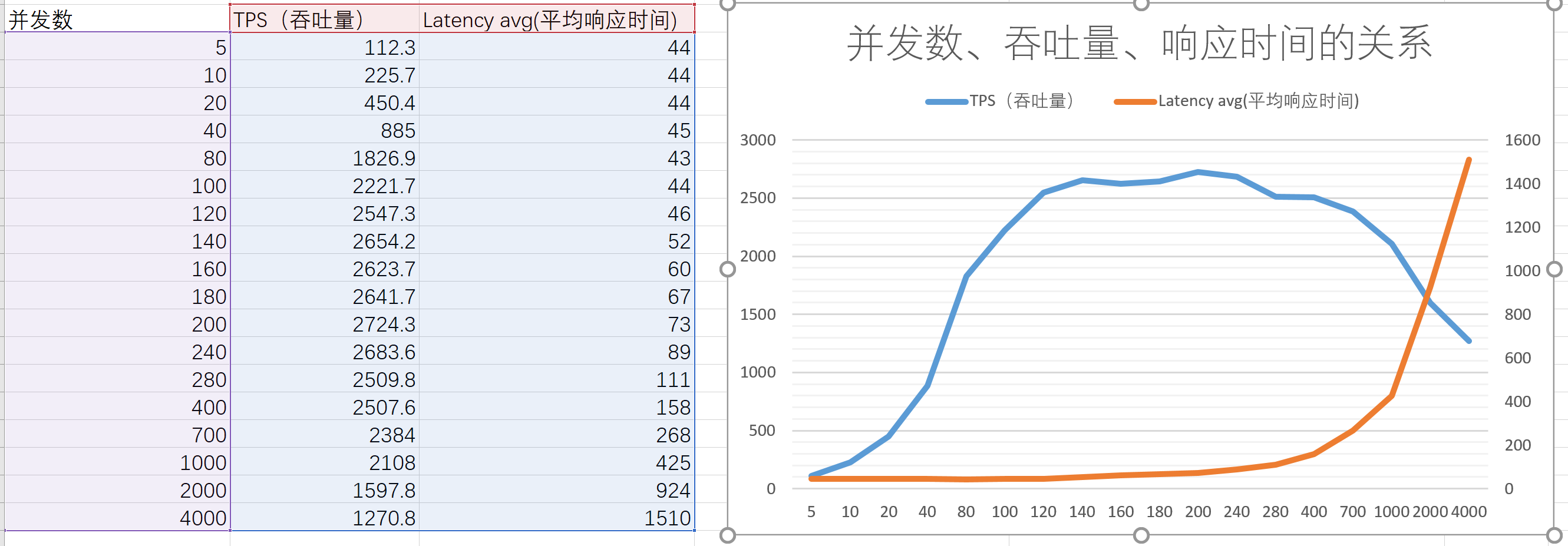
初始階段響應時間基本穩定,吞吐量隨著并發數的增加而增加; 隨著并發數增加,系統到達“拐點”,吞吐量開始出現下降的趨勢,同時響應時間也開始增大;繼續增加并發數,系統負載超負荷,從而進入過飽和區,此時響應時間急劇增大,吞吐量急劇下降。在“拐點”之前和剛進入拐點這段區域,此時可以認為系統為“穩定”的,此時并發數、吞吐量、平均響應時間是符合Little's Law公式的。
準備一個騰訊云mysql服務(5.6版本,配置為2核4G)和一臺云服務器(騰訊云內網測試)
用sysbench(0.5版本)對mysql服務進行測試
## 數據預置
sysbench --mysql-host=192.168.0.10 --mysql-port=3306 --mysql-user=root --mysql-password=test --mysql-db=loadtest --mysql-table-engine=innodb --test=/usr/local/share/sysbench/tests/include/oltp_legacy/oltp.lua --oltp_tables_count=8 --oltp-table-size=4000000 --rand-init=on prepare
## 執行shell腳本進行測試
for i in 5 7 8 10 12 25 50 128 200 400 700 1000
do
sysbench --mysql-host=192.168.0.10 --mysql-port=3306 --mysql-user=root --mysql-password=test --mysql-db=loadtest --test=/usr/local/share/sysbench/tests/include/oltp_legacy/oltp.lua --oltp_tables_count=8 --oltp-table-size=4000000 --num-threads=${i} --oltp-read-only=off --rand-type=special --max-time=180 --max-requests=0 --percentile=99 --oltp-point-selects=4 --report-interval=3 --forced-shutdown=1 run | tee -a sysbench.${i}.oltp.txt
done
## 清理數據
sysbench --mysql-host=192.168.0.10 --mysql-port=3306 --mysql-user=root --mysql-password=test --mysql-db=loadtest --mysql-table-engine=innodb --test=/usr/local/share/sysbench/tests/include/oltp_legacy/oltp.lua --oltp_tables_count=8 --oltp-table-size=4000000 --rand-init=on cleanup
## 腳本中參數的含義
--oltp_tables_count=8,表示本次用于測試的表數量為8張。
--oltp-table-size=4000000,表示本次測試使用的表行數均為400萬行。
--num-threads=n,表示本次測試的客戶端連接并發數為n。
--oltp-read-only=off ,off 表示測試關閉只讀測試模型,采用讀寫混合模型。
--rand-type=special,表示隨機模型為特定的。
--max-time=180,表示本次測試的執行時間180秒。
--max-requests=0,0 表示不限制總請求數,而是按 max-time 來測試。
--percentile=99,表示設定采樣比例,默認是95%,即丟棄1%的長請求,在剩余的99%里取最大值。
