溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了python模型的評估實例分析的相關知識,內容詳細易懂,操作簡單快捷,具有一定借鑒價值,相信大家閱讀完這篇python模型的評估實例分析文章都會有所收獲,下面我們一起來看看吧。
除了使用estimator的score函數簡單粗略地評估模型的質量之外,
在sklearn.metrics模塊針對不同的問題類型提供了各種評估指標并且可以創建用戶自定義的評估指標,
使用model_selection模塊中的交叉驗證相關方法可以評估模型的泛化能力,能夠有效避免過度擬合。
一,metrics評估指標概述
sklearn.metrics中的評估指標有兩類:以_score結尾的為某種得分,越大越好,
以_error或_loss結尾的為某種偏差,越小越好。
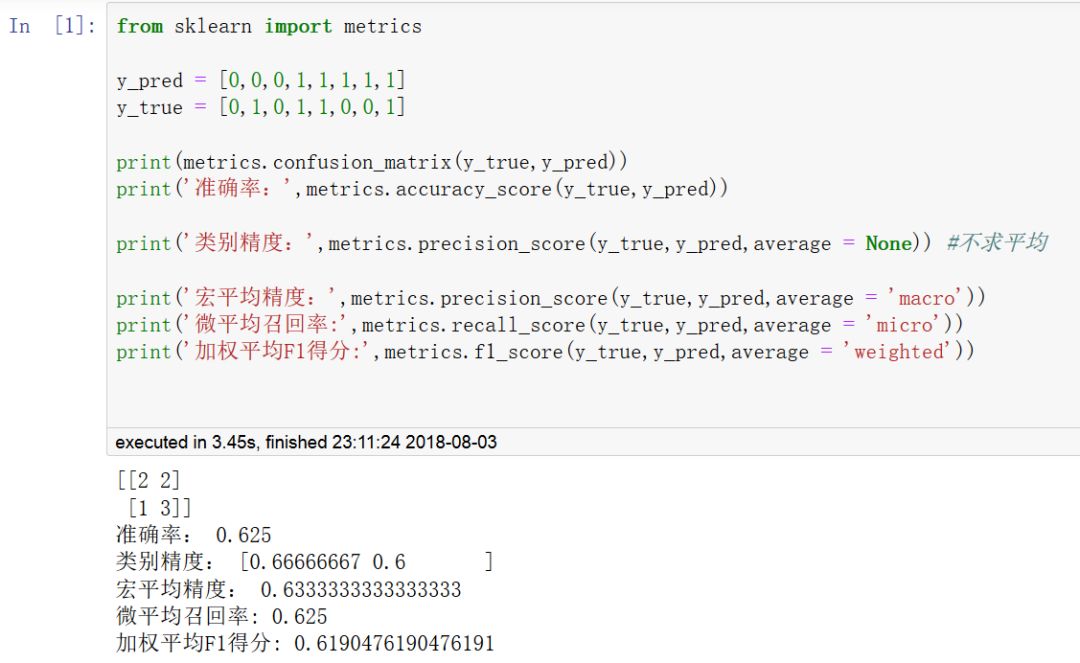
常用的分類評估指標包括:accuracy_score,f1_score,
precision_score,recall_score等等。
常用的回歸評估指標包括:r2_score,explained_variance_score等等。
常用的聚類評估指標包括:adjusted_rand_score,adjusted_mutual_info_score等等。
