溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
電競大數據時代,數據對比賽的觀賞性和專業性都起到了至關重要的作用。同樣的,這也對電競數據的豐富性與實時性提出了越來越高的要求。
電競數據的豐富性從受眾角度來看,可分為賽事、戰隊和玩家數據;從游戲角度來看,維度可由英雄、戰斗、道具以及技能等組成;電競數據的實時性包括賽前兩支戰隊的歷史交戰記錄、賽中的實時比分、勝率預測、賽后比賽分析和英雄對比等。
如果你想了解大數據的學習路線,想學習大數據知識以及需要免費的學習資料可以加群:784789432.歡迎你的加入。每天下午三點開直播分享基礎知識,晚上20:00都會開直播給大家分享大數據項目實戰。
如果你還是認為寫博客浪費時間,請參考Dave Robinson撰寫的相關文
因此多維度的數據支持,TB到PB級別的海量數據存儲與實時分析都對底層系統的架構設計有著更高的要求,亦帶來了更嚴峻的挑戰。
本文將介紹電競數據平臺FunData架構演進中的設計思路及相關技術,包括×××處理方案、結構化存儲轉非結構化存儲方案和數據API服務設計等。在其v1.0 beta版本中,FunData為頂級MOBA類游戲DOTA2(由Valve公司出品)提供了相關的數據接口。
1.0架構
項目發展初期,依照MVP理論(最小化可行產品),我們迅速推出FunData的第一版系統(架構圖如圖1)。系統主要有兩個模塊:Master與Slave。
