溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“服務器中如何保障數據高可用”的相關知識,小編通過實際案例向大家展示操作過程,操作方法簡單快捷,實用性強,希望這篇“服務器中如何保障數據高可用”文章能幫助大家解決問題。
分布式技術,在保障高可用和容錯或彈性時,一般常用這兩種手段:
復制
分區
對應英語一個是replication, 一個是partition。
復制,是把每次寫入的數據多保存 N 份,這樣在出故障的時候可以用來恢復,同時也可以進行讀寫分離,緩解讀的壓力。分區則是在數據超越了單臺存儲能力的時候,按一定規則分多臺存儲。分區的數據其實也是有復制的存在來保障這一個partition的數據不丟失。
復制了就可以高枕無憂了?
這都是理想情況,實際上每天都會出現機房故障,硬盤損壞,失誤斷電等等問題。
比如咱們自己把手機上的照片、文件等等備份到網盤,手機一清理, 欣喜騰出不少空間。某天去看的時候,網盤里一部分數據找不到了,客服告訴你某天機房備份文件的硬盤壞了,再也找不回來,你啥感覺?
你肯定憤怒的問客服為啥不再多存幾份。可如果是整個硬盤所在機架都掛了呢?
和咱們搭應用的服務一樣,為了應對問題,保證高可用,除了不出現單點,還得考慮實例部署在不同的機房,這樣就算某個機房都出問題的時候,另一個機房也還能扛著。
對應到數據的復制和備份上,聰明的腦袋們想出了類似的思路,將備份存在不同的硬盤,不同的機架,甚至不同的機房上,像兔子一樣,做到
「狡兔三窟」。 :-)
咱們一般使用網盤,云服務廠商提供的各類存儲,背后都有一個分布式的存儲服務,來保證應用的高可用,彈性容錯等等,像咱們之前分享的神書 DDIA 里許多技術都在這些服務里有使用。
HDFS 做為Hadoop的核心存儲實現,內部也支持這種更安全的多地存儲備份實現。在 HDFS 中,這一技術稱為 Rack Awareness。
Rack 就是機架,是在機房或者數據中心里存儲著一堆的物理機,通過網絡的技術來管理。