二,分類模型的評估
模型分類效果全部信息:
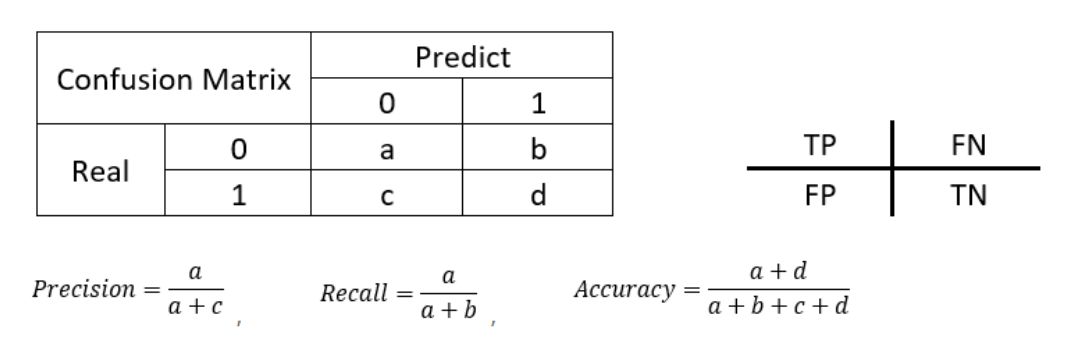
confusion_matrix 混淆矩陣,誤差矩陣。

模型整體分類效果:
accuracy 正確率。通用分類評估指標。
模型對某種類別的分類效果:
precision 精確率,也叫查準率。模型不把正樣本標錯的能力。“不冤枉一個好人”。
recall 召回率,也叫查全率。模型識別出全部正樣本的能力。“也絕不放過一個壞人”。
f1_score F1得分。精確率和召回率的調和平均值。
利用不同方式將類別分類效果進行求和平均得到整體分類效果:
macro_averaged:宏平均。每種類別預測的效果一樣重要。
micro_averaged:微平均。每一次分類預測的效果一樣重要。
weighted_averaged:加權平均。每種類別預測的效果跟按該類別樣本出現的頻率成正比。
sampled_averaged: 樣本平均。僅適用于多標簽分類問題。根據每個樣本多個標簽的預測值和真實值計算評測指標。然后對樣本求平均。
僅僅適用于概率模型,且問題為二分類問題的評估方法:
ROC曲線
auc_score
三,回歸模型的評估
回歸模型最常用的評估指標有:
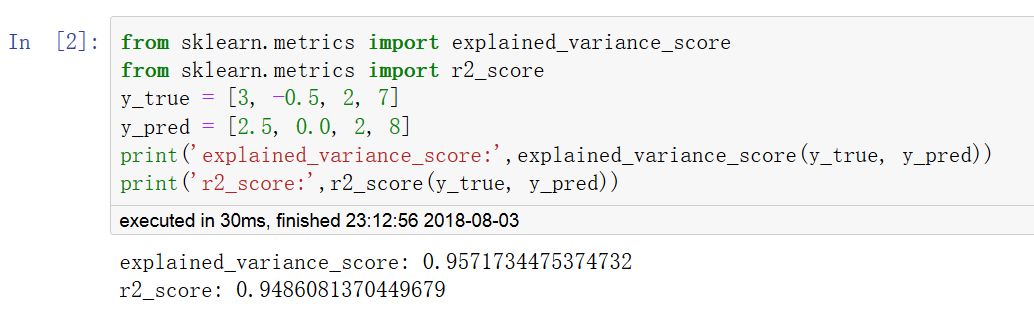
r2_score(r方,擬合優度,可決系數)
explained_variance_score(解釋方差得分)
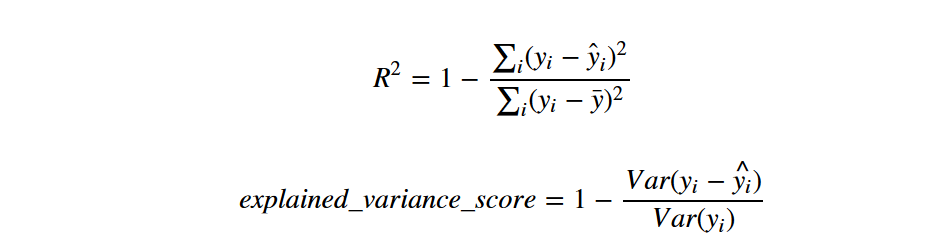
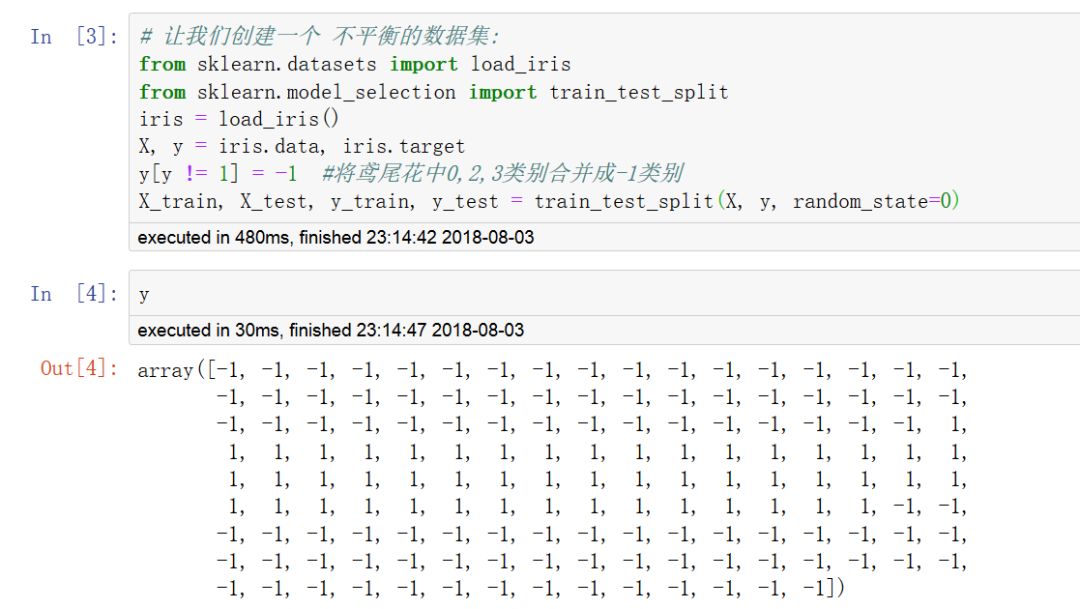
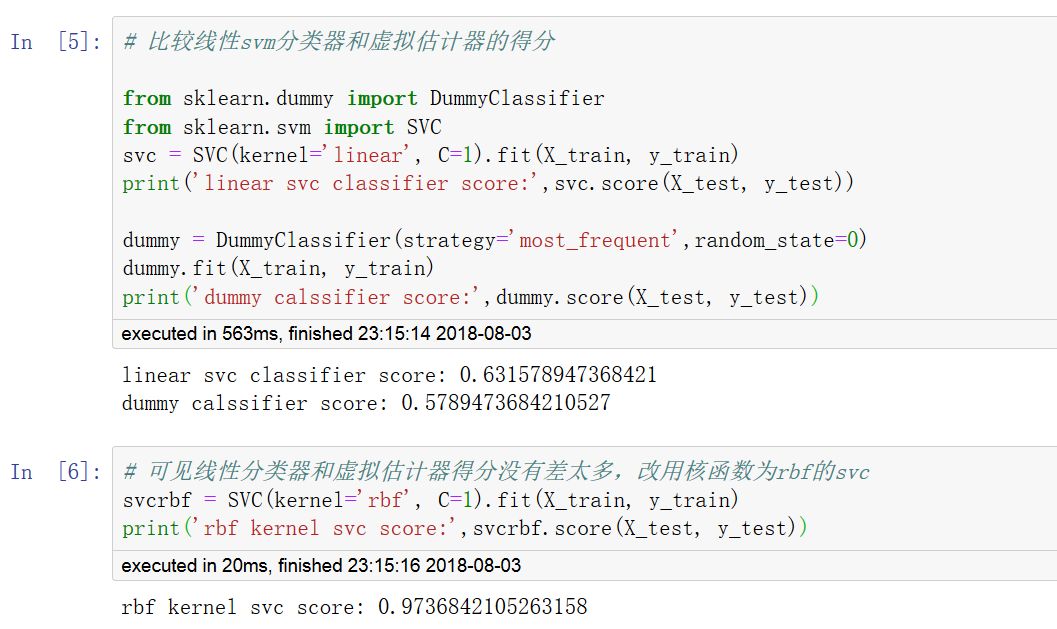
四,使用虛擬估計器產生基準得分
對于監督學習(分類和回歸),可以用一些基于經驗的簡單估計策略(虛擬估計)的得分作為參照基準值。
DummyClassifier 實現了幾種簡單的分類策略:
stratified 通過在訓練集類分布方面來生成隨機預測.
most_frequent 總是預測訓練集中最常見的標簽.
prior 類似most_frequenct,但具有precit_proba方法
uniform 隨機產生預測.
constant 總是預測用戶提供的常量標簽.
DummyRegressor 實現了四個簡單的經驗法則來進行回歸:
mean 總是預測訓練目標的平均值.
median 總是預測訓練目標的中位數.
quantile 總是預測用戶提供的訓練目標的 quantile(分位數).
constant 總是預測由用戶提供的常數值.
