溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關調整查詢代價的數據庫PostgreSQL怎么用,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
大部分數據庫對于查詢中的Cost 評估的代價指標是不能進行變更的,假設如果我的系統從10000轉的磁盤,變換為每秒能提供 1366MB/S 的SSD 查詢評估的方法還是老的方法,這樣對于數據庫系統的查詢性能有多少幫助?
那到底PG 在這方面有什么特異功能,我們往下看,在這之前我們也需要知道PG 也是這些數據庫中唯一的一個不能在語句中強制添加,并強制讓他走索引
或不走索引的數據庫。(pg_hint_plan可以解決這個問題)
下面就是一個查詢中查看cost 的方法

下面我們更深入一點,從下面的兩個圖我看可以看出些什么,第一個圖我們可以看到查詢執行計劃中Starup cost 是 0
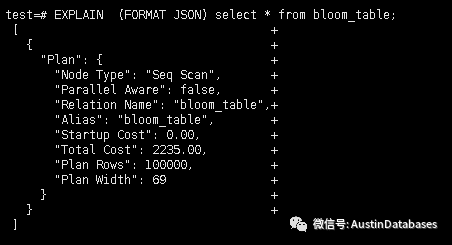
下邊這個查詢的查詢計劃startup cost 中整體的cost 和 startup cost 是差不多的。
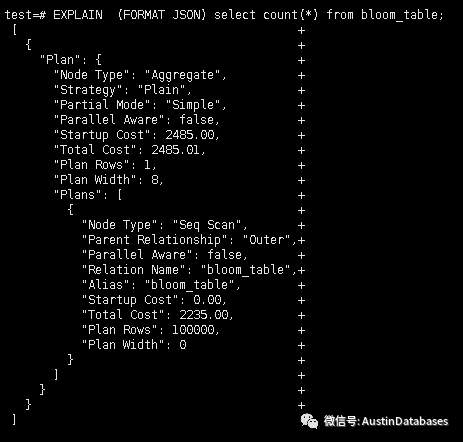
實際上 total cost 等于啟動cost + 運行cost
另外以第一個列子為例,順序掃描是沒有 startup cost的,僅僅有 operation cost

總體的cost 是 2235 到底這個 2235 是怎么來的

我看一下bloom_table 的表行數和占用的PAGE 數。
通過以下公式 運行cost = (cpu 運行的cost + 磁盤的運行cost ) * 多少行 + 順序掃描的每頁消耗 * 多少頁面
(0.01 + 0.0025) * 100000 + 1.0 * 1235 =1250 +1235 = 2235
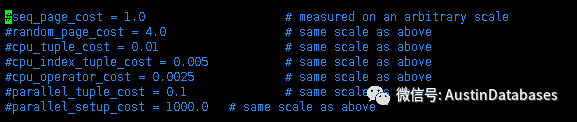
其中 0.01 0.0025 1 分別是從上面圖中的
seq_page_cost = 1.0
cpu_tuple_cost = 0.01
cpu_operator_cost = 0.0025
獲得的,這也就說明一個語句的cost 是可以通過調整系統中的參數而進行變化的,其他的數據庫在這方面基本上是不開放的。
下面我們在看看如果走了索引會怎么算cost

走索引的cost 會包含啟動成本,從讀取索引的第一個tuple 開始,
開始的代價(走索引) = 取整{log(2)(走了多少索引的行) +( Hindex + 1) * 50} * CPU 運行的消耗

相關的消耗= 取整 (log2 100000 + (2+1)* 50)* 0.0025 = 0.42 (約等于實際是0.4175)
這里面有兩個問題,1 HINDEX 到底是這么來的,這里面指的是索引的樹高,其實可以通過這個公式來推出你的索引樹有多高
運行的代價 (索引使用的CPU 代價 + 表使用CPU的代價) + (index_io 代價 + 表的io 代價)
在計算索引的代價中會涉及到選擇率的問題,意思就是查詢的謂詞的頻率的估計。
下面就是通過SQL 語句來給出每行的值來計算一個“采樣率”的東西,也就是告訴你,這個行的值在整體的表中的占比。
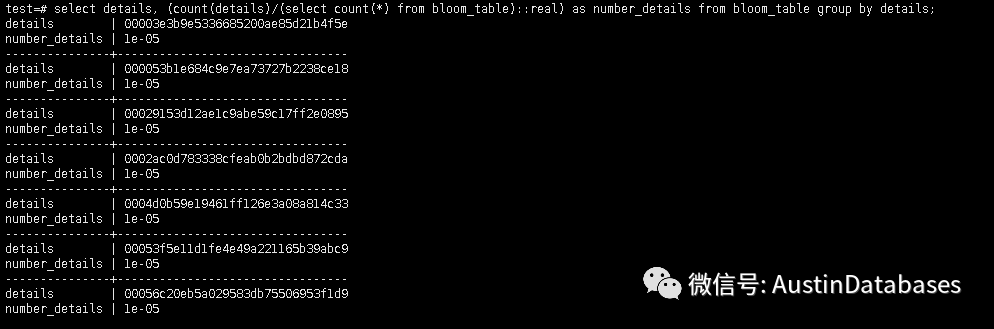
這里由于計算比較麻煩,就不進行計算了,但這里需要注意的是
random_page_cost = 4.0 ,這個是在查詢中使用索引計算 index_io_cost的一個標量,通過選擇率 * index的page的數量 * random_page_cost 就可以得出索引的io cost ,而到底是走索引還是走全表掃描,執行計劃會進行比對,如果走全表掃描會計算最小和最大的io cost,例如最大的 io_cost = 頁面的數量 * random_page_cost
所以調整 random_page_cost 的值會影響到底是走索引還是走全表掃描的選擇性。
下面可以舉一個例子,我將配置文件中的random_page_cost 和 cpu_index_tuple_cost 進行調整,一個調小 一個調大,可以看到下圖的結果,就算我有10萬條記錄,并且我查詢的條件中的字段10萬條那條都和那條不一樣,并且也建立了相關的索引,最終的結果還是進行了全表掃描。

在將兩個參數還原后,還是繼續走原來的索引

說了這么多其實回到我開頭說的問題,如果你的磁盤系統已經更改到SSD 磁盤則你的某些值是需要改變,否則可能會出現一些明明索引很好,但他選擇全表掃描的情況。
關于調整查詢代價的數據庫PostgreSQL怎么用就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