圖1 1.0ETL架構圖
Master模塊功能如下:
定時調用Steam接口獲取比賽ID與基礎信息;
通過In-Memory的消息隊列分發比賽分析任務到Slave節點;
記錄比賽分析進度,并探測各Slave節點狀態。
Slave模塊功能如下:
監聽隊列消息并獲取任務,任務主要為錄像分析,錄像分析參考GitHub項目Clarity與Manta;
分析數據入庫。
系統上線初期運行相對穩定,各維度的數據都可快速拉取。然而隨著數據量的增多,數據與系統的可維護性問題卻日益突出:
新增數據字段需要重新構建DB索引,數據表行數過億構建時間太長且造成長時間鎖表;
系統耦合度高,不易于維護,Master節點的更新重啟后,Slave無重連機制需要全部重啟;同時In-Memory消息隊列有丟消息的風險;
系統可擴展性低,Slave節點擴容時需要頻繁的制作虛擬機鏡像,配置無統一管理,維護成本高;
DB為主從模式且存儲空間有限,導致數據API層需要定制邏輯來分庫讀取數據做聚合分析;
節點粒度大,Slave可能承載的多個分析任務,故障時影響面大。
在開始2.0架構設計與改造前,我們嘗試使用冷存儲方法,通過遷移數據的方式來減輕系統壓力(架構設計如圖2)。由于數據表數據量太大,并發多個數據遷移任務需要大量時間,清理數據的過程同樣會觸發重新構建索引,方案的上線并沒有根本性地解決問題。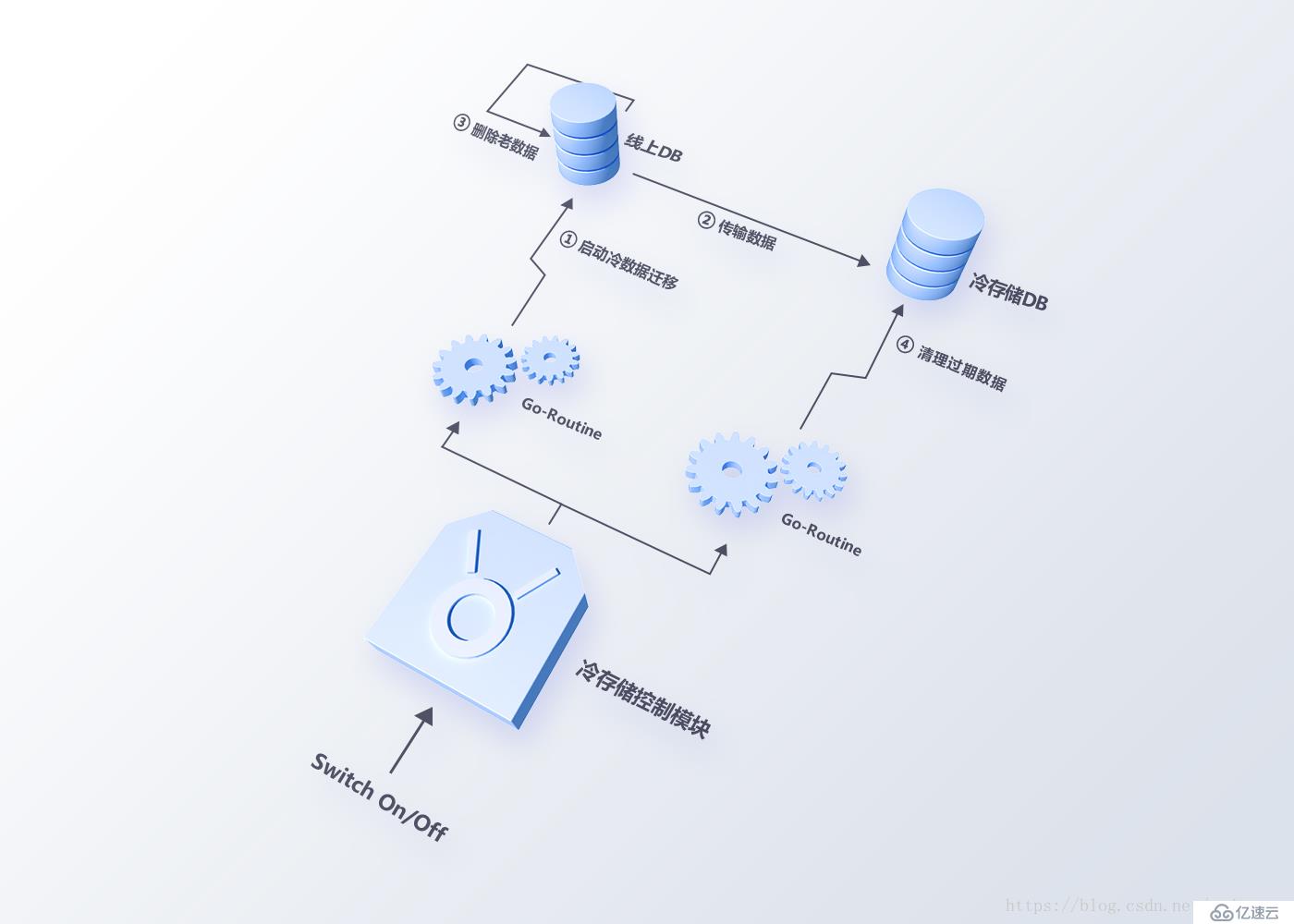
圖2 冷存儲方案
2.0架構