在 Hadoop 里為了在一個集群里提升網絡讀寫 HDFS 文件的速度,管理MetaData信息的 NameNode 會根據 Rack 就近選取 DataNode去
讀寫。畢竟 NameNode存放著 rack id 和 DataNode 的對應信息,我們的備份數據真正寫到了 DataNode里。rack id 相當于代號。
NameNode 根據 Rack id 選擇一個更近的 DataNode 的過程,稱之為 Rack Awareness。
默認的 Hadoop 按照所有的DataNode 屬于同一個 Rack。這樣就容易出問題,而打開 Awareness之后,效果類似下面這個圖,
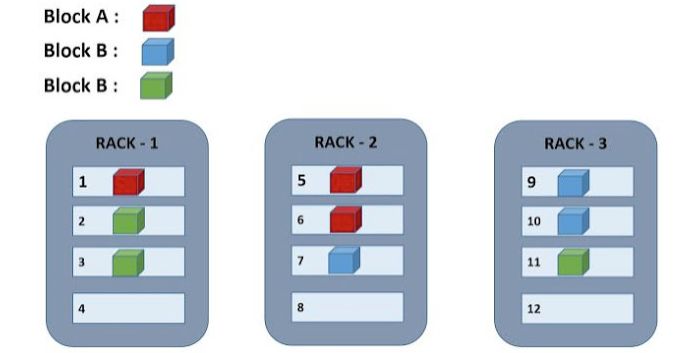
我們保存文件的時候,文件會被分成以128M為大小的 Block,之然通過NameNode來獲得具體保存數據的DataNode 地址,默認是3 個備份,遵循的原則是「每個block,兩個備份存在同一個 rack,第三個備份存在另一個不同的rack上」。這一規則也稱為 Replica Placement Policy。
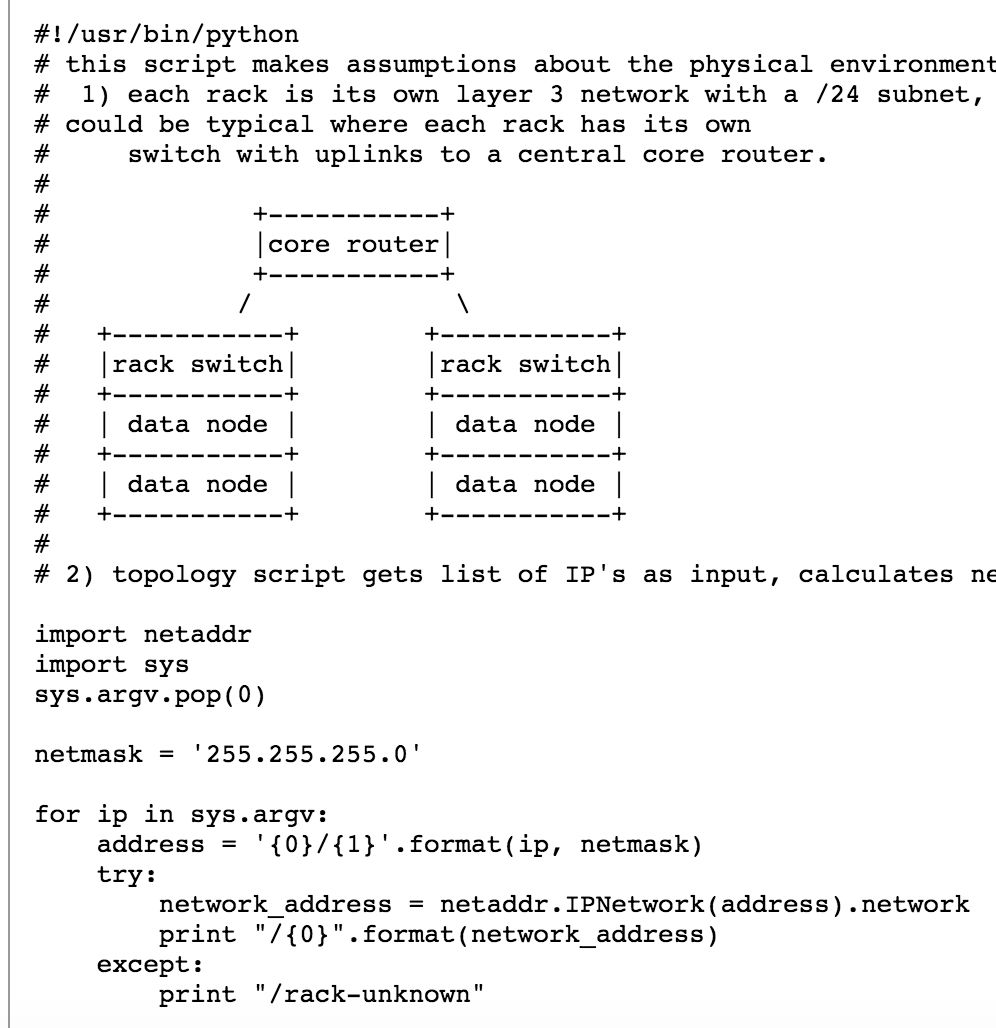
具體存放時如何確定放到哪個rack上?我們前面提到是通過 rack id 來判斷的, HDFS 內部是可以通過執行一個外部腳本或者是在配置文件中指定一個 Java類來獲得。
以下是官方文檔給出的一個python 的例子
為什么需要 Rack Awareness?
可以保證數據的高可用和可依賴性
提升集群的性能
在整個 Rack 出現故障時避免數據丟失
關于“服務器中如何保障數據高可用”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識,可以關注億速云行業資訊頻道,小編每天都會為大家更新不同的知識點。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





