溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Tensorflow中FocalLoss函數如何使用,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
1、FocalLoss介紹
FocalLoss是在交叉熵函數的基礎上進行的改進,改進的地方主要在兩個地方
(1)、改進第一點如下公式所示。
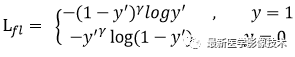
首先在原有交叉熵函數基礎上加了一個權重因子,其中gamma>0,使得更關注于困難的、錯分的樣本。比如:若 gamma = 2,對于正類樣本來說,如果預測結果為0.97,那么肯定是易分類的樣本,權重值為0.0009,損失函數值就會很小了;對于正類樣本來說,如果預測結果為0.3,那么肯定是難分類的樣本,權重值為0.49,其損失函數值相對就會很大;對于負類樣本來說,如果預測結果為0.8,那么肯定是難分類的樣本,權重值為0.64,其損失函數值相對就會很大;對于負類樣本來說,如果預測結果為0.1,那么肯定是易分類的樣本,權重值為0.01,其損失函數值就會很小。而對于預測概率為0.5時,損失函數值只減少了0.25倍,所以FocalLoss減少了簡單樣本的影響從而更加關注于難以區分的樣本。
(2)、改進第二點如下公式所示。
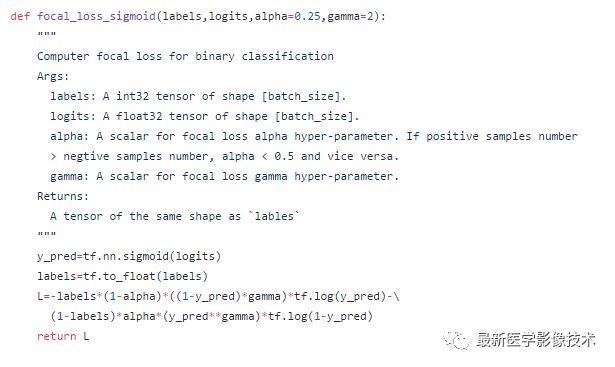
下面將簡單推導一下FocalLoss函數在二分類時的函數表達式。
FocalLoss函數可以表示如下公式所示:
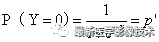
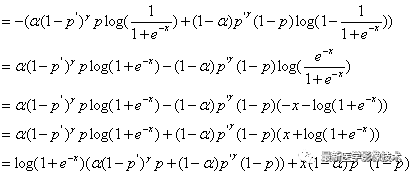
3、FocalLoss代碼實現
按照上面導出的表達式FocalLoss的偽代碼可以表示為:
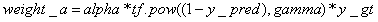

從這里可以看到1-y_pred項可能為0或1,這會導致log函數值出現NAN現象,所以好需要對y_pred項進行固定范圍值的截斷操作。最后在TensorFlow1.8下實現了該函數。
import tensorflow as tfdef focal_loss(y_true, y_pred, alpha=0.25, gamma=2):epsilon = 1e-5y_pred = tf.clip_by_value(y_pred, epsilon, 1 - epsilon)logits = tf.log(y_pred / (1 - y_pred))weight_a = alpha * tf.pow((1 - y_pred), gamma) * y_trueweight_b = (1 - alpha) * tf.pow(y_pred, gamma) * (1 - y_true)loss = tf.log1p(tf.exp(-logits)) * (weight_a + weight_b) + logits * weight_breturn tf.reduce_mean(loss)
關于Tensorflow中FocalLoss函數如何使用就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