吸取1.0系統的經驗,在2.0架構設計(架構圖如圖3)中,我們從維護性、擴展性和穩定性三個方面來考慮新數據系統架構應該具備的基本特性:
數據處理任務粒度細化,且支持高并發處理(全球一天DOTA2比賽的場次在120萬場,錄像分析相對耗時,串行處理會導致任務堆積嚴重);
數據分布式存儲;
系統解耦,各節點可優雅重啟與更新。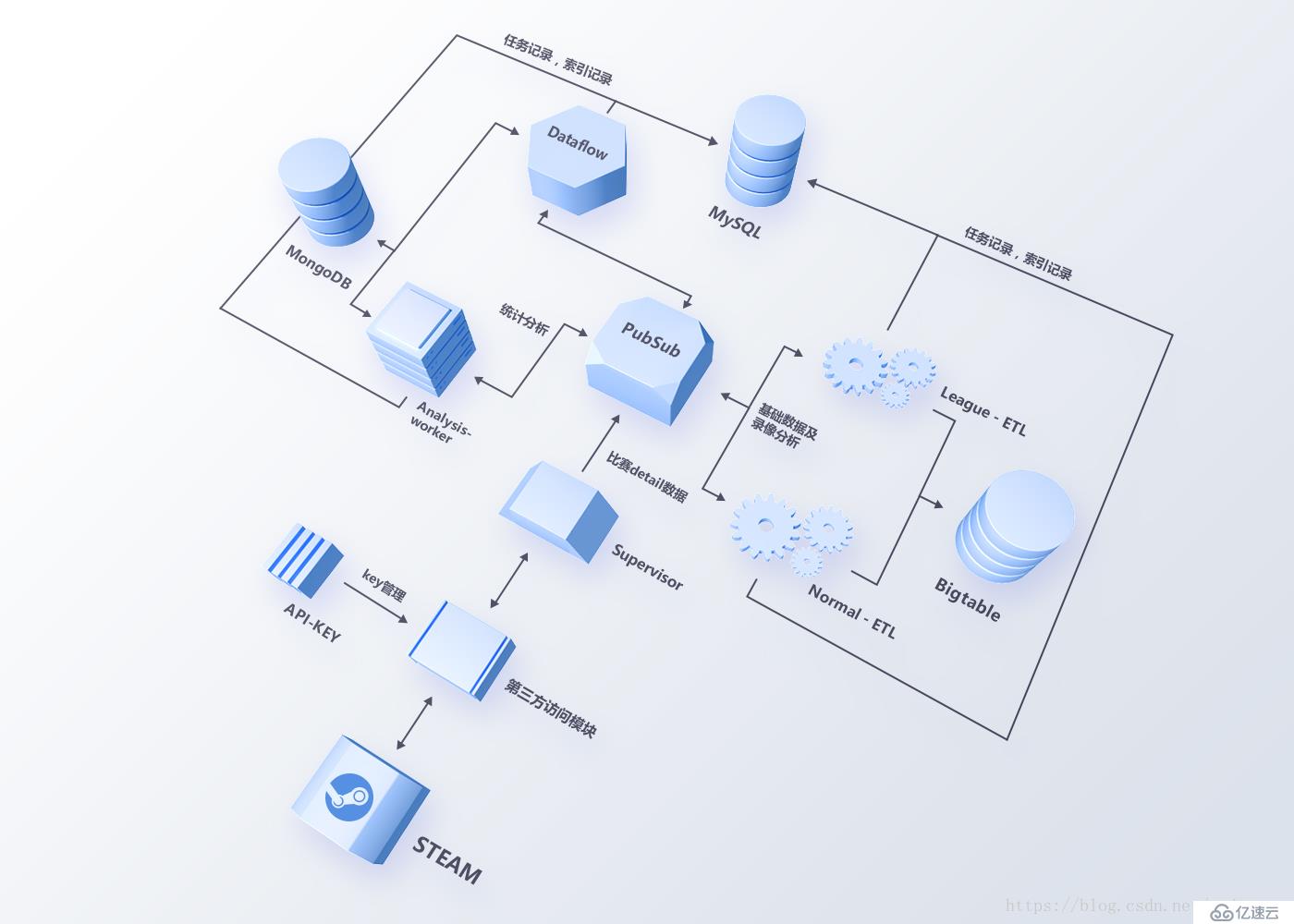
圖3 2.0ETL總架構圖
2.0系統選擇Google Cloud Platform來構建整個數據ETL系統,利用PubSub(類似Kafka)作為消息總線,任務被細化成多個Topic進行監聽,由不同的Worker進行處理。這樣一方面減少了不同任務的耦合度,防止一個任務處理異常導致其他任務中斷;另一方面,任務基于消息總線傳遞,不同的數據任務擴展性變得更好,性能不足時可快速橫向擴展。
任務粒度細化
從任務粒度上看(如圖3),數據處理分為基礎數據處理與高階數據處理兩部分。基礎數據,即比賽的詳情信息(KDA、傷害與補刀等數據)和錄像分析數據(Roshan擊殺數據、傷害類型與英雄分路熱力圖等數據)由Supervisor獲取Steam數據觸發,經過worker的清理后存入Google Bigtable;高階數據,即多維度的統計數據(如英雄、道具和團戰等數據),在錄像分析后觸發,并通過GCP的Dataflow和自建的分析節點(worker)聚合,最終存入MongoDB與Google Bigtable。
