溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“Hadoop基礎知識有哪些”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“Hadoop基礎知識有哪些”這篇文章吧。
Hadoop這個單詞本身并沒有什么特殊的含義,而只是其作者Doug Cutting孩子的一個棕黃色的大象玩具的名字。
Hadoop是一個高可靠的(reliable),規模可擴展的(scalable),分布式(distributed computing)的開源軟件框架。它使我們能用一種簡單的編程模型來處理存儲于集群上的大數據集。
Hadoop是Apache基金會的一個開源項目,是一個提供了分布式存儲和分布式計算功能的基礎架構平臺。可以應用于企業中的數據存儲,日志分析,商業智能,數據挖掘等。
1. hadoop包含的模塊:
Hadoop common:提供一些通用的功能支持其他hadoop模塊。
Hadoop Distributed File System:即分布式文件系統,簡稱HDFS。主要用來做數據存儲,并提供對應用數據高吞吐量的訪問。
Hadoop Yarn:用于作業調度和集群資源管理的框架。
Hadoop MapReduce:基于yarn的,能用來并行處理大數據集的計算框架。
2. HDFS:
HDFS是谷歌GFS的一個開源實現,具有擴展性,容錯性,海量數據存儲的特點:
擴展性,主要指很容易就可以在當前的集群上增加一臺或者多臺機器,擴展計算資源。
容錯性,主要指其多副本的存儲機制。HDFS將文件切分成固定大小的block(默認是128M),并以多副本形式存儲在多臺機器上,當其中一臺機器發生故障,仍然有其他副本供我們使用。但這個容錯并不是絕對的,當所有節點都發生故障,文件就會丟失,不過這樣的概率較小。
海量數據存儲:多臺機器構成了一個集群,相對單機能存儲更多量的數據。這也是Hadoop解決的最主要問題之一。
數據切分,多副本,容錯等機制都是Hadoop底層已經設計好的,對用戶透明,用戶不需要關系細節。只需要按照對單機文件的操作方式,就可以進行分布式文件的操作。如文件的上傳,查看,下載等。
多副本存儲示例:
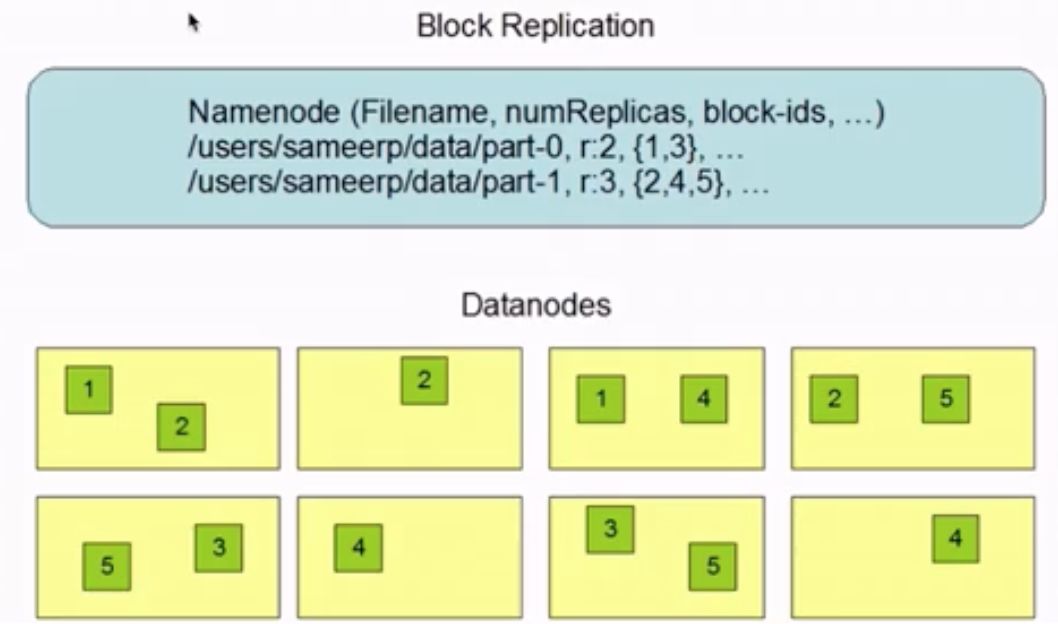
