溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
JAVA中怎么實現內存分布,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
java的內存分布如下:
1,本地方法棧;
2,程序計數器;
3,虛擬機棧(棧幀1(方法A),棧幀2(方法B));
4,堆區(新生代(Eden區,S0,S1...),老年代);
5,元數據區(常量池,方法元信息,類元信息);
如下圖所示:
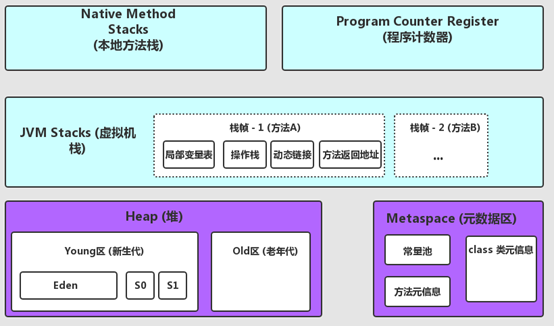
各個區域對應明細如下:
1,堆區:
存儲著幾乎所有的實例對象,堆由垃圾收集器自動回收,堆區由各子線程共享使用。
堆的內存空間既可以固定大小,也可以在運行時動態調整,通過如下參數設定初始值和最大值,比如-Xms256M –Xmx1024M,分別代表最小堆容量和最大堆容量,在線上環境時, JVM的Xms和Xmx設置成一樣大小,避免在GC后調整堆大小時帶來的額外壓力。
堆分成兩大塊:新生代和老年代,對象產生之初在新生代,步入暮年進入老年代,但是老年代也接納在新生代無法容納的超大對象,新生代=1個Eden區+2個Survivor區域。絕大部分對象在Eden區生成,當Eden區域填滿的時候,會觸發Young Garbage Collection,每個對象有一個計數器,每次YGC都會加1,-XX:MaxTenuringThreshold參數能配置計數器的值到達某個閾值的時候,對象從新生代晉升到老年代。
給JVM設置參數-XX:+HeapDumpOnOutOfMemoryError,讓JVM遇到OOM異常時能輸出堆內信息
2,虛擬機棧:
棧是一個先進后出的數據結構。
JVM是基于棧結構的運行環境,JVM中的虛擬機棧是描述java方法執行的內存區域,它是線程私有的;每個方法從開始調用到執行完成的過程,就是棧幀從入棧到出棧的過程;
棧幀是方法運行的基本結構,在執行引擎運行時,所有指令都只能對當前棧幀進行操作。而StackOverFlowError表示請求的棧溢出,導致內存耗盡,通常出現在遞歸方法中。
3,局部變量表:
局部變量表是存放方法參數和局部變量的區域。
4,操作棧:
操作棧是一個初始狀態為空的桶式結構棧。
5,本地方法棧:
本地方法棧為Native方法服務,現成開始調用本地方法時,會進入一個不再受JVM約束的世界。
6,程序計數寄存器:
由于CPU時間片輪限制,眾多線程在并發執行過程中,任何一個確定的時刻,一個處理器或者多核處理器中的一個內核,只會執行某個線程中的一條指令。線程執行和恢復都依賴程序計數器。
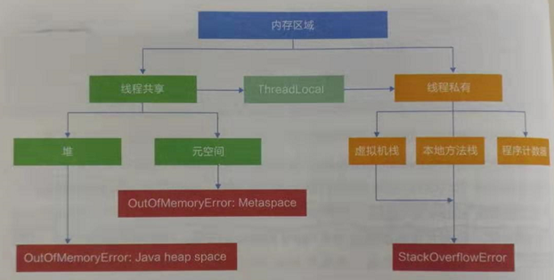
1,Mark-Sweep(標記-清除)算法
先標記出所有需要回收的對象,然后統一回收掉被標記的對象
缺點:標記和清除過程效率不高;
標記和清除后會產生大量不連續的內存碎片,當程序在運行過程中需要分配較大對象的時候,會因為找不到足夠的連續內存而提前觸發一次垃圾回收動作;
2,Copying(復制)算法
將內存分成大小相等的兩塊,每次只使用其中的一塊,當一塊內存用完,就將存活的對象復制到另一塊上,然后把上一塊空間直接清理掉。
因為新生代中的對象98%都是朝生夕死的,所以將內存按照8:1:1的比例分成了三份Eden,S1, S2,先使用其中的Eden,S1,用盡后將存活對象復制到另一個S2上,然后再等Eden和S2用盡后在復制到S1,如此往復。
3,Mark-Compact(標記-整理)算法
先標記需要清除的對象,再將存活的對象都向一端移動,然后清除掉邊界之外的內存 。
4,Generational Collection(分代收集)算法
把java堆分成新生代和老年代,根據各個年代的特點采取最恰當的算法。
1,Serial/Serial Old
Serial/Serial Old收集器是最基本最古老的收集器,它是一個單線程收集器,并且在它進行垃圾收集時,必須暫停所有用戶線程。
Serial收集器是針對新生代的收集器,采用的是Copying算法,Serial Old收集器是針對老年代的收集器,采用的是Mark-Compact算法。
它的優點是實現簡單高效,但是缺點是會給用戶帶來停頓。
2,ParNew
ParNew收集器是Serial收集器的多線程版本,使用多個線程進行垃圾收集。
3,Parallel Scavenge
Parallel Scavenge收集器是一個新生代的多線程收集器(并行收集器),它在回收期間不需要暫停其他用戶線程,其采用的是Copying算法,該收集器與前兩個收集器有所不同,它主要是為了達到一個可控的吞吐量。
4,Parallel Old
Parallel Old是Parallel Scavenge收集器的老年代版本(并行收集器),使用多線程和Mark-Compact算法。
5,CMS
CMS(Current Mark Sweep)收集器是一種以獲取最短回收停頓時間為目標的收集器,它是一種并發收集器,采用的是Mark-Sweep算法。
6,G1
G1收集器是當今收集器技術發展最前沿的成果,它是一款面向服務端應用的收集器,它能充分利用多CPU、多核環境。因此它是一款并行與并發收集器,并且它能建立可預測的停頓時間模型。
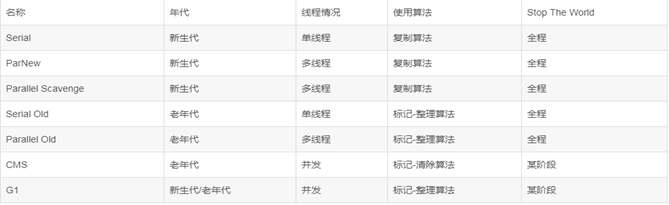
各個收集器明細如下:
關于JAVA中怎么實現內存分布問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





