溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關如何使用注意力機制來做醫學圖像分割的解釋和Pytorch實現,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
點擊上方“AI公園”,關注公眾號,選擇加“星標“或“置頂”
作者:Léo Fillioux
編譯:ronghuaiyang
對兩篇近期的使用注意力機制進行分割的文章進行了分析,并給出了簡單的Pytorch實現。
從自然語言處理開始,到最近的計算機視覺任務,注意力機制一直是深度學習研究中最熱門的領域之一。在這篇文章中,我們將集中討論注意力是如何影響醫學圖像分割的最新架構的。為此,我們將描述最近兩篇論文中介紹的架構,并嘗試給出一些關于這兩篇文章中提到的方法的直覺,希望它能給你一些想法,讓你能夠將注意力機制應用到自己的問題上。我們還將看到簡單的PyTorch實現。

醫學圖像分割與自然圖像的區別主要有兩點:
注意:當然,代碼和解釋都是對論文中描述的復雜架構的簡化,其目的主要是給出一個關于做了什么的直覺和一個好的想法,而不是解釋每一個細節。
UNet是用于分割的主要架構,目前在分割方面的大多數進展都使用這種架構作為骨干。在本文中,作者提出了一種將注意力機制應用于標準UNet的方法。
該結構使用標準UNet作為骨干,并且不改變收縮路徑。改變的是擴展路徑,更準確地說,注意力機制被整合到跳轉連接中。
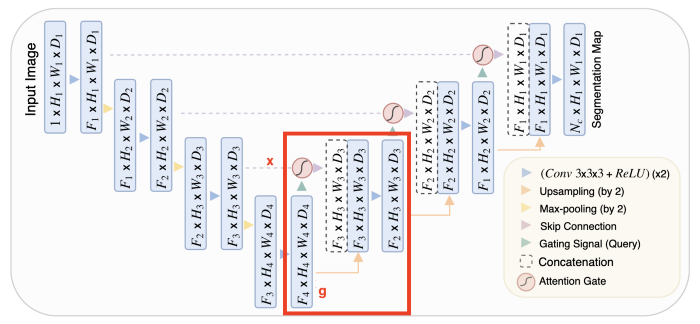
為了解釋展開路徑的block是如何工作的,讓我們把來自前一個block的輸入稱為g,以及來自擴展路徑的skip鏈接稱為x。下面的式子描述了這個模塊是如何工作的。

upsample塊非常簡單,而ConvBlock只是由兩個(convolution + batch norm + ReLU)塊組成的序列。唯一需要解釋的是注意力。
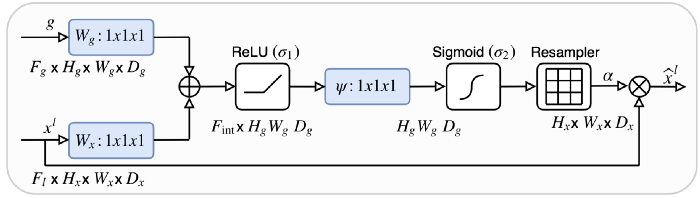
在UNet中,可將收縮路徑視為編碼器,而將擴展路徑視為解碼器。UNet的有趣之處在于,跳躍連接允許在解碼器期間直接使用由編碼器提取的特征。這樣,在“重建”圖像的掩模時,網絡就學會了使用這些特征,因為收縮路徑的特征與擴展路徑的特征是連接在一起的。
在此連接之前應用一個注意力塊,可以讓網絡對跳轉連接相關的特征施加更多的權重。它允許直接連接專注于輸入的特定部分,而不是輸入每個特征。
將注意力分布乘上跳轉連接特征圖,只保留重要的部分。這種注意力分布是從所謂的query(輸入)和value(跳躍連接)中提取出來的。注意力操作允許有選擇地選擇包含在值中的信息。此選擇基于query。
總結:輸入和跳躍連接用于決定要關注跳躍連接的哪些部分。然后,我們使用skip連接的這個子集,以及標準展開路徑中的輸入。
下面的代碼定義了注意力塊(簡化版)和用于UNet擴展路徑的“up-block”。“down-block”與原UNet一樣。
class AttentionBlock(nn.Module):
def __init__(self, in_channels_x, in_channels_g, int_channels):
super(AttentionBlock, self).__init__()
self.Wx = nn.Sequential(nn.Conv2d(in_channels_x, int_channels, kernel_size = 1),
nn.BatchNorm2d(int_channels))
self.Wg = nn.Sequential(nn.Conv2d(in_channels_g, int_channels, kernel_size = 1),
nn.BatchNorm2d(int_channels))
self.psi = nn.Sequential(nn.Conv2d(int_channels, 1, kernel_size = 1),
nn.BatchNorm2d(1),
nn.Sigmoid())
def forward(self, x, g):
# apply the Wx to the skip connection
x1 = self.Wx(x)
# after applying Wg to the input, upsample to the size of the skip connection
g1 = nn.functional.interpolate(self.Wg(g), x1.shape[2:], mode = 'bilinear', align_corners = False)
out = self.psi(nn.ReLU()(x1 + g1))
