溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Python爬蟲視頻以及使用python3爬取的實例是怎樣的,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
使用Python3爬取小說,代碼看起來有點亂,下面有截圖
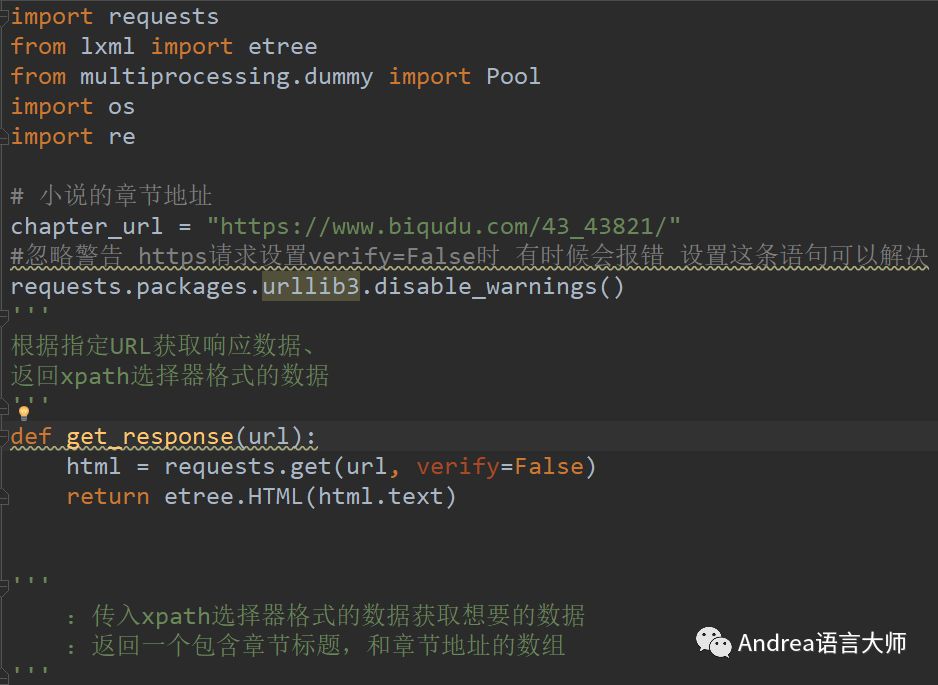
import requests
from lxml import etree
from multiprocessing.dummy import Pool
import os
import re
#小說的章節地址
chapter_url = "https://www.biqudu.com/43_43821/"
#忽略警告 https請求設置verify=False時 有時候會報錯 設置這條語句可以解決
requests.packages.urllib3.disable_warnings()
def get_response(url):
'''
:根據指定URL獲取響應數據、
:返回xpath選擇器格式的數據
'''
html = requests.get(url,verify=False)
return etree.HTML(html.text)
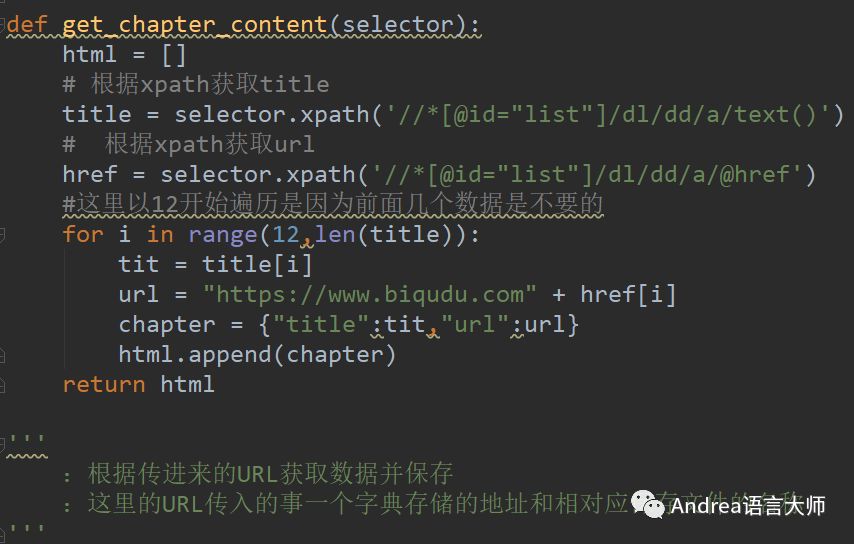
def get_chapter_content(selector):
'''
:傳入xpath選擇器格式的數據獲取想要的數據
:返回一個包含章節標題,和章節地址的數組
'''
html = []
#根據xpath獲取title
title = selector.xpath('//*[@id="list"]/dl/dd/a/text()')
# 根據xpath獲取url
href = selector.xpath('//*[@id="list"]/dl/dd/a/@href')
#這里以12開始遍歷是因為前面幾個數據是不要的
for i in range(12,len(title)):
tit = title[i]
url = "https://www.biqudu.com" + href[i]
chapter = {"title":tit,"url":url}
html.append(chapter)
return html
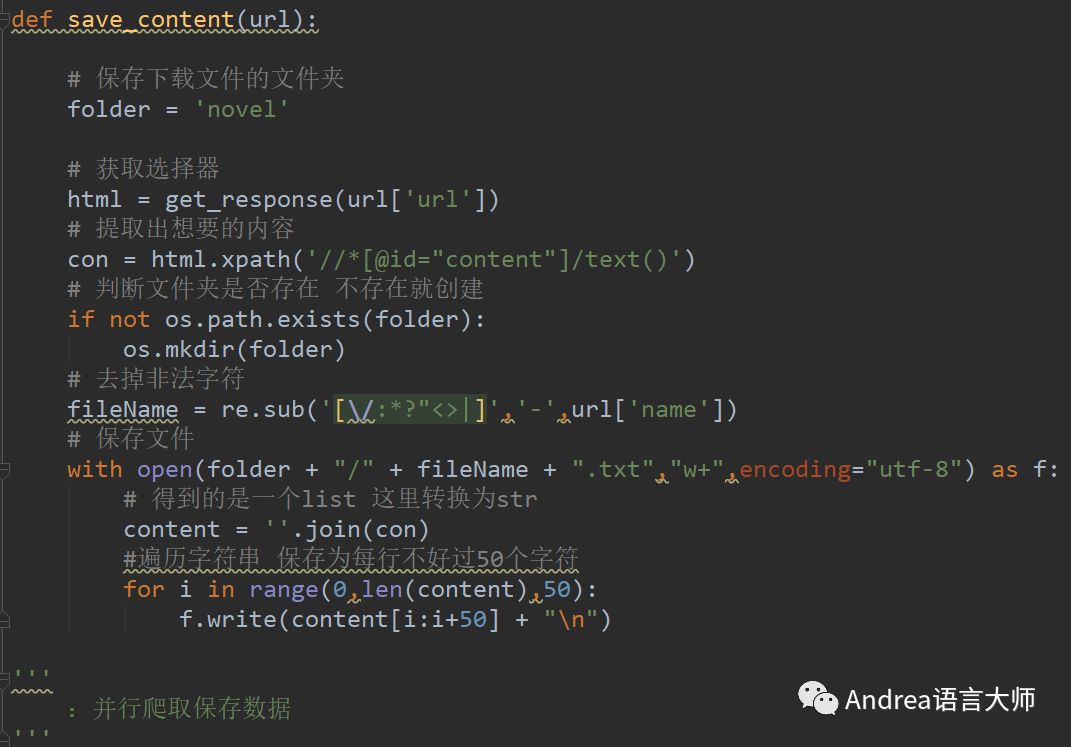