--oltp-point-selects=4,表示 oltp 腳本中 sql 測試命令,select 操作次數為4,默認值為1。
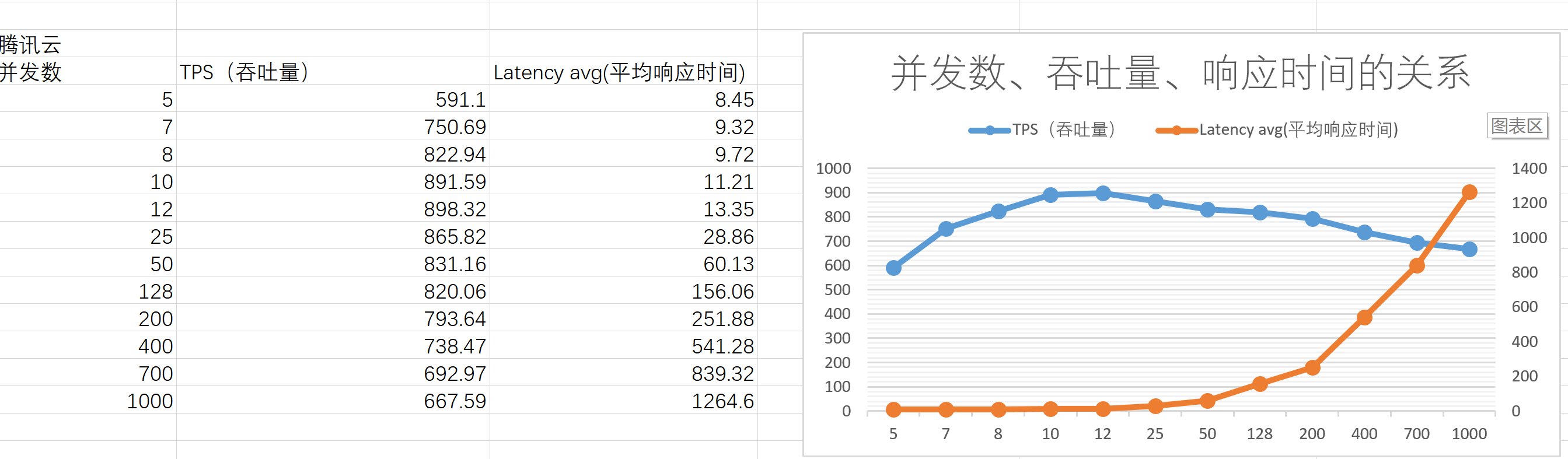
初始階段響應時間基本穩定,吞吐量隨著并發數的增加而增加; 隨著并發數增加,系統到達“拐點”,吞吐量開始出現下降的趨勢,同時響應時間也開始增大;繼續增加并發數,系統負載超負荷,從而進入過飽和區,此時響應時間急劇增大,吞吐量急劇下降。在“拐點”之前和剛進入拐點這段區域,此時可以認為系統為“穩定”的,此時并發數、吞吐量、平均響應時間是符合Little's Law公式的。
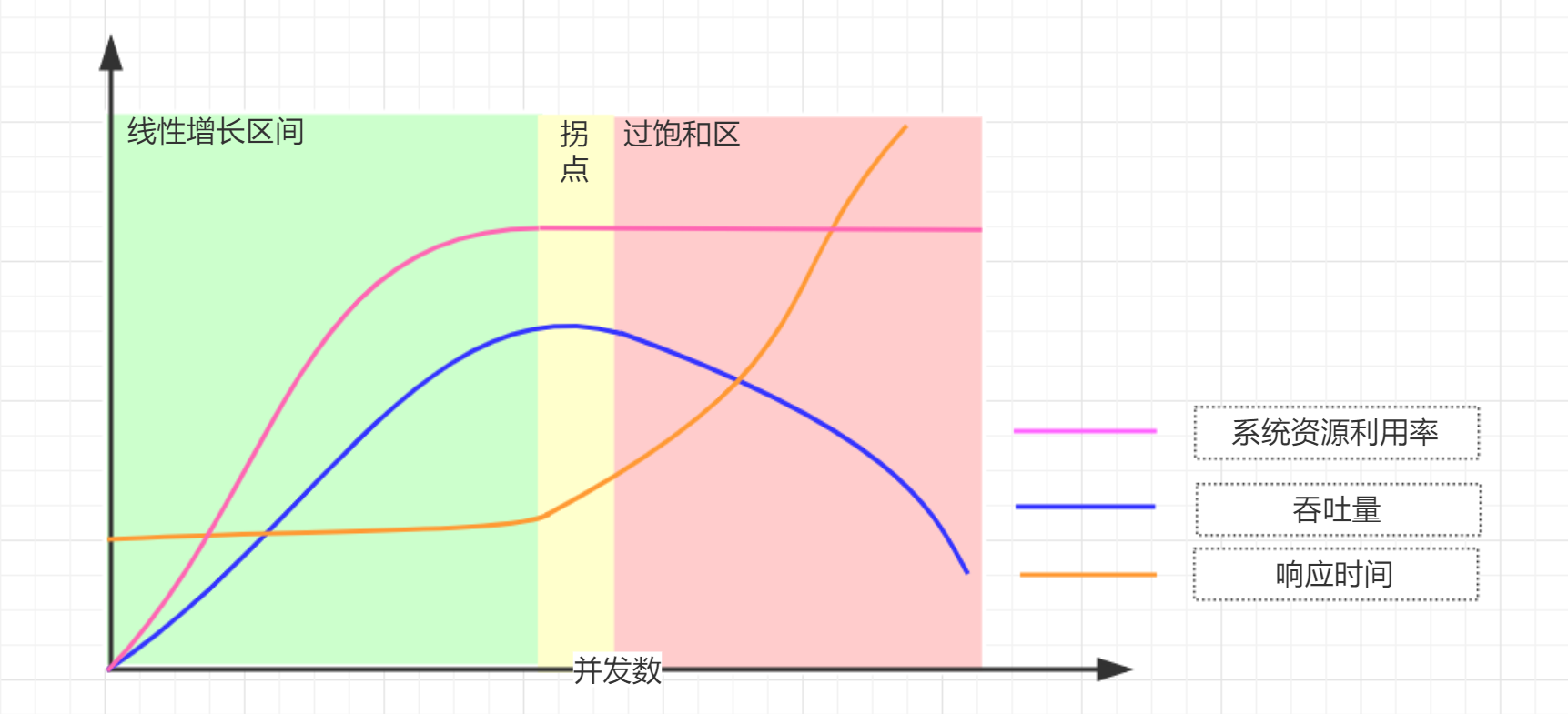
基于前述的兩個實測的例子,對于并發數、吞吐量、響應時間三者的關系,我們可以用上圖表示。
剛開始為“線性增長區”,此時響應時間基本穩定,吞吐量隨著并發用戶數的增加而增加;
當系統的資源利用率飽和時,系統到達“拐點”,隨著并發用戶數增加,吞吐量開始出現下降的趨勢,同時響應時間也開始增大;
繼續增加并發用戶數,系統負載超負荷,從而進入過飽和區,此時響應時間急劇增大,吞吐量急劇下降。
在“拐點”之前和剛進入拐點這段區域,此時可以認為系統為“穩定”的,此時并發數、吞吐量、平均響應時間是符合Little's Law公式的。
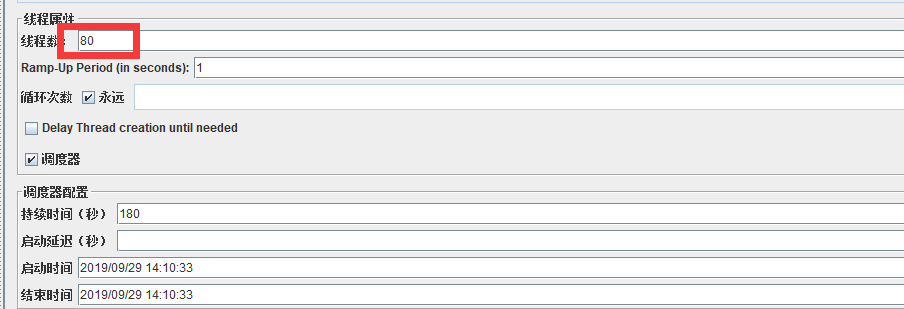
比如你這樣設置jmeter的線程數為80,測出的結果并不是說你的服務在80個用戶使用情況下的性能表現,實際場景中可能1000個真實用戶產生的壓力也沒有這里的80個線程(或者叫虛擬用戶數)產生的壓力大。我傾向于把并發數理解為一種壓力的度量,80的并發對服務的壓力肯定是大于60的并發對服務的壓力的。
假如一個程序只有1個線程,這個線程每秒可以處理10次事件,那么我們說這個程序處理單次事件的延遲為100ms,吞吐為10次/秒。