從Leauge-ETL的細化架構看(如圖4),原有的單個Slave節點被拆分成4個子模塊,分別是聯賽數據分析模塊、聯賽錄像分析模塊、分析/挖掘數據DB代理模塊和聯賽分析監控模塊。
聯賽數據分析模塊負責錄像文件的拉取(Salt、Meta文件與Replay文件的獲取)與比賽基本數據分析;
聯賽錄像分析模塊負責比賽錄像解析并將分析后數據推送至PubSub;
分析/挖掘數據DB代理負責接收錄像分析數據并批量寫入Bigtable;
聯賽分析監控模塊負責監控各任務進度情況并實時告警。
同時所有的模塊選擇Golang重構,利用其“天生”的并發能力,提高整個系統數據挖掘和數據處理的性能。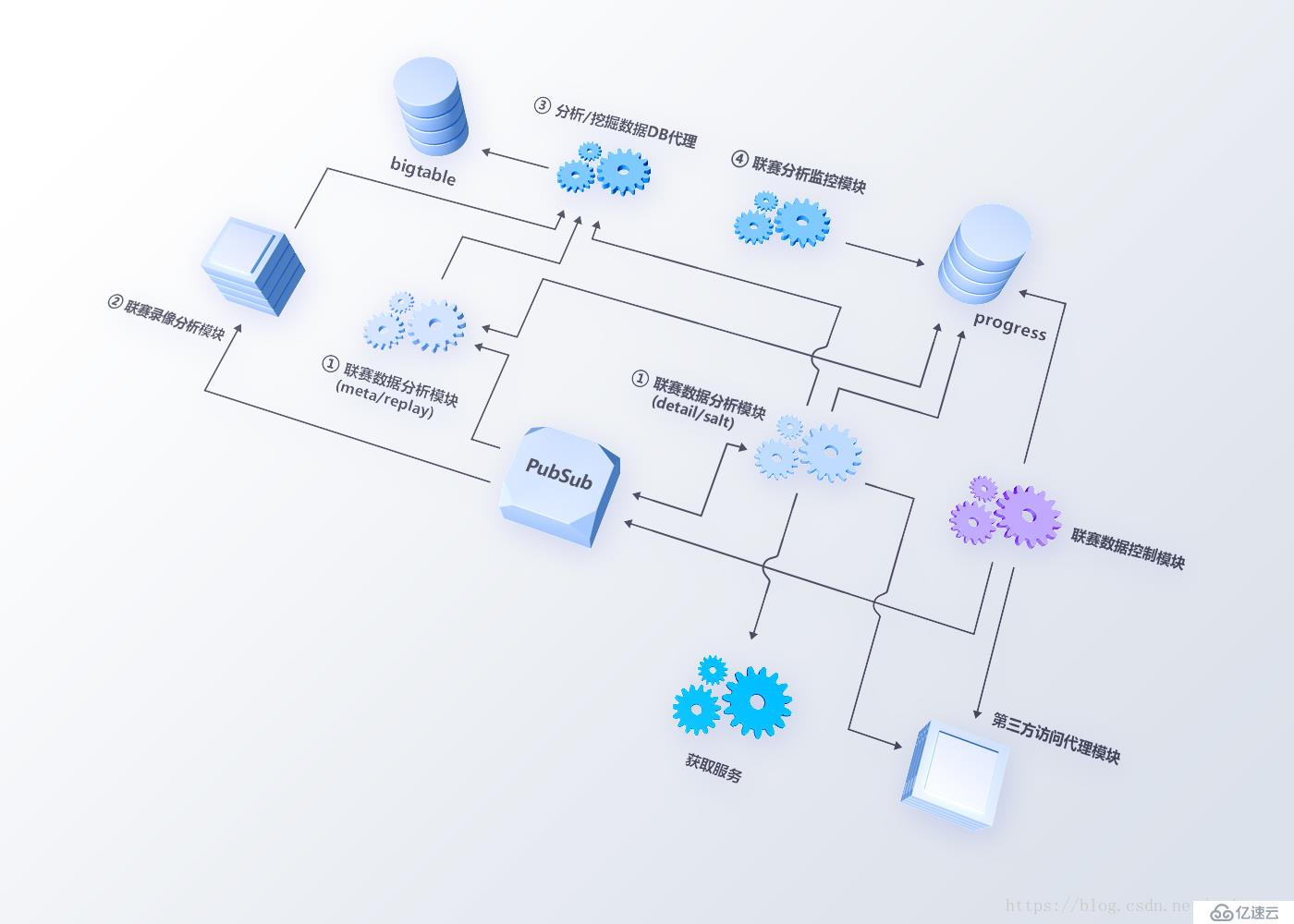
圖4 League-ETL架構
分布式存儲
如上文提到,1.0架構中我們使用MySQL存儲大量比賽數據及錄像分析數據。MySQL在大數據高并發的場景下,整體應用的開發變得越來越復雜,如無法支持schema經常變化,架構設計上需要合理地考慮分庫分表的時機,子庫的數據到一定量級時面臨的擴展性問題。
參考Google的Bigtable,作為一種分布式的、可伸縮的大數據存儲系統,Bigtable與HBase能很好的支持數據隨機與實時讀寫訪問,更適合FunData數據系統的數據量級和復雜度。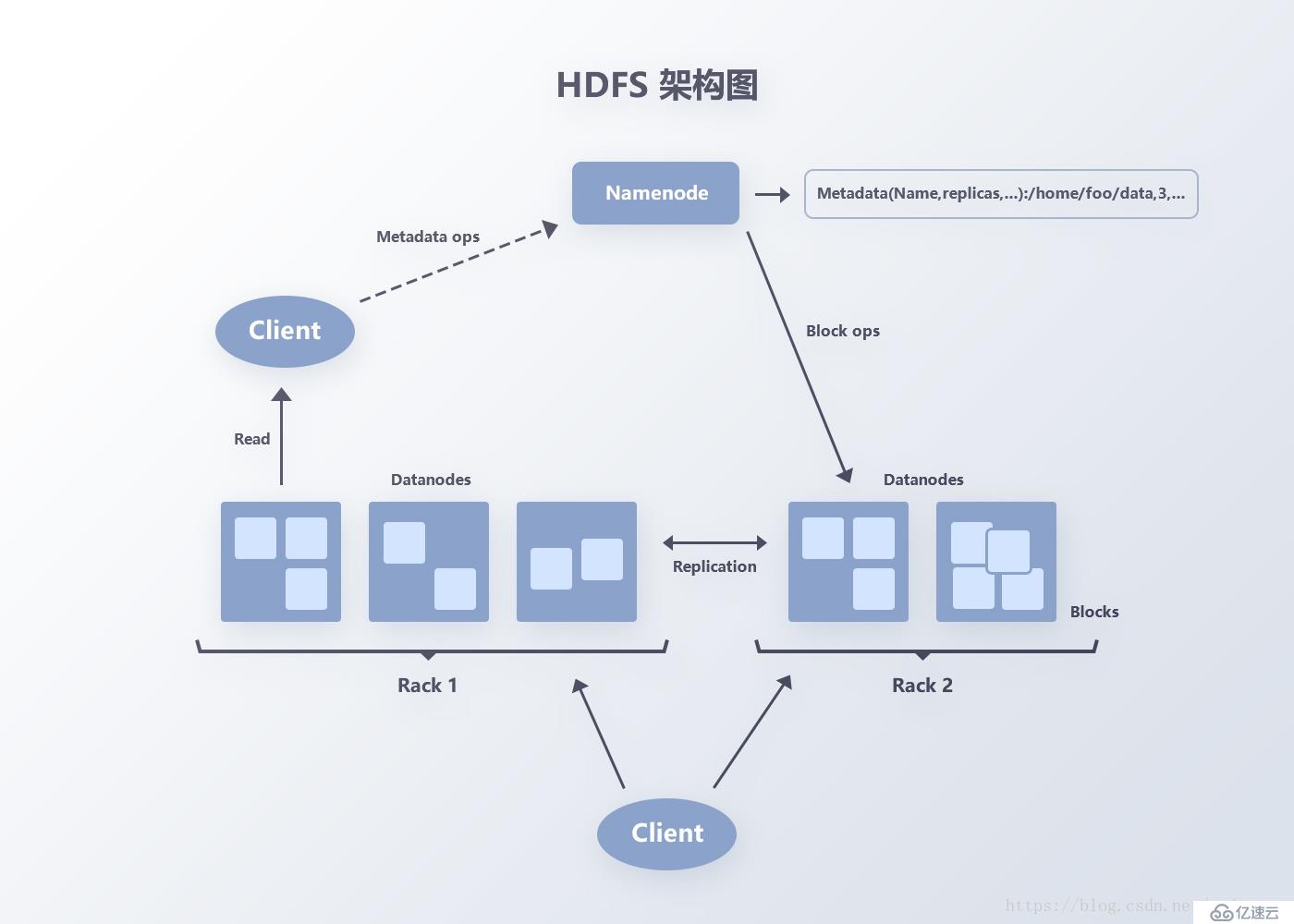
