溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何解析分布式資源調度框架YARN,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
我們先來了解一下MapReduce 1.x的架構以及存在的問題。
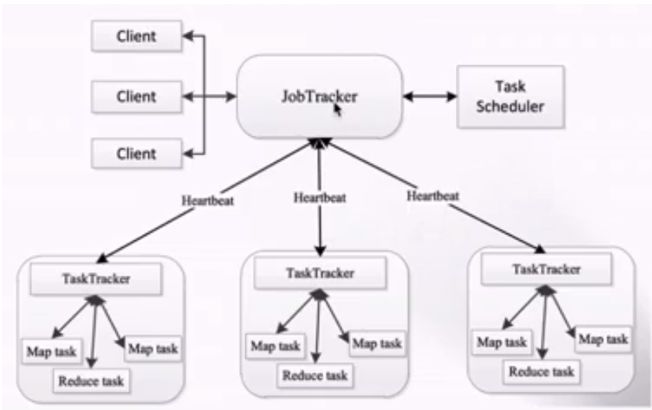
如圖所示,1.x的架構也采用的是主從結構:即master-slaves架構,一個JobTracker帶多個TaskTracker
JobTracker:負責資源管理和作業調度;Tasktracker 向jobtracker定期匯報本節點的健康狀況、資源使用情況、作業執行情況;同時也接收來自JobTracker的命令,負責啟動和殺死任務的具體執行。MapReduce作業拆分成Map任務和Task任務,由TaskTracker負責執行和匯報。
這樣的架構存在的缺點:
只有一個JobTracker負責集群事務的集中處理,存在單點故障。且壓力大不易擴展。
JobTracker需要完成得任務太多,既要維護job的狀態又要維護job的task的狀態,造成資源消耗過多
僅僅只能支持MR作業。不支持其他計算框架,如spark,storm等。
存在多個集群,如Spark集群,hadoop集群同時存在,不能夠統一管理,資源利用率較低,彼此之間沒有辦法共享資源,運維成本高。
Yet Another Resource Negotiator。是一個操作系統級別的資源調度框架。
MRv2 最基本的想法是將原 JobTracker 主要的資源管理和 Job 調度/監視功能分開作為兩個單獨的守護進程。有一個全局的ResourceManager(RM)和每個 Application 有一個ApplicationMaster(AM),Application 相當于 MapReduce Job 或者 DAG jobs。ResourceManager和 NodeManager(NM)組成了基本的數據計算框架。ResourceManager 協調集群的資源利用,任何 Client 或者運行著的 applicatitonMaster 想要運行 Job 或者 Task 都得向 RM 申請一定的資源。ApplicatonMaster 是一個框架特殊的庫,對于 MapReduce 框架而言有它自己的 AM 實現,用戶也可以實現自己的 AM,在運行的時候,AM 會與 NM 一起來啟動和監視 Tasks。
reference:https://blog.51cto.com/14048416/2342195
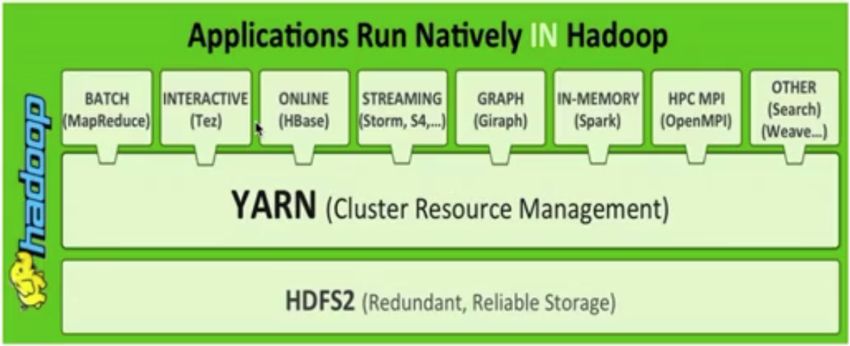
上圖顯示了YARN的位置:位于HDFS之上,多種應用程序之下。這樣多種不同類型的計算框架都可以運行在同一個集群里面,共享同一個HDFS集群上的數據,享受整體的資源調度。也就是 XXX on YARN,例如Spark on YARN,Spark on YARN,MapReduce on Yarn,Storm on YARN,Flink on YARN。好處是與其他計算框架共享集群資源,按自愿需要分配,進而提高集群資源的利用率。
