溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了Flink使用大狀態時的優化是什么,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
一、為什么要優化?(優化背景)
Flink 支持多種 StateBackend,當狀態比較大時目前只有 RocksDBStateBackend 可供選擇。
RocksDB 是基于 LSM 樹原理實現的 KV 數據庫,LSM 樹讀放大問題比較嚴重,因此對磁盤性能要求比較高,強烈建議生產環境使用 SSD 作為 RocksDB 的存儲介質。但是有些集群可能并沒有配置 SSD,僅僅是普通的機械硬盤,當 Flink 任務比較大,且對狀態訪問比較頻繁時,機械硬盤的磁盤 IO 可能成為性能瓶頸。在這種情況下,該如何解決此瓶頸呢?
RocksDB 使用內存加磁盤的方式存儲數據,當狀態比較大時,磁盤占用空間會比較大。如果對 RocksDB 有頻繁的讀取請求,那么磁盤 IO 會成為 Flink 任務瓶頸。
強烈建議在 flink-conf.yaml 中配置 state.backend.rocksdb.localdir 參數來指定 RocksDB 在磁盤中的存儲目錄。當一個 TaskManager 包含 3 個 slot 時,那么單個服務器上的三個并行度都對磁盤造成頻繁讀寫,從而導致三個并行度的之間相互爭搶同一個磁盤 io,這樣必定導致三個并行度的吞吐量都會下降。
慶幸的是 Flink 的 state.backend.rocksdb.localdir 參數可以指定多個目錄,一般大數據服務器都會掛載很多塊硬盤,我們期望同一個 TaskManager 的三個 slot 使用不同的硬盤從而減少資源競爭。具體參數配置如下所示:
注意:務必將目錄配置到多塊不同的磁盤上,不要配置單塊磁盤的多個目錄,這里配置多個目錄是為了讓多塊磁盤來分擔壓力。
如下圖所示是筆者測試過程中磁盤的 IO 使用率,可以看出三個大狀態算子的并行度分別對應了三塊磁盤,這三塊磁盤的 IO 平均使用率都保持在 45% 左右,IO 最高使用率幾乎都是 100%,而其他磁盤的 IO 平均使用率為 10% 左右,相對低很多。由此可見使用 RocksDB 做為狀態后端且有大狀態的頻繁讀寫操作時,對磁盤 IO 性能消耗確實比較大。
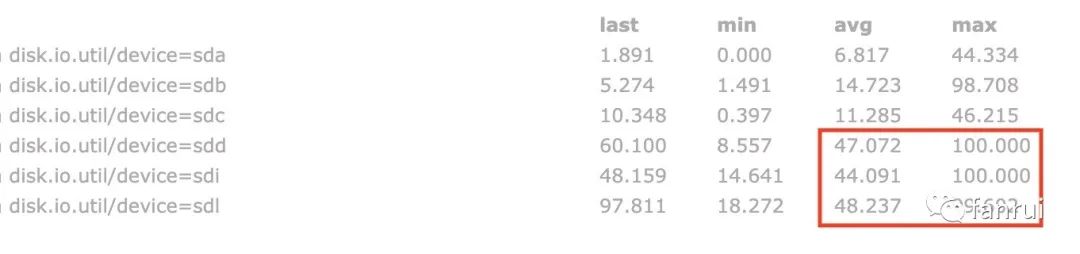
上述屬于理想情況,當設置多個 RocksDB 本地磁盤目錄時,Flink 會隨機選擇要使用的目錄,所以就可能存在三個并行度共用同一目錄的情況。
如下圖所示,其中兩個并行度共用了 sdb 磁盤,一個并行度使用 sdj 磁盤。可以看到 sdb 磁盤的 IO 平均使用率已經達到了 91.6%,此時 sdb 的磁盤 IO 肯定會成為整個 Flink 任務的瓶頸,會導致 sdb 磁盤對應的兩個并行度吞吐量大大降低,從而使得整個 Flink 任務吞吐量降低。
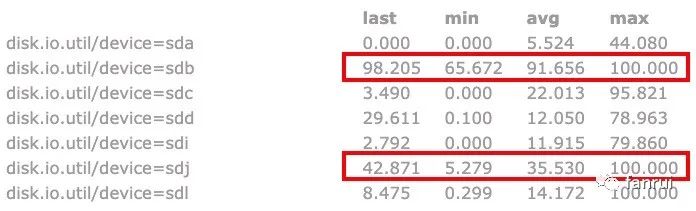
如果服務器掛載的硬盤數量較多,一般不會出現該情況,但是如果任務重啟后吞吐量較低,可以檢查是否發生了多個并行度共用同一塊磁盤的情況。
Flink 可能會出現多個并行度共用同一塊磁盤的問題,那該如何解決呢?