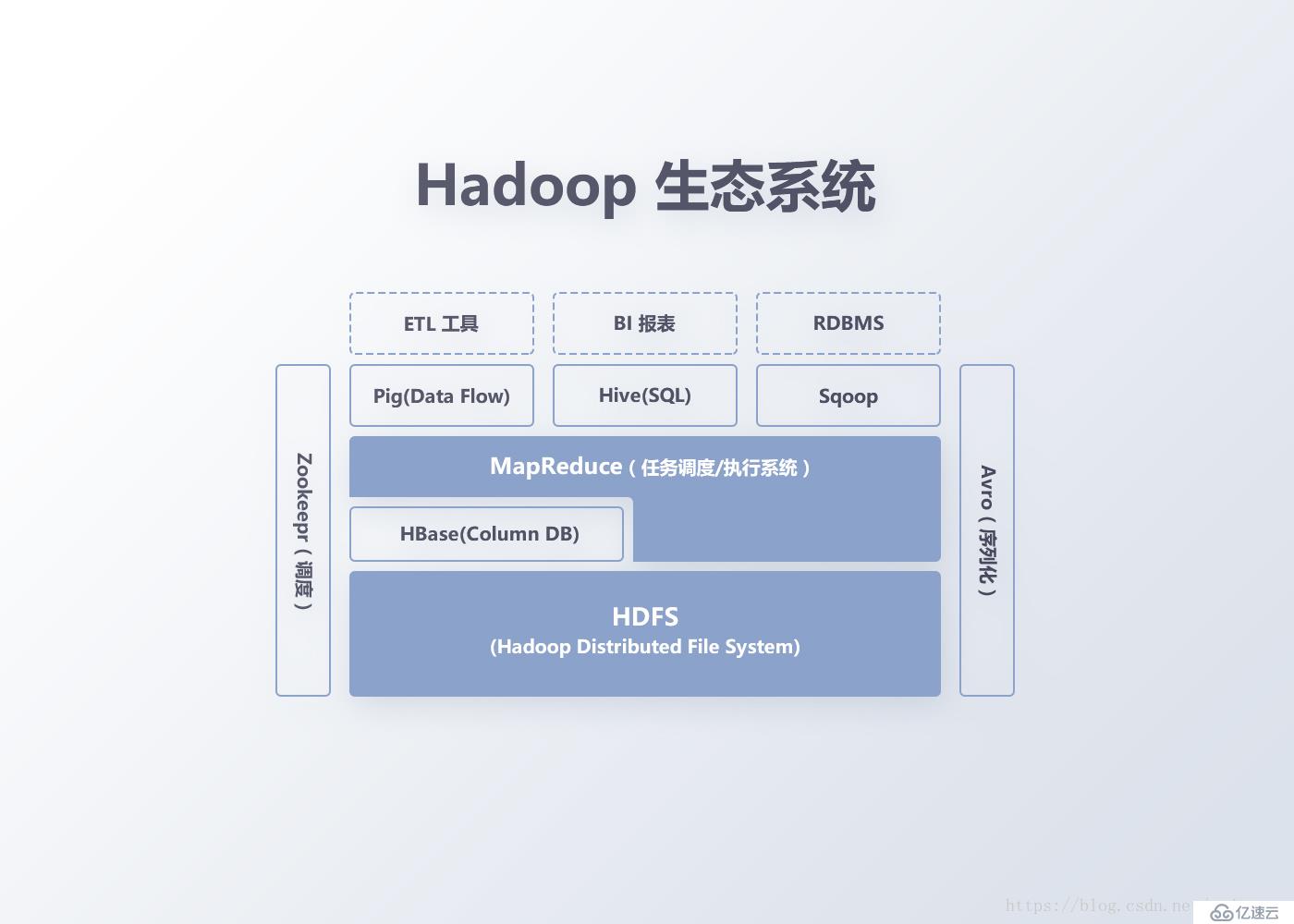
圖5 Hadoop生態
在數據模型上,Bigtable與HBase通過RowKey、列簇列名及時間戳來定位一塊數據(Cell,如圖6)。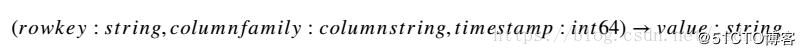
圖6 數據索引
例如,在FunData數據系統中,比賽數據的RowKey以hash_key+match_id的方式構建,因為DOTA2的match_id是順序增大的(數值自增量不唯一),每個match_id前加入一致性哈希算法算出的hash_key,可以防止在分布式存儲中出現單機熱點的問題,提升整個存儲系統的數據負載均衡能力,做到更好的分片(Sharding),保障后續DataNode的擴展性。
如圖7,我們在hash環上先預設多個key值作為RowKey的前綴,當獲取到match_id時,通過一致性哈希算法得到match_id對應在hash環節點的key值,最后通過key值與match_id拼接構建RowKey。
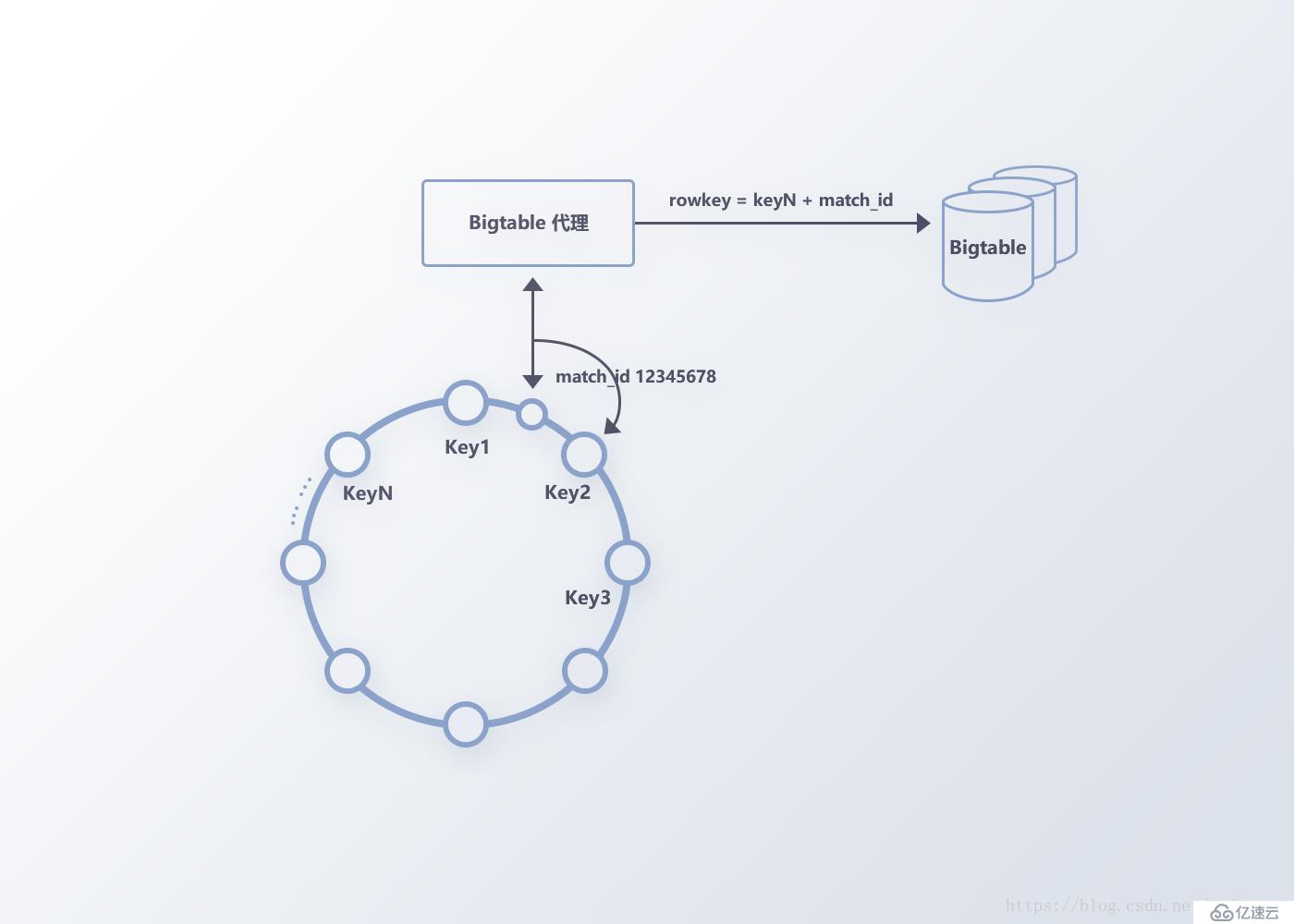
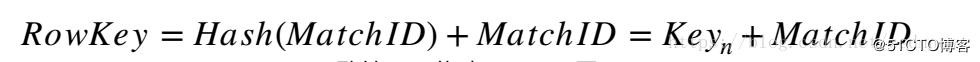
圖7 一致性hash構建RowKey
時間戳的使用方便我們在聚合數據時對同一個RowKey和Column的數據重復寫入,HBase/Bigtable內部有自定的GC策略,對于過期的時間戳數據會做清理,讀取時取最新時間節點的數據即可。