out = nn.Sigmoid()(out)
return out*x
class AttentionUpBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(AttentionUpBlock, self).__init__()
self.upsample = nn.ConvTranspose2d(in_channels, out_channels, kernel_size = 2, stride = 2)
self.attention = AttentionBlock(out_channels, in_channels, int(out_channels / 2))
self.conv_bn1 = ConvBatchNorm(in_channels+out_channels, out_channels)
self.conv_bn2 = ConvBatchNorm(out_channels, out_channels)
def forward(self, x, x_skip):
# note : x_skip is the skip connection and x is the input from the previous block
# apply the attention block to the skip connection, using x as context
x_attention = self.attention(x_skip, x)
# upsample x to have th same size as the attention map
x = nn.functional.interpolate(x, x_skip.shape[2:], mode = 'bilinear', align_corners = False)
# stack their channels to feed to both convolution blocks
x = torch.cat((x_attention, x), dim = 1)
x = self.conv_bn1(x)
return self.conv_bn2(x)
注意:ConvBatchNorm是一個由Conv2d、BatchNorm2d和ReLU激活函數組成的sequence。
我們將要討論的第二個架構比第一個架構更有獨創性。它不依賴于UNet架構,而是依賴于特征提取,然后跟一個引導注意力塊。
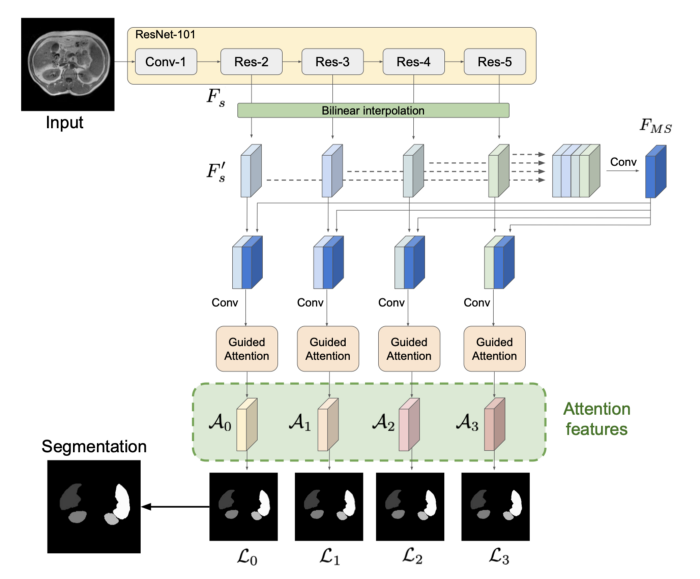
第一部分是從圖像中提取特征。為此,我們將輸入圖像輸入到一個預先訓練好的ResNet中,提取4個不同層次的特征圖。這很有趣,因為低層次的特征往往出現在網絡的開始階段,而高層次的特性往往出現在網絡的結束階段,所以我們將能夠訪問到多種尺度的特征。使用bilinear插值將所有的特征圖上采樣到最大的一個。這給了我們4個相同大小的特征圖,它們被連接并送入一個卷積塊。這個convolutional block (multi-scale feature map)的輸出與4個feature map的每一個都連接在一起,這給出了我們的attention blocks的輸入,這個輸入比之前的要復雜一些。
引導注意力塊依賴于位置和通道注意力模塊,我們從總體描述開始。
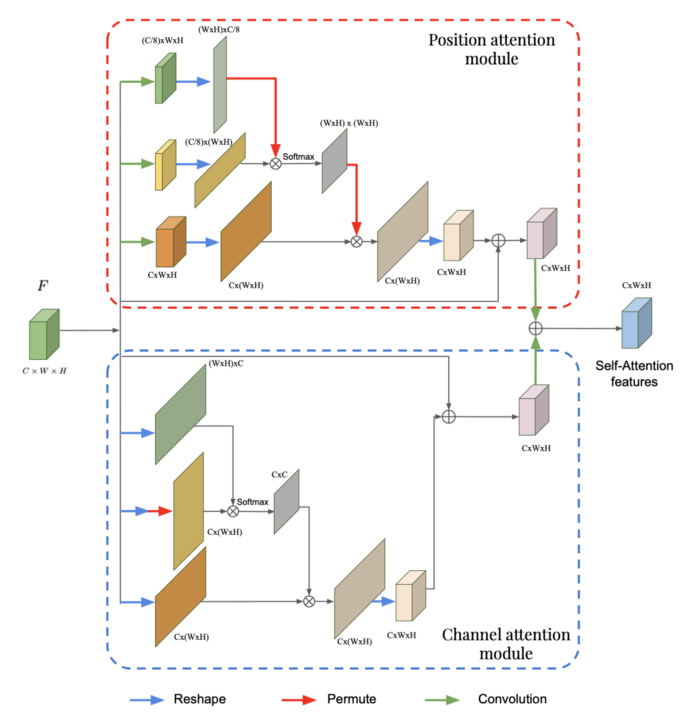
我們將嘗試理解這些模塊中發生了什么,但是我們不會詳細介紹這兩個模塊中的每個操作(可以通過下面的代碼部分理解)。
這兩個塊實際上非常相似,它們之間的唯一區別在于從通道還是位置提取信息。在flatten之前進行卷積會使位置更加重要,因為在卷積過程中通道的數量會減少。在通道注意力模塊中,在reshape的過程中,原有通道數量被保留,這樣更多的權重給到了通道上。
在每個block中,需要注意的是,最上面的兩個分支負責提取具體的注意力分布。例如,在位置注意力模塊中,我們有一個(WH)x(WH)的注意力分布,其中*(i, j)元素表示位置i對位置j*的影響有多大。在通道塊中,我們有一個CxC注意力分布,它告訴我們一個通道對另一個的影響有多大。在每個模塊的第三個分支中,將這個特定的注意分布乘以輸入的變換,得到通道或位置的注意力分布。如前一篇文章所述,在給定多尺度特征的背景下,將注意力分布乘以輸入來提取輸入的相關信息。然后對這兩個模塊的輸出進行逐元素的相加,給出最終的自注意力特征。現在,讓我們看看如何在全局框架中使用這兩個模塊的輸出。
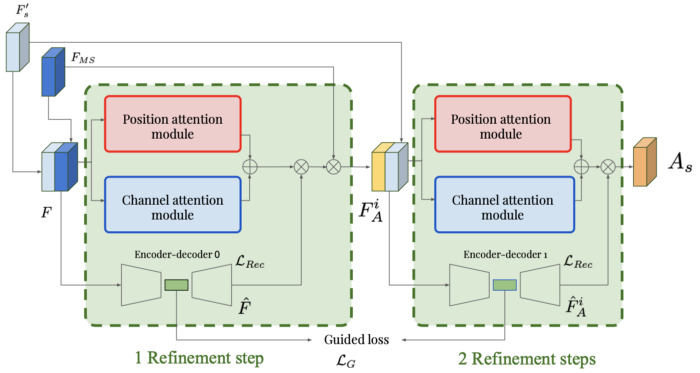