二、常用的負載均衡策略
從現象來看,為 RocksDB 分配了 12 塊磁盤,僅僅有 3 個并行度需要使用 3 塊磁盤,但是有一定幾率 2 個并行度共用同一塊磁盤,甚至可能會有很小的幾率 3 個并行度共用同一塊磁盤。這樣我們的 Flink 任務很容易因為磁盤 IO 成為瓶頸。
上述分配磁盤的策略,實際上就是業界的負載均衡策略。通用的負載均衡策略有 hash、隨機以及輪循等策略。
任務本身經過某種 hash 策略后,將壓力分擔到多個 Worker 上。對應到上述場景,就是將多個 slot 使用的 RocksDB 目錄壓力分擔到多塊磁盤上。但是 hash 可能會有沖突的情況,hash 沖突表示多個不同的 Flink 并行度,經過 hash 后得到的 hashCode 一樣,或者 hashCode 對硬盤數量求余后被分配到同一塊硬盤。
隨機策略是每來一個 Flink 任務,生成一個隨機數,將壓力隨機分配到某個 Worker 上,也就是將壓力隨機分配到某塊磁盤。但是隨機數也會存在沖突的情況。
輪循策略比較容易理解,多個 Worker 輪流接收數據即可,Flink 任務第一次申請 RocksDB 目錄時使用目錄1,第二次申請目錄時使用目錄2,依次申請即可。該策略是分配任務數最均勻的策略,如果使用該策略會保證所有硬盤分配到的任務數相差最大為 1。
根據 Worker 的響應時間來分配任務,響應時間短說明負載能力強,應該多分配一些任務。對應到上述場景就是檢測各個磁盤的 IO 使用率,使用率低表示磁盤 IO 比較空閑,應該多分配任務。
為每個 Worker 分配不同的權重值,權重值高的任務分配更多的任務,一般分配的任務數與權重值成正比。
例如 Worker0 權重值為 2,Worker1 權重為 1,則分配任務時 Worker0 分配的任務數盡量分配成 Worker1 任務數的兩倍。該策略可能并不適合當前業務場景,一般相同服務器上每個硬盤的負載能力相差不會很大,除非 RocksDB 的 local dir 既包含 SSD 也包含 HDD。
三、源碼中如何分配磁盤?
筆者線上使用 Flink 1.8.1 版本,出現了有些硬盤分配了多個并行度,有些硬盤一個并行度都沒有分配。可以大膽的猜測一下,源碼中使用 hash 或者 random 的概率比較高,因為大多數情況下,每個硬盤只分到一個任務,小幾率分配多個任務(要解決的就是這個小幾率分配多個任務的問題)。
如果使用輪循策略,肯定會保證每個硬盤都分配一個并行度以后,才會出現單硬盤分配兩個任務的情況。而且輪循策略可以保證分配的硬盤是連續的。
直接看 RocksDBStateBackend 類的部分源碼:
/** Base paths for RocksDB directory, as initialized.這里就是我們上述設置的 12 個 rocksdb local dir */private transient File[] initializedDbBasePaths;
/** The index of the next directory to be used from {@link #initializedDbBasePaths}.下一次要使用 dir 的 index,如果 nextDirectory = 2,則使用 initializedDbBasePaths 中下標為 2 的那個目錄做為 rocksdb 的存儲目錄 */private transient int nextDirectory;
// lazyInitializeForJob 方法中, 通過這一行代碼決定下一次要使用 dir 的 index,// 根據 initializedDbBasePaths.length 生成隨機數,// 如果 initializedDbBasePaths.length = 12,生成隨機數的范圍為 0-11nextDirectory = new Random().nextInt(initializedDbBasePaths.length);
分析完簡單的源碼后,我們知道了源碼中使用了 random 的策略來分配 dir,跟我們所看到的現象能夠匹配。隨機分配有小概率會出現沖突。(寫這篇文章時,Flink 最新的 master 分支代碼仍然是上述策略,尚未做任何改動)
四、使用哪種策略更合理?
(各種策略帶來的挑戰)
random 和 hash 策略在任務數量比較大時,可以保證每個 Worker 承擔的任務量基本一樣,但是如果任務量比較小,例如將 20 個任務通過隨機算法分配給 10 個 Worker 時,就會出現有的 Worker 分配不到任務,有的 Worker 可能分配到 3 或 4 個任務。所以 random 和 hash 策略不能解決 rocksdb 分配磁盤不均的痛點,那輪循策略和最低負載策略呢?