以part-1為例進行說明,它被分成三個block,block_id分別是2,4,5,且副本系數為3。可以看到在DataNode上,2,4,5都各存儲在了三個節點上,這樣當其中一個節點故障時,仍然能夠保證文件的可用。block_id存在的必要性在于,在用戶需要對文件進行操作時,相應的block能夠按順序進行“組合”起來。
3. YARN:
Yarn的全稱是Yet Another Resource Negotiator,負責整個集群資源的管理和調度。例如對每個作業,分配CPU,內存等等,都由yarn來管理。它的特點是擴展性,容錯性,多框架資源統一調度。
擴展性和HDFS的擴展性類似,yarn也很容易擴展其計算資源。
容錯性,主要是指當某個任務出現異常,yarn會對其進行一定次數的重試。
多框架資源統一調度,這個是相對于hadoop1.0版本的一個優勢。區別于hadoop1.0只支持MapReduce作業。而yarn之上可以運行不同類型的作業。如下圖所示,很多應用都可以運行在yarn之上,由yarn統一進行調度。
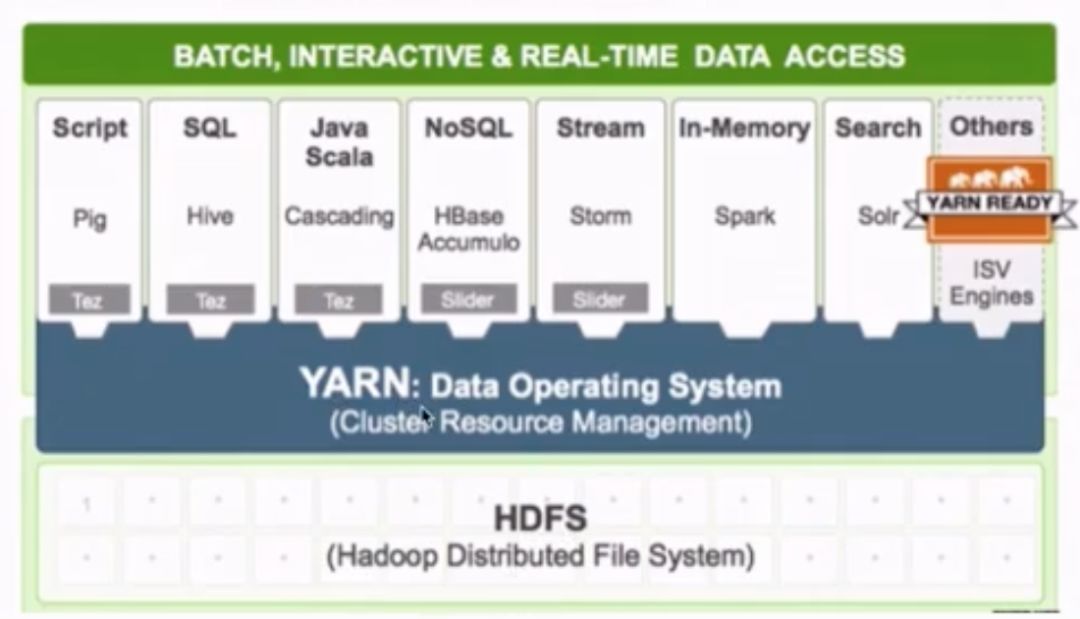
4. mapreduce:
是一個分布式計算框架,是GoogleMapReduce的克隆版。和HDFS、Yarn類似,也具有擴展性和容錯性的特點,還將具有海量數據離線處理的特點:能夠處理的數據量大,但并不是實時處理,具有較大的延時性。
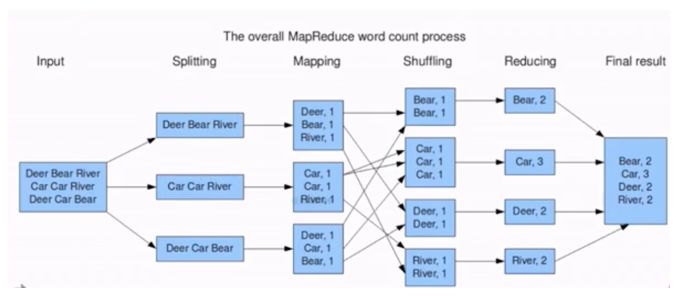
WordCount的MapReduce流程如圖所示,主要分為Map和Reduce兩個過程。Map階段做映射,對所有輸入的單詞賦值為1,Reduce階段做匯總,相同的單詞分發到一個節點上并進行求和,最終就可以統計出單詞的個數。
hadoop的優勢主要體現在高可靠性,高擴展性等方面。
高可靠性是指多副本的存儲機制和失敗作業的重新調度計算。
高擴展性是指資源不夠時很容易直接擴展機器。一個集群可以包含數以千計的節點。
其他優勢還表現在:hadoop完全可以部署在普通廉價的機器上,成本低。同時它具有成熟的生態圈和開源社區。
狹義hadoop:指一個用于大數據分布式存儲(HDFS),分布式計算(MapReduce)和資源調度(YARN)的平臺,這三樣只能用來做離線批處理,不能用于實時處理,因此才需要生態系統的其他的組件。
廣義的hadoop:指的是hadoop的生態系統,即其他各種組件在內的一整套軟件。hadoop生態系統是一個很龐大的概念,hadoop只是其中最重要最基礎的部分,生態系統的每一個子系統只結局的某一個特定的問題域。不是一個全能系統,而是多個小而精的系統。
