溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Python如何使用Requests抓取包圖網小視頻”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
分析網頁數據結構
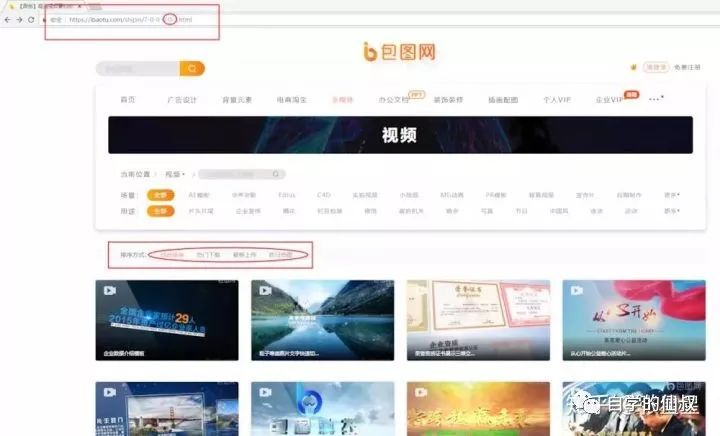
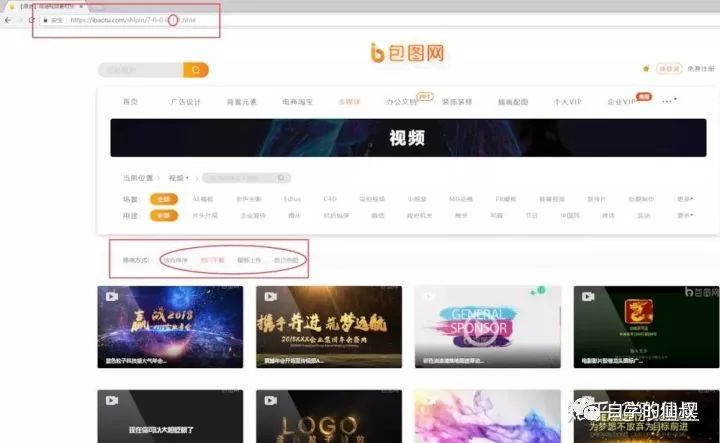
經分析我們可以發現總站數據我們可以從這四這選項下手
分析網頁數據格式
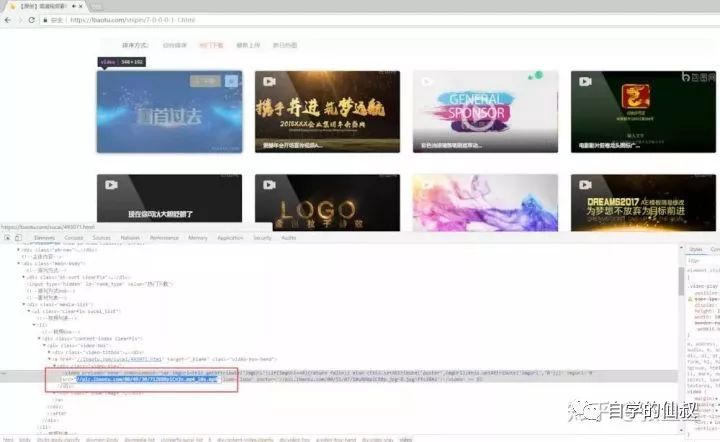
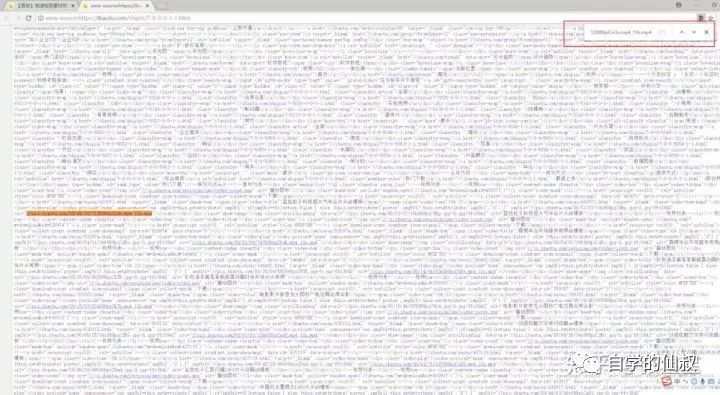
image.png
網頁數據為靜態
抓取下一頁鏈接
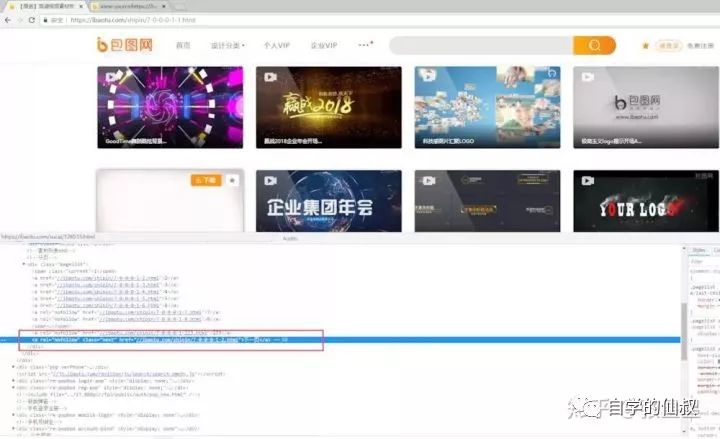
抓取下一頁鏈接
OK, 上代碼!