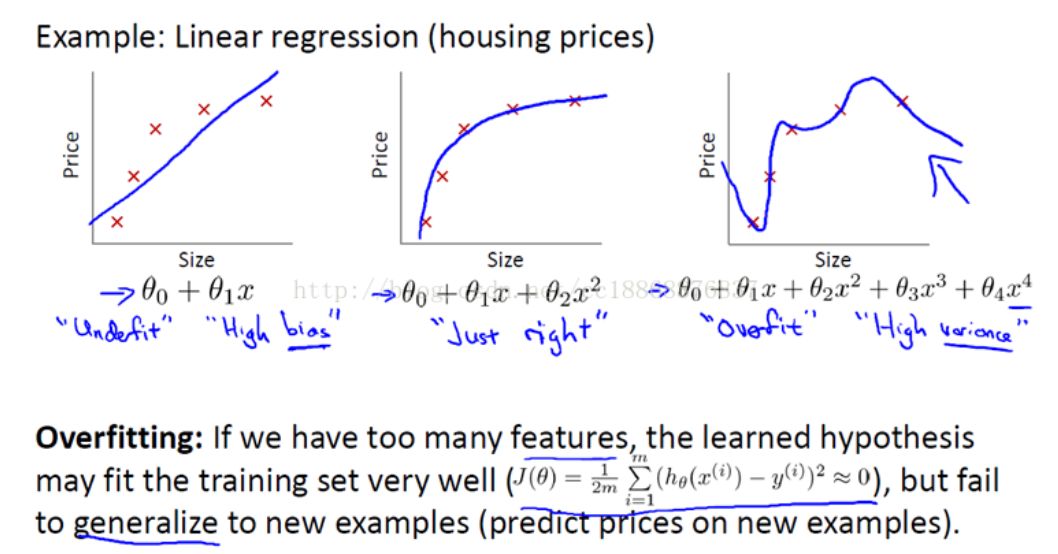
在機器學習問題中,經常會出現模型在訓練數據上的得分很高,
但是在新的數據上表現很差的情況,這稱之為過擬合overfitting,又叫高方差high variance。
而如果在訓練數據上得分就很低,這稱之為欠擬合underfitting,又叫高偏差high bias。
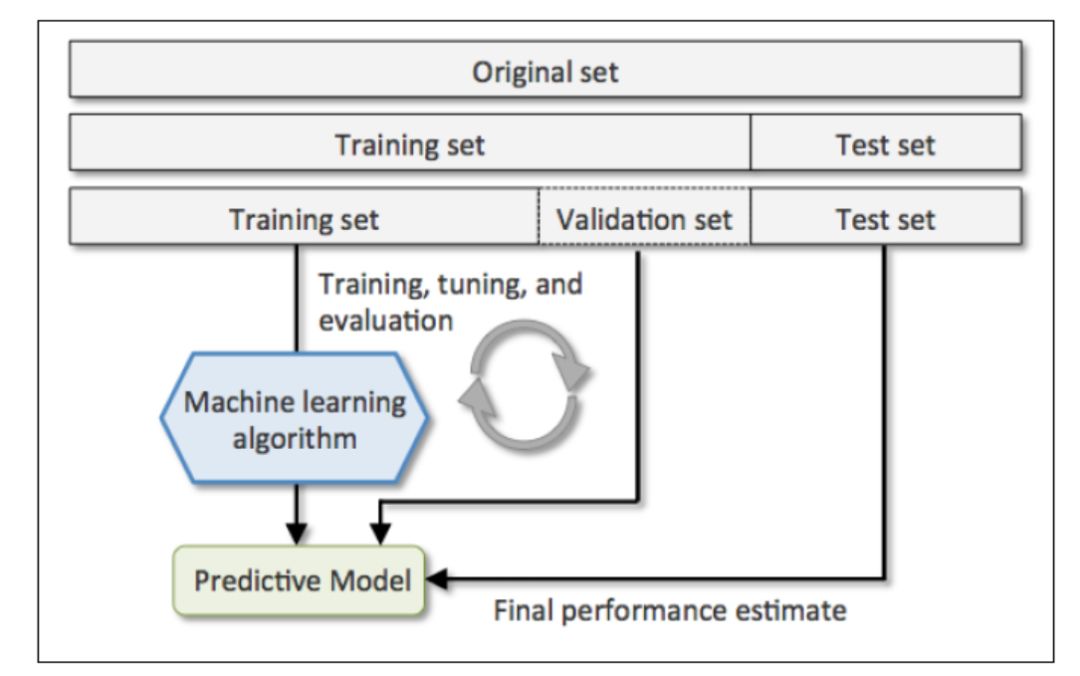
留出法
為了解決過擬合問題,常見的方法將數據分為訓練集和測試集,用訓練集去訓練模型的參數,用測試集去測試訓練后模型的表現。有時對于一些具有超參數的模型(例如svm.SVC的參數C和kernel就屬于超參數),還需要從訓練集中劃出一部分數據去驗證超參數的有效性。
交叉驗證法
在數據數量有限時,按留出法將數據分成3部分將會嚴重影響到模型訓練的效果。為了有效利用有限的數據,可以采用交叉驗證cross_validation方法。