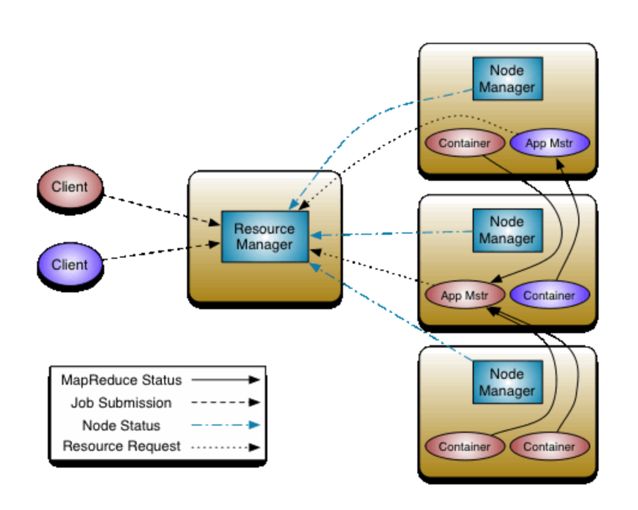
YARN的架構中包含ResourceManager(RM),NodeManager(NM),ApplicationMaster(AM),Container,Client供5種核心組件,依然是一種主從結構,即1個RM+N個NM的形式。它們的作用如下:
1)RM:整個集群同一時間提供服務的只有一個,(生產上多采用一主一備的方式防止故障發生),負責集群資源的統一管理和調度。主要承擔的任務由:
處理客戶端的請求:提交一個作業,殺死一個作業。
監控NM,如果某個NM發生故障,將該NM上運行的任務告訴AM,由AM決定是否重新運行相應task。
2)NM:整個集群中有多個,負責自身節點資源管理和使用。它承擔的任務由:
定時向RM匯報本節點的資源使用情況和自身的健康狀況。
接收并處理來自RM的各種命令,比如啟動Container運行AM。
處理來自AM的命令,如啟動Container運行task。
單個節點的資源管理
3)AM:每個應用程序對應一個AM,(每一個MapReduce作業,每一個Spark作業對應一個),負責對應的應用程序管理。
為應用程序向RM申請資源(core、memory等),之后進行分配
需要與NM進行通信:啟動或者停止task,task和AM都是是運行在Container中的。
一個NM可能運行很多task,這些task分屬于不同的AM
4)Container
封裝了CPU Memory等資源的一個容器,是一個任務運行環境的抽象。
AM運行在Container里面,task也是
5)Client:客戶端
發起響應的請求,例如:
提交作業,查看作業運行進度
殺死作業

①客戶端提交task 請求到RM
②③RM先到NM上啟動1個Container,用來運行AM。
④AM啟動之后,注冊到RM上。(任務是由AM管理的,注冊之后,用戶就可以通過RM查詢AM上的作業進度)并向NM申請資源(Core Memory),RM給AM分配相應的NM資源,
⑤⑥AM下發指令給相應的的NM,NM啟動Container運行task 。
這就是YARN執行的一個基本流程,這是一個通用的流程,MapReduce作業對應MapReduce的Application master,Spark作業對應Spark的Application Master,其他的作業也有相應的Application Master。
我們在前面進行了YARN的配置,參考hadoop中Yarn的配置與使用示例,主要有mapred-site.xml和yarn-site.xml兩個配置文件,在啟動時有一個start-yarn.sh 命令,就是用來啟動RM和NM的(使用stop-yarn.sh停止YARN的進程)。啟動YARN之后,我們就可以在web瀏覽器上可以查看YARN集群的情況。包括當前節點的情況,任務的運行狀態等。
關于如何解析分布式資源調度框架YARN問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