這里大家可能會有個疑問,Bigtable與HBase只能做一級索引,RowKey加上hash_key之后,是無法使用row_range的方式批量讀或者根據時間為維度進行批量查詢的。在使用Bigtable與HBase的過程中,二級索引需要業務上自定義。在實際場景里,我們的worker在處理每個比賽數據時,同時會對時間戳-RowKey構建一次索引并存入MySQL,當需要基于時間批量查詢時,先查詢索引表拉取RowKey的列表,再獲取對應的數據列表。
在數據讀寫上,Bigtable/HBase與MySQL也有很大的不同。一般MySQL使用查詢緩存,Schema更新時緩存會失效,另外查詢緩存是依賴全局鎖保護,緩存大量數據時,如果查詢緩存失效,會導致表鎖死。
如圖8,以HBase為例,讀取數據時,client先通過zookeeper定位到RowKey所在的RegionServer,讀取請求達到RegionServer后,由RegionServer來組織Scan的操作并最終歸并查詢結果返回數據。因為一次查詢操作可能包括多個RegionServer和多個Region,數據的查找是并發執行的且HBase的LRUBlockCache,數據的查詢不會出現全部鎖死的情況。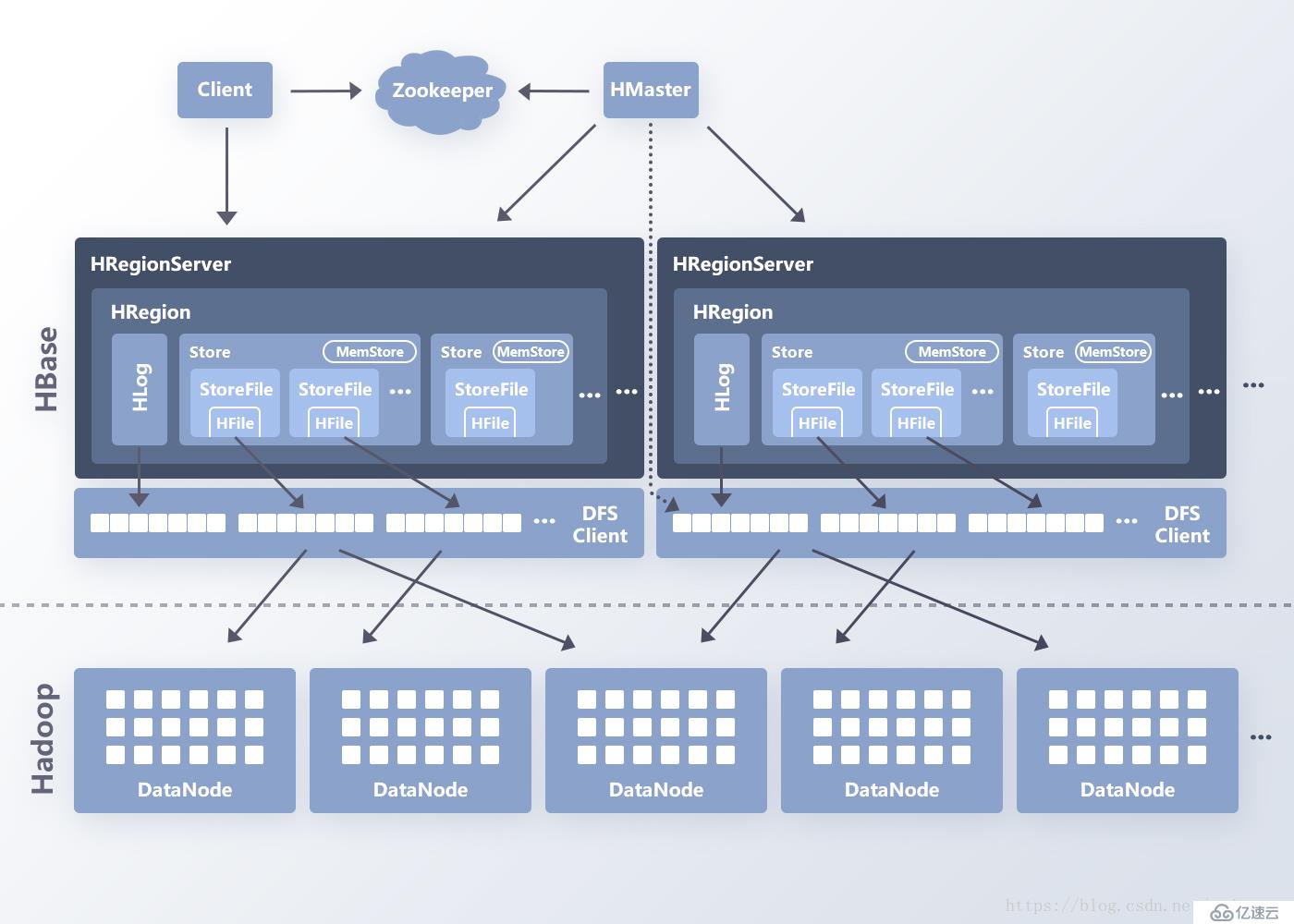
圖8 HBase架構
基于新的存儲架構,我們的數據維度從單局比賽擴展到了玩家、英雄、聯賽等,如圖9。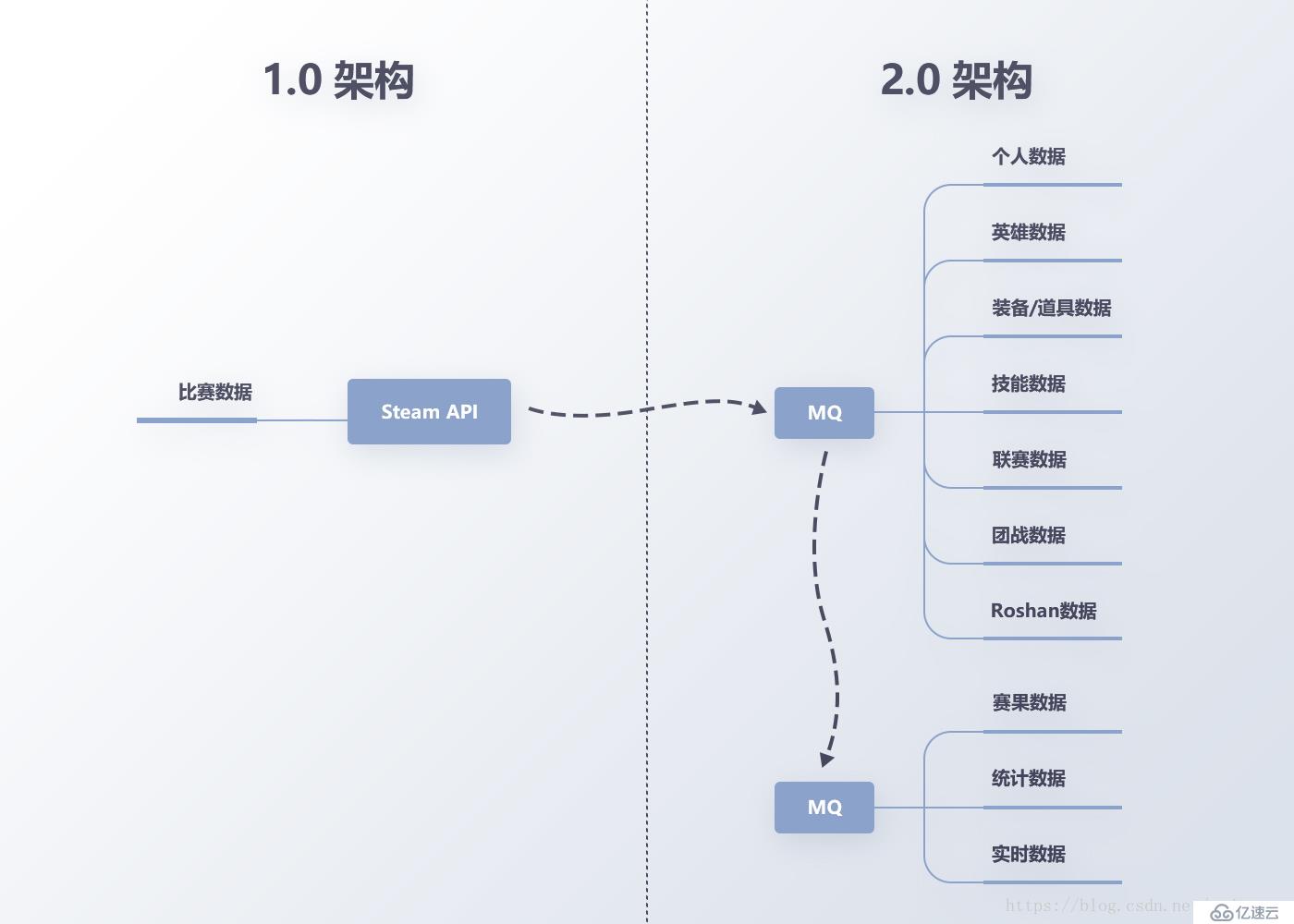