輪循策略可以解決上述問題,解決方式如下:
// 在 RocksDBStateBackend 類中定義了private static final AtomicInteger DIR_INDEX = new AtomicInteger(0);// nextDirectory 的分配策略變成了如下代碼,每次將 DIR_INDEX + 1,然后對 dir 的總數求余nextDirectory = DIR_INDEX.getAndIncrement() % initializedDbBasePaths.length;
通過上述即可實現輪循策略,申請磁盤時,從 0 號磁盤開始申請,每次使用下一塊磁盤即可。
■ 帶來的問題:
Java 中靜態變量屬于 JVM 級別的,每個 TaskManager 屬于單獨的 JVM,所以 TaskManager 內部保證了輪循策略。如果同一臺服務器上運行多個 TaskManager,那么多個 TaskManager 都會從 index 為 0 的磁盤開始使用,所以導致 index 較小的磁盤會被經常使用,而 index 較大的磁盤可能經常不會被使用到。
■ 解決方案 1:
DIR_INDEX 初始化時,不要每次初始化為 0,可以生成一個隨機數,這樣可以保證不會每次使用 index 較小的磁盤,實現代碼如下所示:
// 在 RocksDBStateBackend 類中定義了private static final AtomicInteger DIR_INDEX = new AtomicInteger(new Random().nextInt(100));
但是上述方案不能完全解決磁盤沖突的問題,同一臺機器上 12 塊磁盤,TaskManager0 使用 index 為 0、1、2 的三塊磁盤,TaskManager1 可能使用 index 為 1、2、3 的三塊磁盤。結果就是 TaskManager 內部來看,實現了輪循策略保證負載均衡,但是全局來看,負載并不均衡。
■ 解決方案 2:
為了全局負載均衡,所以多個 TaskManager 之間必須通信才能做到絕對的負載均衡,可以借助第三方的存儲進行通信,例如在 Zookeeper 中,為每個服務器生成一個 znode,znode 命名可以是 host 或者 ip。使用 Curator 的 DistributedAtomicInteger 來維護 DIR_INDEX 變量,存儲在當前服務器對應的 znode 中,無論是哪個 TaskManager 申請磁盤,都可以使用 DistributedAtomicInteger 將當前服務器對應的 DIR_INDEX + 1,從而就可以實現全局的輪循策略。
DistributedAtomicInteger 的 increment 的思路:先使用 Zookeeper 的 withVersion api 進行 +1 操作(也就是 Zookeeper 提供的 CAS api),如果成功則成功;如果失敗,則使用分布式互斥鎖進行 +1 操作。
基于上述描述,我們得到兩種策略來實現輪循,AtomicInteger 只能保證 TaskManager 內部的輪循,不能保證全局輪循。如果要基于全局輪循,需要借助 Zookeeper 或其他組件來實現。如果對輪循策略要求比較苛刻,可以使用基于 Zookeeper 的輪循策略,如果不想依賴外部組件則只能使用 AtomicInteger 來實現。
思想就是 TaskManager 啟動時,監測所有 rocksdb local dir 對應的磁盤最近 1 分鐘或 5 分鐘的 IO 平均使用率,篩掉 IO 使用率較高的磁盤,優先選擇 IO 平均使用率較低的磁盤,同時在 IO 平均使用率較低的磁盤中,依然要使用輪循策略來實現。
Flink 任務啟動時,只能拿到磁盤當前的 IO 使用率,是一個瞬時值,會不會不靠譜?
Flink 任務啟動,不可能等待任務先采集 1 分鐘 IO 使用率以后,再去啟動。
不想依賴外部監控系統去拿這個 IO 使用率,要考慮通用性。
假設已經拿到了所有硬盤最近 1 分鐘的 IO 使用率,該如何去決策呢?
對于 IO 平均使用率較低的磁盤中,依然要使用輪循策略來實現。
IO 平均使用率較低,這里的較低不好評判,相差 10% 算低,還是 20%、30%。
而且不同的新任務對于磁盤的使用率要求也是不一樣的,所以評判難度較大。
啟動階段不采集硬盤的負載壓力,使用之前的 DistributedAtomicInteger 基本就可以保證每個硬盤負載均衡。但是任務啟動后一段時間,如果因為 Flink 任務導致某個磁盤 IO 的平均使用率相對其他磁盤而言非常高。我們可以選擇遷移高負載硬盤的數據到低負載硬盤。
上述內容就是Flink使用大狀態時的優化是什么,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