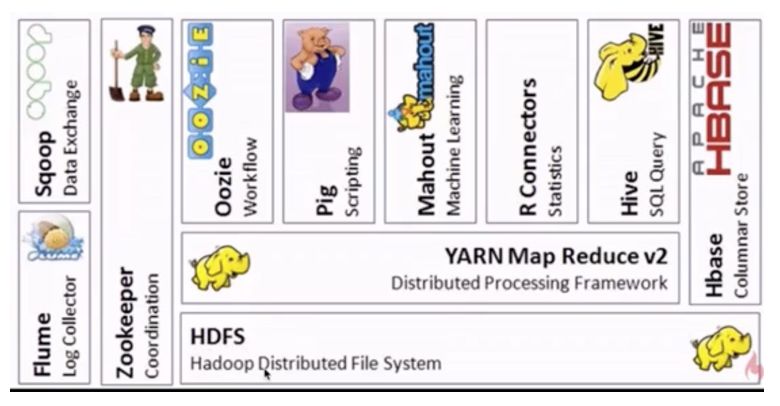
由于MapReduce的學習成本相對較高,這樣就誕生了一些其他框架。
Hive 處理的是海量結構化日志數據的統計問題。它定義了一種類似SQL的語言Hive QL,借助于hive引擎能將其轉換為MapReduce作業并提交到集群上進行運算。hive適用于離線處理。相比之下,SQL的門檻就低得多
Mahout是一個機器學習算法庫,實現了很多數據挖掘的經典算法,幫助用戶很方便地創建應用程序。
Pig可以將腳本任務轉換為MapReduce作業,同樣是適用于離線分析。
Oozie是一個工作流調度引擎,用來處理具有依賴關系的作業調度。類似的框架有Azkaban,airflow等。
Zookeeper:分布式協調服務,“動物園管理員”角色,是一個對集群服務進行管理的框架,如維護故障切換等。
Flume:日志收集框架。將多種應用服務器上的日志,統一收集到HDFS上,這樣就可以使用hadoop進行處理
Sqoop:提供關系型數據庫與HDFS數據相互傳輸的功能。
Hbase:面向列存儲的數據庫。適用于實時快速查詢的場景。
除此之外,還有spark,kafka,flink,redis等新興的一些實用框架。
reference:https://blog.csdn.net/zcb_data/article/details/80402411
開源,社區高活躍
開源意味著源碼可獲取,可以直接基于源碼進行改造實現個性化需求。社區活躍高意味著迭代更新快,維護的人多。
囊括了大數據處理的方方面面
具有成熟的生態圈。
Apache hadoop:解決了單個框架的額問題,綜合起來使用會有jar包沖突,不適合于生產環境。
CDH:Cloudera Distributed Hadoop。商業版本。使用Cloudera Manager對集群進行管理,通過瀏覽器,不需要通過linux就可以安裝,與spark結合的很好。沒有jar包沖突的問題。但Cloudera Manager不開源,企業版收費。
CDH的下載地址:http://archive.cloudera.com/cdh6/cdh/5/
HDP:Hortonworks Data Platform。商業版本之一,使用Ambari進行統一管理,對服務的用戶收費。
以上是“Hadoop基礎知識有哪些”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