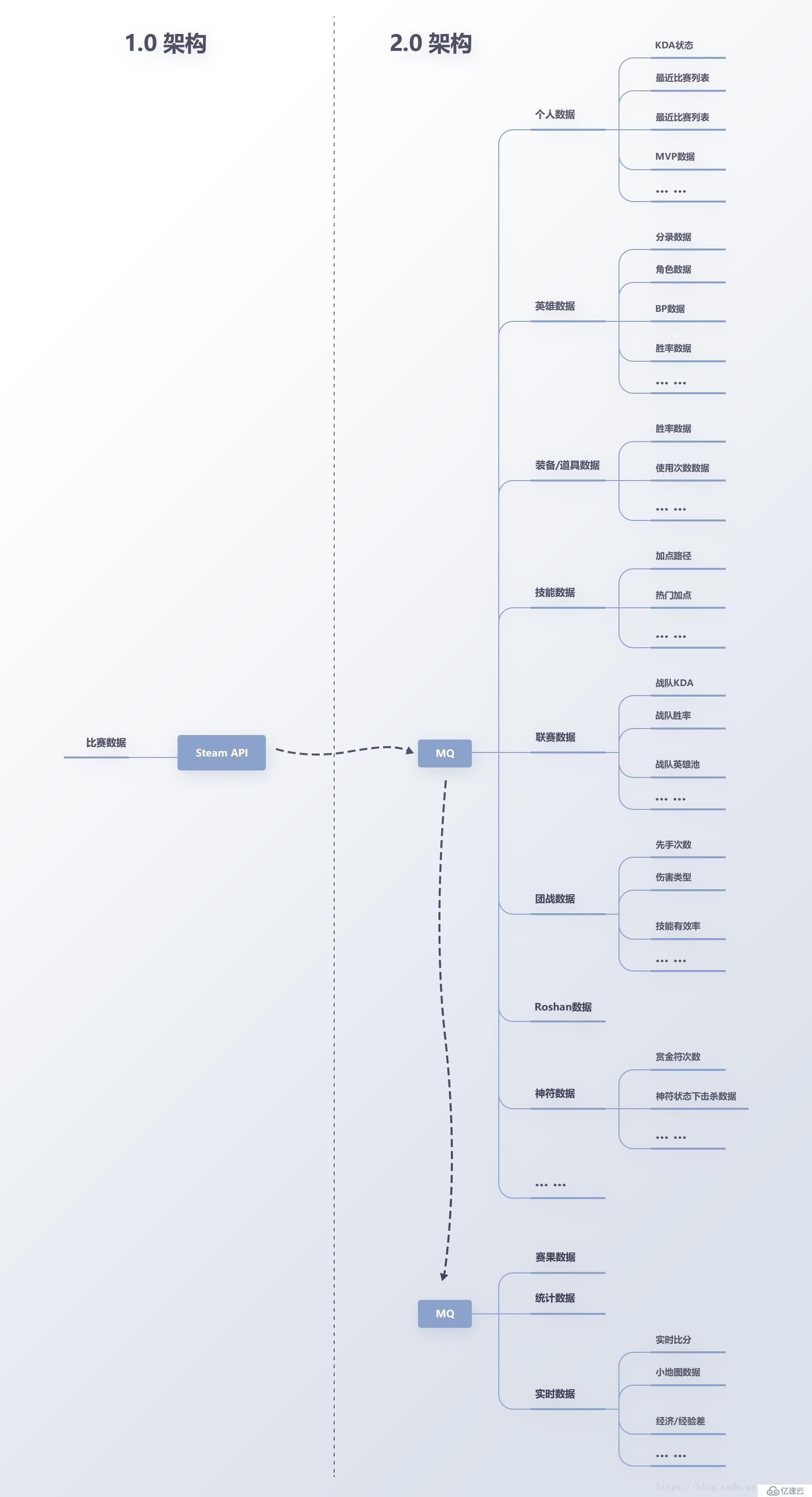
圖9 數據維度
系統解耦
上文我們提到1.0架構中使用In-Memory的消息隊列做數據傳遞,由于內存中隊列數據沒有持久化存儲并與Master模塊強耦合,Master節點更新或者異常Panic后會導致數據丟失,且恢復時間冗長。因此,在2.0架構中采用了第三方的消息隊列作為消息總線,保障系統“上下游”節點解耦,可多次迭代更新,歷史消息變得可追蹤,基于云平臺消息堆積也變得可視化(如圖10)。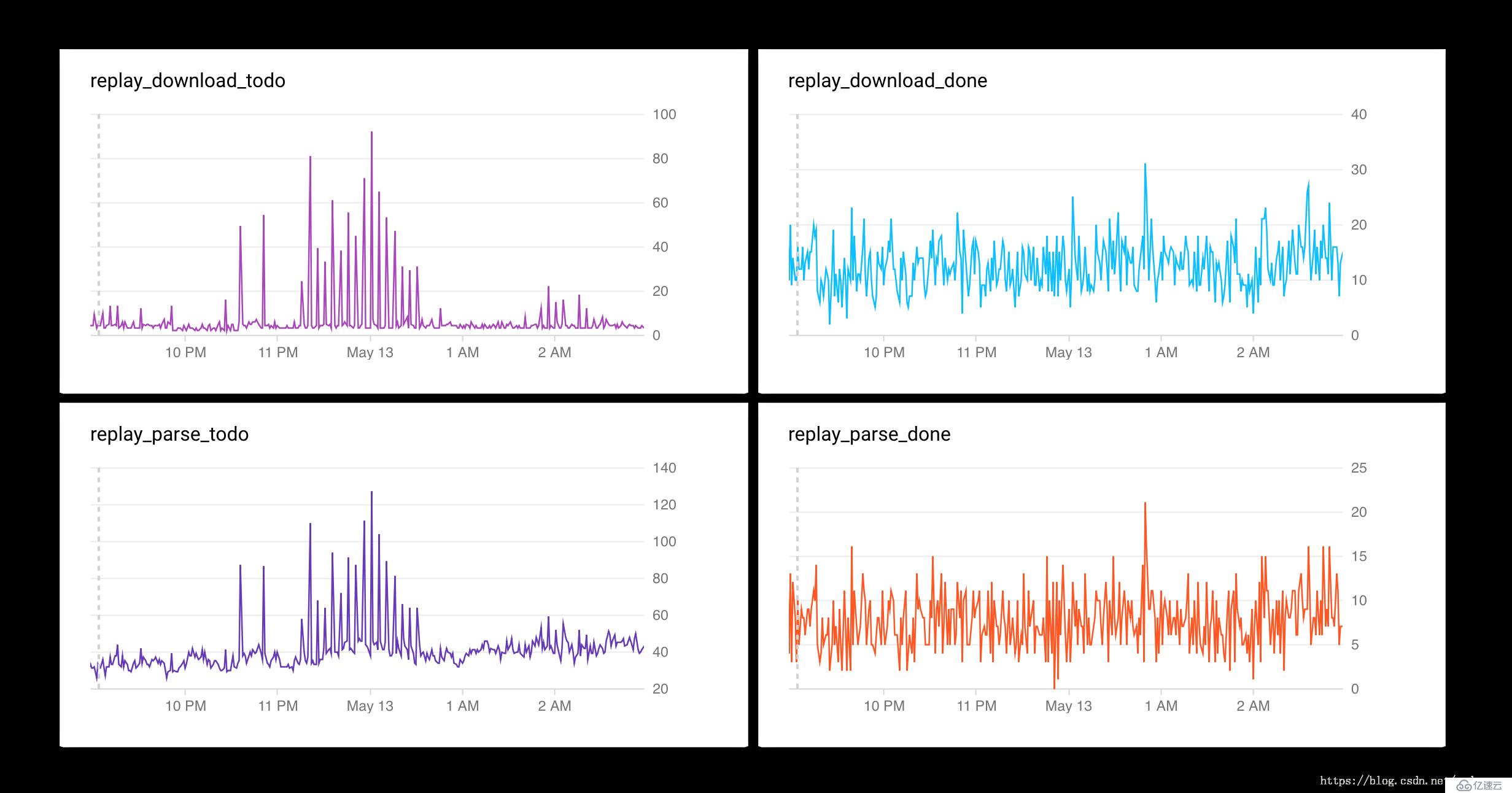
圖10 數據監控
數據API層
1.0系統的數據API層為實現快速上線,在架構上未做太多的設計與優化,采用域名的方式實現負載均衡,并使用開源的DreamFactory搭建的ORM層,利用其RESTful的接口做數據訪問。
該架構在開發和使用過程中遇到許多問題:
API層部署在國內阿里云上,數據訪問需要跨洋;
ORM層提供的API獲取表的全字段數據,數據粒度大;
無緩存,應對大流量場景(如17年震中杯與ESL)經常出現服務不可用;
多DB的數據聚合放在了API層,性能不足;
服務更新維護成本高,每次更新需要從域名中先剔除機器。
針對上述問題,我們從兩個方面重構了1.0數據API層,如圖11。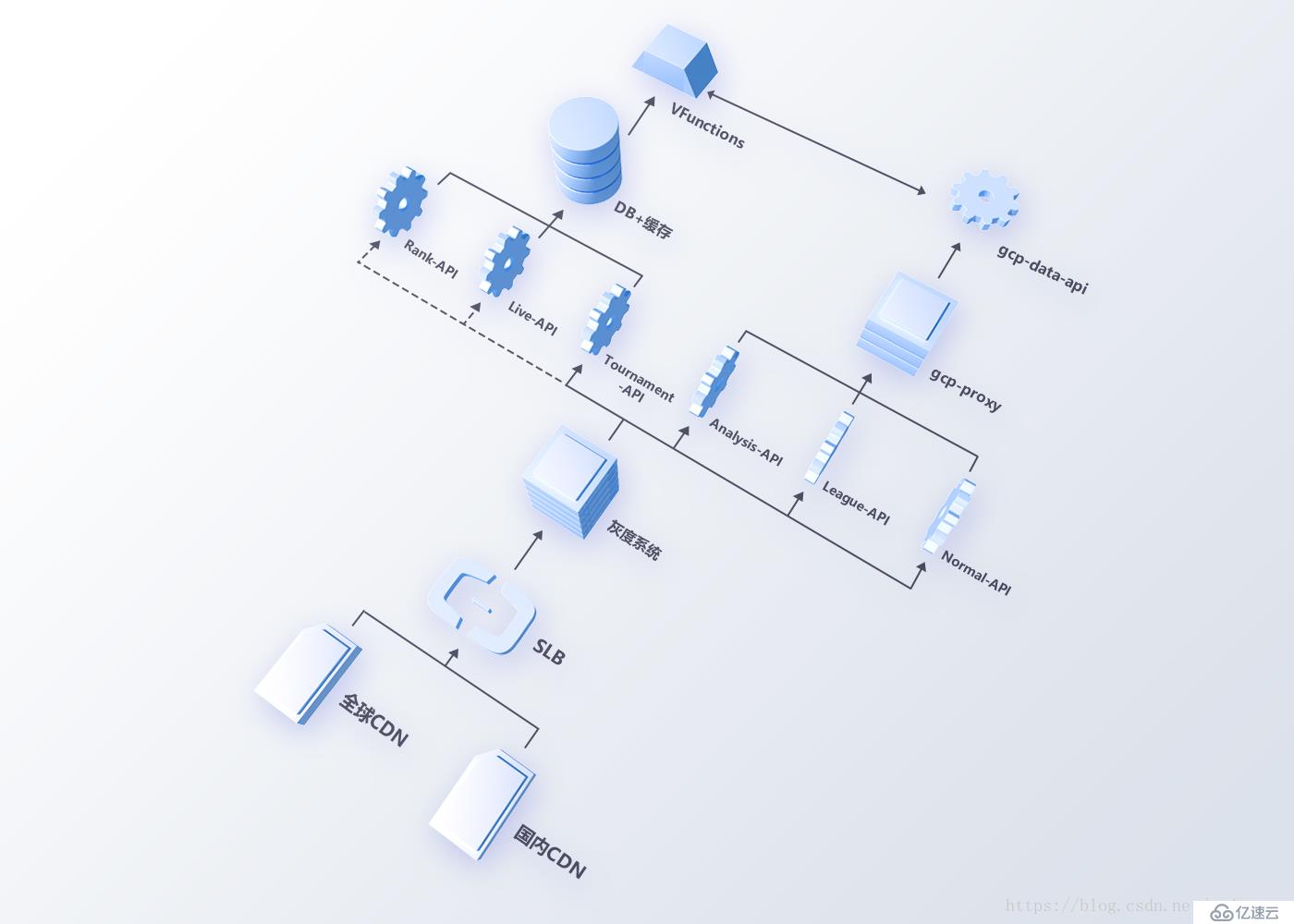