def save_content(url):
'''
:根據傳進來的URL獲取數據并保存
:這里的URL傳入的事一個字典存儲的地址和相對應保存文件的名稱
'''
# 保存下載文件的文件夾
folder = 'novel'
# 獲取選擇器
html = get_response(url['url'])
# 提取出想要的內容
con = html.xpath('//*[@id="content"]/text()')
# 判斷文件夾是否存在 不存在就創建
if not os.path.exists(folder):
os.mkdir(folder)
# 去掉非法字符
fileName = re.sub('[\/:*?"<>|]','-',url['name'])
# 保存文件
with open(folder + "/" + fileName + ".txt","w+",encoding="utf-8") as f:
# 得到的是一個list 這里轉換為str
content = ''.join(con)
#遍歷字符串 保存為每行不好過50個字符
for i in range(0,len(content),50):
f.write(content[i:i+50] + "\n")
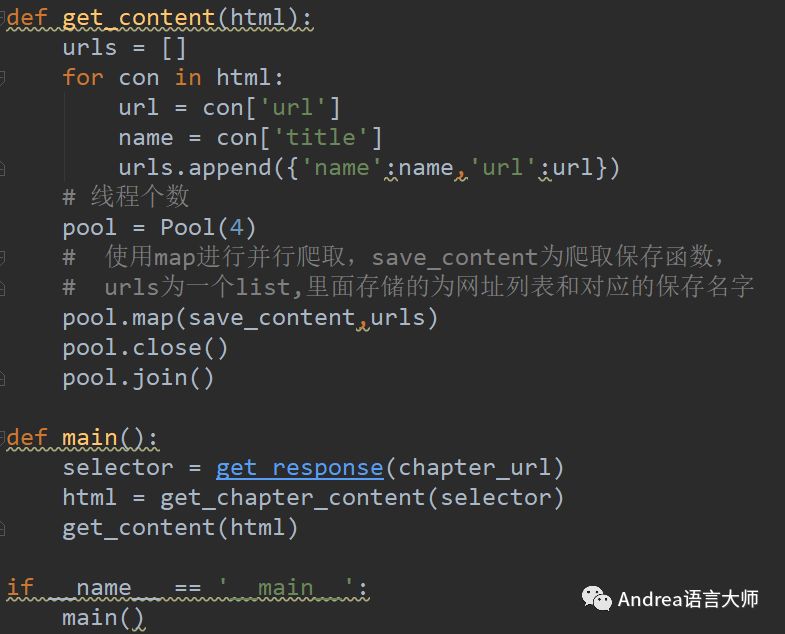
def get_content(html):
'''
:并行爬取保存數據
'''
urls = []
for con in html:
url = con['url']
name = con['title']
urls.append({'name':name,'url':url})
# 線程個數
pool = Pool(4)
# 使用map進行并行爬取,save_content為爬取保存函數,
# urls為一個list,里面存儲的為網址列表和對應的保存名字
pool.map(save_content,urls)
pool.close()
pool.join()
def main():
selector = get_response(chapter_url)
html = get_chapter_content(selector)
get_content(html)
if __name__ == '__main__':
main()
關于Python爬蟲視頻以及使用python3爬取的實例是怎樣的就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