引導注意力為每個尺度建立一個連續的多個細化步驟(在提出的結構中有4個尺度)。輸入特征圖被送至位置和通道輸出模塊,輸出單個特征圖。它還通過了一個自動編碼器,該編碼器對輸入進行重建。在每個block中,注意力圖是由這兩個輸出相乘產生的。然后將此注意力圖與之前生成的多尺度特征圖相乘。因此,輸出表示了我們需要關注特定的尺度的哪個部分。然后,通過將一個block的輸出與多尺度的注意力圖連接起來,并將其作為下一個block的輸入,你就可以獲得這樣的引導注意力模塊的序列。
兩個相加的損失是必要的,以確保細化步驟工作正確:
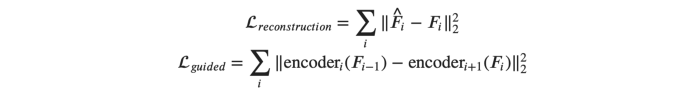
之后,每個注意力特征通過卷積塊來預測mask。為了得到最終的預測結果,需要對四個mask進行平均,這可以看作是不同尺度特征下模型的一種集成。
由于這個結構比前一個復雜得多,所以很難理解注意力模塊背后的情況。下面是我對各個塊的貢獻的理解。
位置注意模塊試圖根據輸入圖像的多尺度表示來指定要聚焦的特定尺度特征在哪個位置。通道注意模塊通過指定各個通道需要注意多少來做同樣的事情。在任何一個block中使用的具體操作是為了給予通道或位置信息一個注意力分布,分配哪些地方是更重要的。結合這兩個模塊,我們得到了一個對每個位置-通道對打分的注意力圖,即特征圖中的每個元素。
autoencoder用來確保feature map的后續的表示在每一步之間都沒有完全改變。由于潛空間是低維的,因此只提取關鍵信息。我們不希望將此信息從一個細化步驟更改為下一個細化步驟,我們只希望進行較小的調整。這些在潛在表示中不會被看到。
使用一系列的引導注意力模塊,可以使最終的注意力圖得到細化,并逐步使噪音消失,給予真正重要的區域更多的權重。
將幾個這樣的多尺度網絡集成起來,可以使網絡同時具有全局和局部特征。然后將這些特征組合成多尺度特征圖。將注意力與每個特定的尺度一起應用到多尺度特征圖上,可以更好地理解哪些特征對最終的輸出更有價值。
class PositionAttentionModule(nn.Module):
def __init__(self, in_channels):
super(PositionAttentionModule, self).__init__()
self.first_branch_conv = nn.Conv2d(in_channels, int(in_channels/8), kernel_size = 1)
self.second_branch_conv = nn.Conv2d(in_channels, int(in_channels/8), kernel_size = 1)
self.third_branch_conv = nn.Conv2d(in_channels, in_channels, kernel_size = 1)
self.output_conv = nn.Conv2d(in_channels, in_channels, kernel_size = 1)
def forward(self, F):
# first branch
F1 = self.first_branch_conv(F) # (C/8, W, H)
F1 = F1.reshape((F1.size(0), F1.size(1), -1)) # (C/8, W*H)
F1 = torch.transpose(F1, -2, -1) # (W*H, C/8)
# second branch
F2 = self.second_branch_conv(F) # (C/8, W, H)
F2 = F2.reshape((F2.size(0), F2.size(1), -1)) # (C/8, W*H)
F2 = nn.Softmax(dim = -1)(torch.matmul(F1, F2)) # (W*H, W*H)
# third branch
F3 = self.third_branch_conv(F) # (C, W, H)
F3 = F3.reshape((F3.size(0), F3.size(1), -1)) # (C, W*H)
F3 = torch.matmul(F3, F2) # (C, W*H)
F3 = F3.reshape(F.shape) # (C, W, H)
return self.output_conv(F3*F)
class ChannelAttentionModule(nn.Module):
def __init__(self, in_channels):
super(ChannelAttentionModule, self).__init__()
self.output_conv = nn.Conv2d(in_channels, in_channels, kernel_size = 1)
def forward(self, F):