圖11 數據API新架構
鏈路的穩定性
全球鏈路上,我們使用CDN動態加速保證訪問的穩定性。同時利用多云廠商CDN做備份容災,做到秒級切換。
在調度能力和恢復能力上,我們搭建了自己的灰度系統,將不同維度的數據請求調度到不同的數據API,減少不同維度數據請求量對系統的影響;借助灰度系統,API服務更新的風險和異常時的影響面也被有效控制。依賴云平臺可用區的特性,灰度系統也能方便地實現后端API服務跨可用區,做到物理架構上的容災。
另外,為保證內部跨洋訪問鏈路的穩定性,我們在阿里云的北美機房搭建數據代理層,利用海外專線來提升訪問速度。
數據高可用性
接入分布式存儲系統后,對外數據API層也根據擴展的數據維度進行拆分,由多個數據API對外提供服務,例如比賽數據和聯賽賽程等數據訪問量大,應該與英雄、個人及道具數據分開,防止比賽/賽事接口異常影響所有數據不可訪問。
針對熱點數據,內部Cache層會做定時寫入緩存的操作,數據的更新也會觸發Cache的重寫,保障賽事期間的數據可用。
結語
本文介紹了FunData數據平臺架構演進的過程,分析了舊系統在架構上的缺點,以及在新系統中通過什么技術和架構手段來解決。
FunData自4月10日上線以來,已有300多位技術開發者申請了API-KEY。目前也在著力于新數據點的快速迭×××發,如聯賽統計數據。比賽實時數據等。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