import requests
from lxml import etree
import threading
class Spider(object):
def __init__(self):
self.headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"}
self.offset = 1
def start_work(self, url):
print("正在爬取第 %d 頁......" % self.offset)
self.offset += 1
response = requests.get(url=url,headers=self.headers)
html = response.content.decode()
html = etree.HTML(html)
video_src = html.xpath('//div[@class="video-play"]/video/@src')
video_title = html.xpath('//span[@class="video-title"]/text()')
next_page = "http:" + html.xpath('//a[@class="next"]/@href')[0]
# 爬取完畢...
if next_page == "http:":
return
self.write_file(video_src, video_title)
self.start_work(next_page)
def write_file(self, video_src, video_title):
for src, title in zip(video_src, video_title):
response = requests.get("http:"+ src, headers=self.headers)
file_name = title + ".mp4"
file_name = "".join(file_name.split("/"))
print("正在抓取%s" % file_name)
with open(file_name, "wb") as f:
f.write(response.content)
if __name__ == "__main__":
spider = Spider()
for i in range(0,3):
# spider.start_work(url="https://ibaotu.com/shipin/7-0-0-0-"+ str(i) +"-1.html")
t = threading.Thread(target=spider.start_work, args=("https://ibaotu.com/shipin/7-0-0-0-"+ str(i) +"-1.html",))
t.start()
運行結果
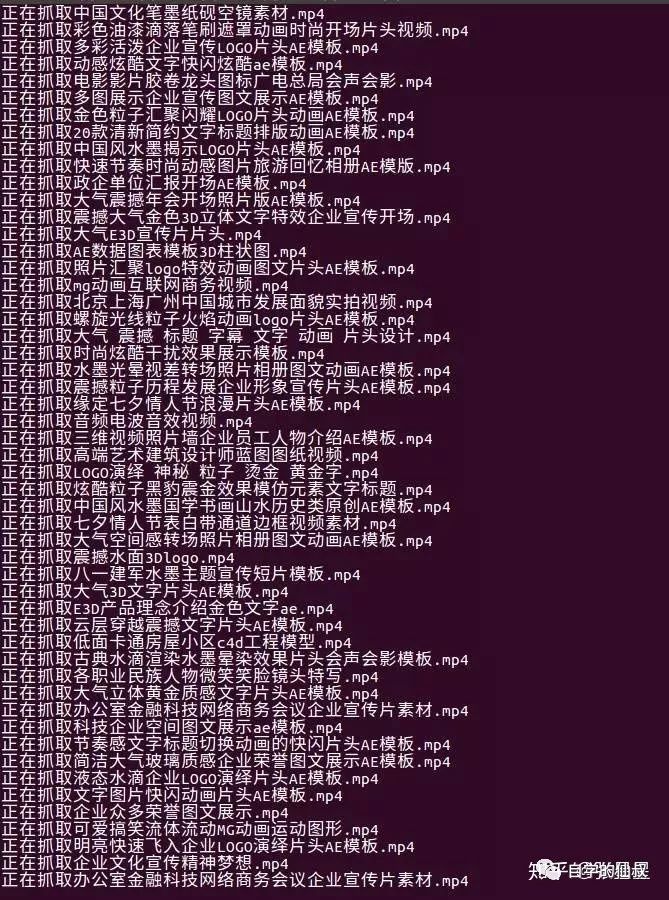
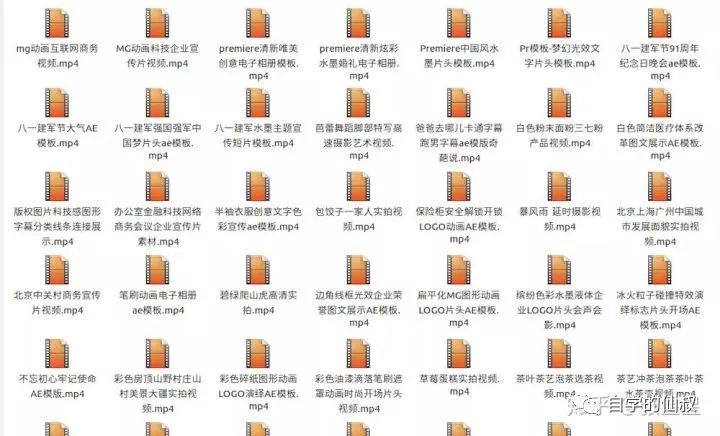
是不是很簡單呢!
“Python如何使用Requests抓取包圖網小視頻”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