# first branch
F1 = F.reshape((F.size(0), F.size(1), -1)) # (C, W*H)
F1 = torch.transpose(F1, -2, -1) # (W*H, C)
# second branch
F2 = F.reshape((F.size(0), F.size(1), -1)) # (C, W*H)
F2 = nn.Softmax(dim = -1)(torch.matmul(F2, F1)) # (C, C)
# third branch
F3 = F.reshape((F.size(0), F.size(1), -1)) # (C, W*H)
F3 = torch.matmul(F2, F3) # (C, W*H)
F3 = F3.reshape(F.shape) # (C, W, H)
return self.output_conv(F3*F)
class GuidedAttentionModule(nn.Module):
def __init__(self, in_channels_F, in_channels_Fms):
super(GuidedAttentionModule, self).__init__()
in_channels = in_channels_F + in_channels_Fms
self.pam = PositionAttentionModule(in_channels)
self.cam = ChannelAttentionModule(in_channels)
self.encoder = nn.Sequential(nn.Conv2d(in_channels, 2*in_channels, kernel_size = 3),
nn.BatchNorm2d(2*in_channels),
nn.Conv2d(2*in_channels, 4*in_channels, kernel_size = 3),
nn.BatchNorm2d(4*in_channels),
nn.ReLU())
self.decoder = nn.Sequential(nn.ConvTranspose2d(4*in_channels, 2*in_channels, kernel_size = 3),
nn.BatchNorm2d(2*in_channels),
nn.ConvTranspose2d(2*in_channels, in_channels, kernel_size = 3),
nn.BatchNorm2d(in_channels),
nn.ReLU())
self.attention_map_conv = nn.Sequential(nn.Conv2d(in_channels, in_channels_Fms, kernel_size = 1),
nn.BatchNorm2d(in_channels_Fms),
nn.ReLU())
def forward(self, F, F_ms):
F = torch.cat((F, F_ms), dim = 1) # concatenate the extracted feature map with the multi scale feature map
F_pcam = self.pam(F) + self.cam(F) # sum the ouputs of the position and channel attention modules
F_latent = self.encoder(F) # latent-space representation, used for the guided loss
F_reconstructed = self.decoder(F_latent) # output of the autoencoder, used for the reconstruction loss
F_output = self.attention_map_conv(F_reconstructed * F_pcam)
F_output = F_output * F_ms
return F_output, F_reconstructed, F_latent
注意力可以被看作是一種機制,它有助于基于網絡的上下文指出需要關注的特征。
在UNet中,考慮到在擴展路徑中提取的特征,在收縮路徑中提取哪些特征是需要重點關注的。這有助于讓跳躍連接更有意義,即傳遞相關信息,而不是每個提取的特征。
以上就是如何使用注意力機制來做醫學圖像分割的解釋和Pytorch實現,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