假如一個程序有4個線程,每個線程每秒可以處理5次事件,那么我們說這個程序處理單次事件的延遲為200ms,吞吐為20次/秒。
假如一個程序有1個線程,每個線程每秒可以處理20次事件,那么我們說這個程序處理單次事件的延遲為50ms,吞吐為20次/秒。
由Little's Law我們知道,并發數=吞吐量*響應時間,所以延遲和吞吐的關系是受并發數影響的,拋開并發數去找另外兩者的關系是沒有規律的。
性能如果只看吞吐量,不看響應時間是沒有意義的。從前面的分析我們知道,隨著并發數的逐漸增加,吞吐量有一個先上升再下降的過程,也就是存在同一個吞吐量的值,在不同并發下,會對應不同的響應時間。比如某接口吞吐量為10000TPS,響應時間達到5秒,那這個10000TPS也沒什么意義了。
比如在接口測試中,當并發數達到4000時,錯誤率達到了40%,那么此時的1270.8TPS就沒什么意義了。 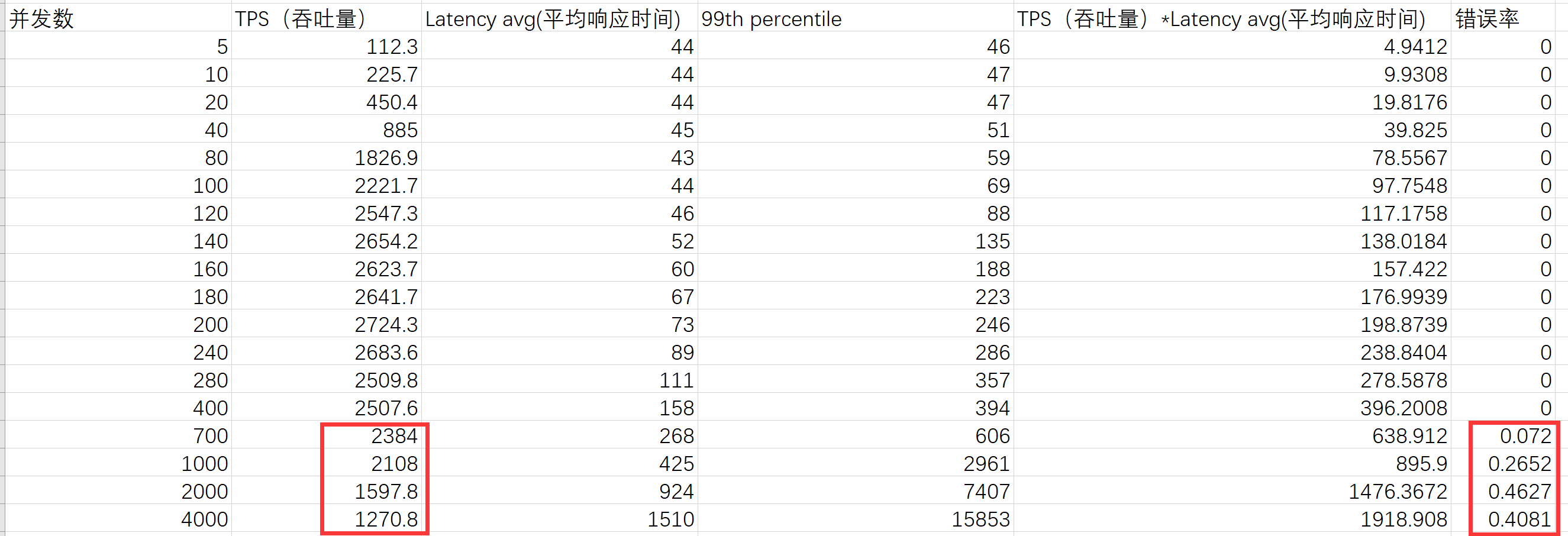
我理解的服務的性能就是又多又快又好的處理請求,“多”就是吞吐量大,“快”就是響應時間短,“好”就是錯誤率盡量低。
在Little's Law中我們一直用的響應時間是“平均響應時間”,而實際工作中我們通常用響應時間的“分位值”來作為響應時間的統計值來衡量性能的,平均值只是作為一個輔助參考。原因你應該懂得,比如“平均工資”通常沒多大參考價值,有可能很多人是被平均的。
Eric Man Wong 于2004年發表的《Method for Estimating the Number of Concurrent Users》論文中介紹了一種對系統并發用戶數估算的公式:

這個公式和Little's Law是等價的,具體論述過程參考Eric's并發用戶數估算與Little定律的等價性
到此,關于“什么是Little's Law”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





