溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“如何解決MySQL left join 查詢過慢的問題”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“如何解決MySQL left join 查詢過慢的問題”吧!
在工作的過程中要把sql server 數據庫中的幾個表遷移到MySQL當中,以為數據庫的方言和函數不同很多地方需要替換。在替換完成之后發現了一個問題,同樣的一句關聯查詢語句在sql server總只需要0.2秒左右,在MySQL中卻需要11秒左右。
SELECT a.estate_name AS estateName, a.location AS estateLocation, IFNULL( b.掛牌數量, 0 ) AS numberListed, IFNULL( c.成交數量, 0 ) AS tradingVolume FROM ( SELECT CONCAT( IFNULL( estate_name, '' ), IFNULL( area_name, '' ) ) AS ea, estate_name, MAX( location ) AS location FROM beike_estate GROUP BY estate_name, area_name ) AS a LEFT JOIN ( SELECT estate_name, COUNT( estate_name ) AS 掛牌數量 FROM beike_property WHERE estate_name IS NOT NULL GROUP BY estate_name ) AS b ON a.estate_name = b.estate_name LEFT JOIN ( SELECT CONCAT( IFNULL( estate_name, '' ), IFNULL( area_name, '' ) ) AS ea, COUNT( estate_name ) AS 成交數量 FROM crawler_publish_property WHERE `status` = 1 GROUP BY estate_name, area_name ) AS c ON a.ea = c.ea
SELECT a.estate_name AS estateName, a.location AS estateLocation, ISNULL( b.掛牌數量, 0 ) AS numberListed, ISNULL( c.成交數量, 0 ) AS tradingVolume FROM ( SELECT ISNULL( estate_name, '' ) + ISNULL( area_name, '' ) AS ea, estate_name, MAX ( location ) AS location FROM beike_estate GROUP BY estate_name, area_name ) AS a LEFT JOIN ( SELECT estate_name, COUNT ( estate_name ) AS 掛牌數量 FROM beike_property WHERE estate_name IS NOT NULL GROUP BY estate_name ) AS b ON a.estate_name = b.estate_name LEFT JOIN ( SELECT ISNULL( estate_name, '' ) + ISNULL( area_name, '' ) AS ea, COUNT ( estate_name ) AS 成交數量 FROM crawler_publish_property WHERE [status] = 1 GROUP BY estate_name, area_name ) AS c ON a.ea = c.ea
可以看到2句sql除了函數上的區別,其他地方基本沒有區別。
既然沒有區別為什么MySQL執行速度回這么慢呢?
查詢過慢先想到的就是添加索引,但是這句sql是有三張表查詢聚合出來的三張臨時表關聯查詢,由于臨時表并沒有辦法創建索引,我先在三張原始表上添加了索引,然后再次執行,速度還是和之前一樣還是10多秒,并沒有得到優化。使用 EXPLAIN 分析了一下這條sql,果然并沒有使用到索引。

既然索引加不了,那就只能尋找其他解決方案了。經過一番百度了解到對于連表MySQL有2中join的算法分別是
NLJ 算法:將驅動表/外部表的結果集作為循環基礎數據,然后循環從該結果集每次一條獲取數據作為下一個表的過濾條件查詢數據,然后合并結果。如果有多表join,則將前面的表的結果集作為循環數據,取到每行再到聯接的下一個表中循環匹配,獲取結果集返回給客戶端。
BNL 算法:將外層循環的行/結果集存入join buffer, 內層循環的每一行與整個buffer中的記錄做比較,從而減少內層循環的次數。
那么是不是因為lift join語句沒有使用 Block Nested Loop算法所以很慢呢使用EXPLAIN分析發現使用的已經是Block Nested Loop算法了,所以也不是這個原因。

經過一番百度我了解到MySQL有一個Join_buffer_size的配置,這個配置是控制MySQ join 查詢的緩存區大小的配置,Join_buffer_size的默認配置為128k。那么是不是由于這個緩存區太小導致查詢速度過慢呢,我去查詢了一下
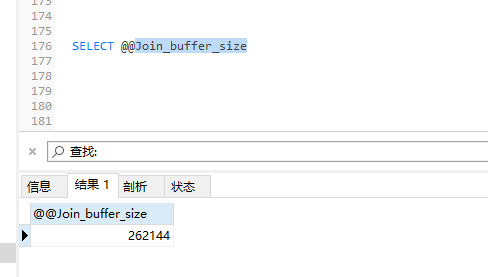
結果顯示緩存區域有256m的內存可供使用,也就說明查詢速度慢并不是這個原因導致的。
經過一番百度,發現并不是因為其他原因,就是單純的MySQL對join的處理效率不行。
既然在數據庫庫陳無法進行優化,那么只能在server層進行優化了
既然是lift join那么只需要把左表進行分頁查詢再使用多個線程去查詢,多個線程查詢完成后再封裝返回。
public List<BkFindEstateMsgDTO> findEstateMsg(){
List<BkFindEstateMsgDTO> list = beiKePropertyMapper.findEstateMsg();
Integer i = beiKePropertyMapper.findEstateCount(); // 先查出總數目
i = (i / 1000) + 1; // 計算需要幾個線程
Integer row = 1000;
CountDownLatch countDownLatch = new CountDownLatch(i); // 線程計數器
List<BkFindEstateMsgDTO> bkFindEstateMsgDTOS = new ArrayList<>();
for (int j = 0; j < i; j++) {
int j1 = j;
executorService.execute(() -> { // 多線程同時查詢
List<BkFindEstateMsgDTO> list = beiKePropertyMapper.findEstateMsg1(j1*row,row);
bkFindEstateMsgDTOS.addAll(list);
countDownLatch.countDown(); // 提交計數器
});
}
try {
countDownLatch.await(); // 所有線程完成提交
} catch (Exception e) {
e.printStackTrace();
}
}使用多線程之后只需要2秒左右就可執行完畢。
如果不想線程太多可以將sql拆分為2個lift join的查詢語句,使用2個線程同時進行查詢,第二條查詢語句返回map集合,將需要連表的條件作為key,查詢結果作為value,查詢出來之后遍歷第一個結果集合通過key取出對應的value set到對應的對象當中即可。這樣最后的查詢結果在6秒左右。
返回指定的列作為map集合的key只需要在dao層接口方法上添加@MapKey("")注解即可。
感謝各位的閱讀,以上就是“如何解決MySQL left join 查詢過慢的問題”的內容了,經過本文的學習后,相信大家對如何解決MySQL left join 查詢過慢的問題這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