交叉驗證的基本思想是:以不同的方式多次將數據集劃分成訓練集和測試集,分別訓練和測試,再綜合最后的測試得分。每個數據在一些劃分情況下屬于訓練集,在另外一些劃分情況下屬于測試集。
簡單的2折交叉驗證:把數據集平均劃分成A,B兩組,先用A組訓練B組測試,再用B組訓練A組測試,所以叫做交叉驗證。
常用的交叉驗證方法:K折(KFold),留一交叉驗證(LeaveOneOut,LOO),留P交叉驗證(LeavePOut,LPO),重復K折交叉驗證(RepeatedKFold),隨機排列交叉驗證(ShuffleSplit)。
此外,為了保證訓練集中每種標簽類別數據的分布和完整數據集中的分布一致,可以采用分層交叉驗證方法(StratifiedKFold,StratifiedShuffleSplit)。
當數據集的來源有不同的分組時,獨立同分布假設(independent identical distributed:i.i.d)將被打破,可以使用分組交叉驗證方法保證訓練集的數據來自各個分組的比例和完整數據集一致。(GroupKFold,LeaveOneGroupOut,LeavePGroupsOut,GroupShuffleSplit)
對于時間序列數據,一個非常重要的特點是時間相鄰的觀測之間的相關性(自相關性),因此用過去的數據訓練而用未來的數據測試非常重要。TimeSeriesSplit可以實現這樣的分割。
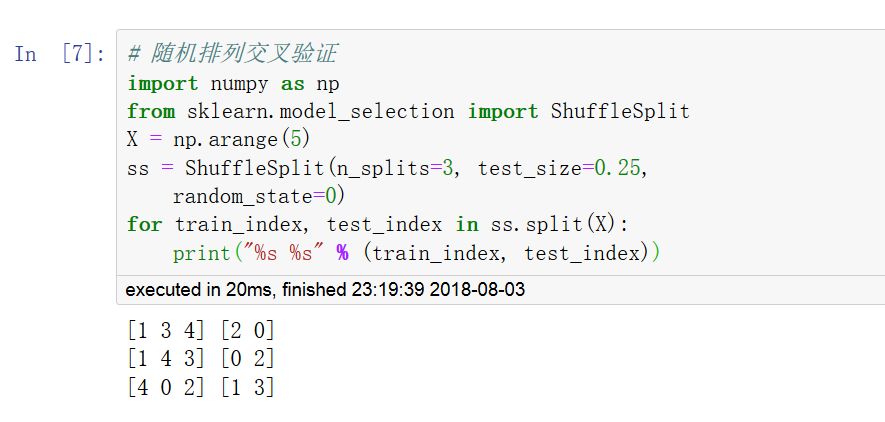
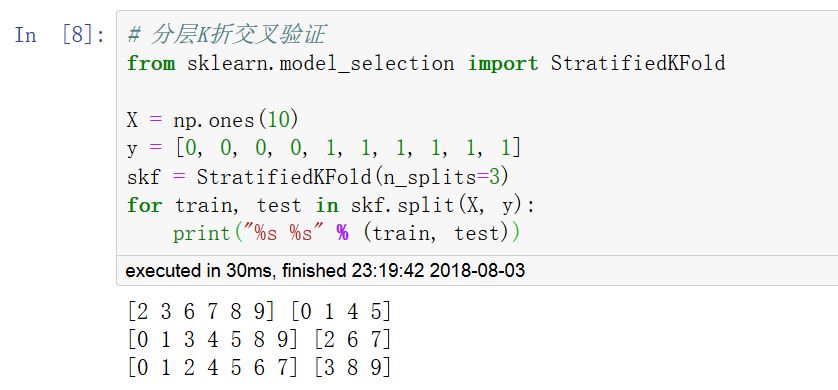
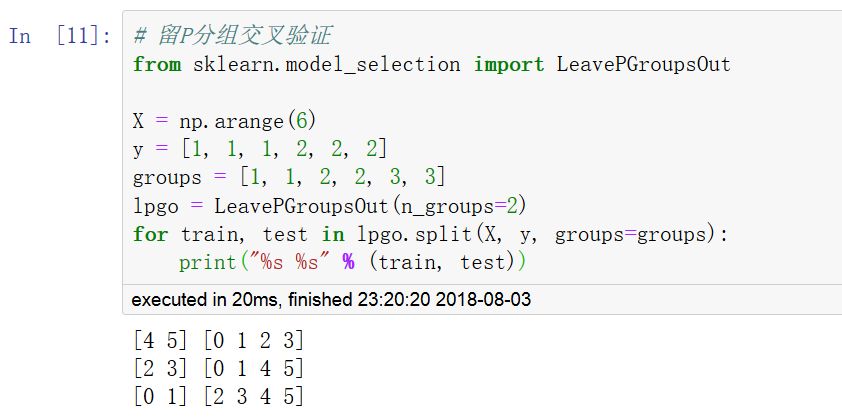
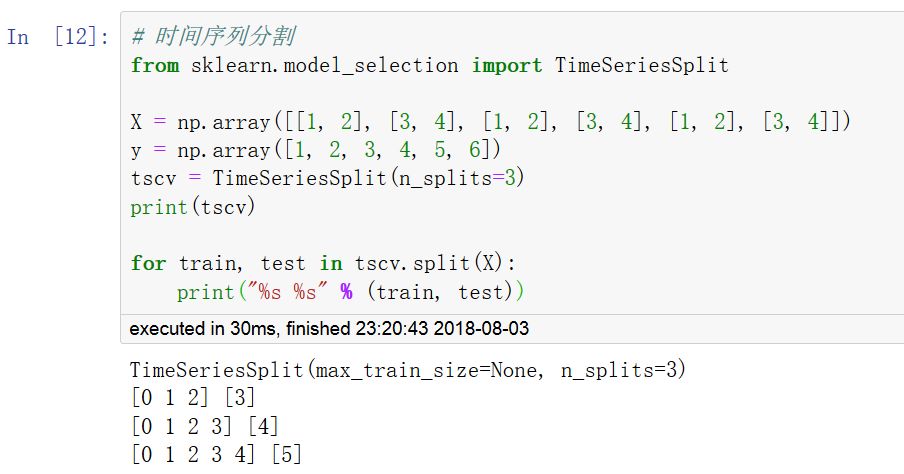
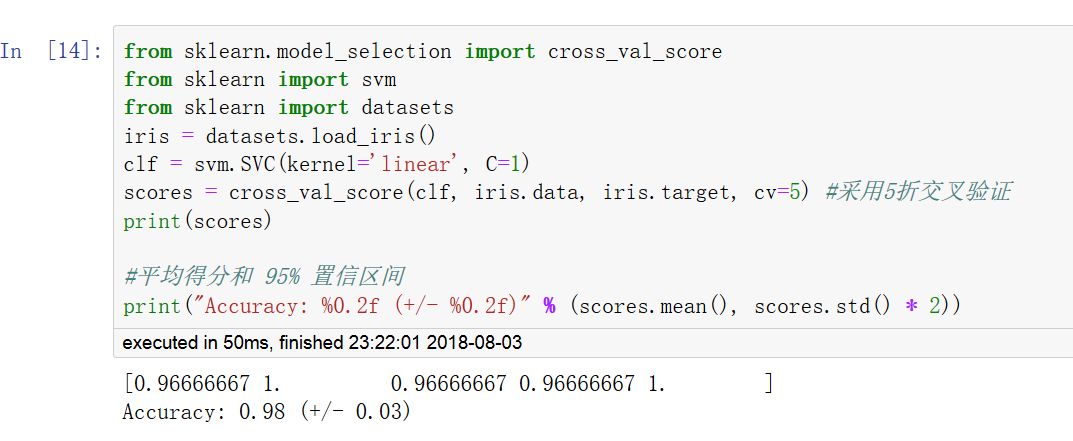
調用 cross_val_score 函數可以計算模型在各交叉驗證數據集上的得分。
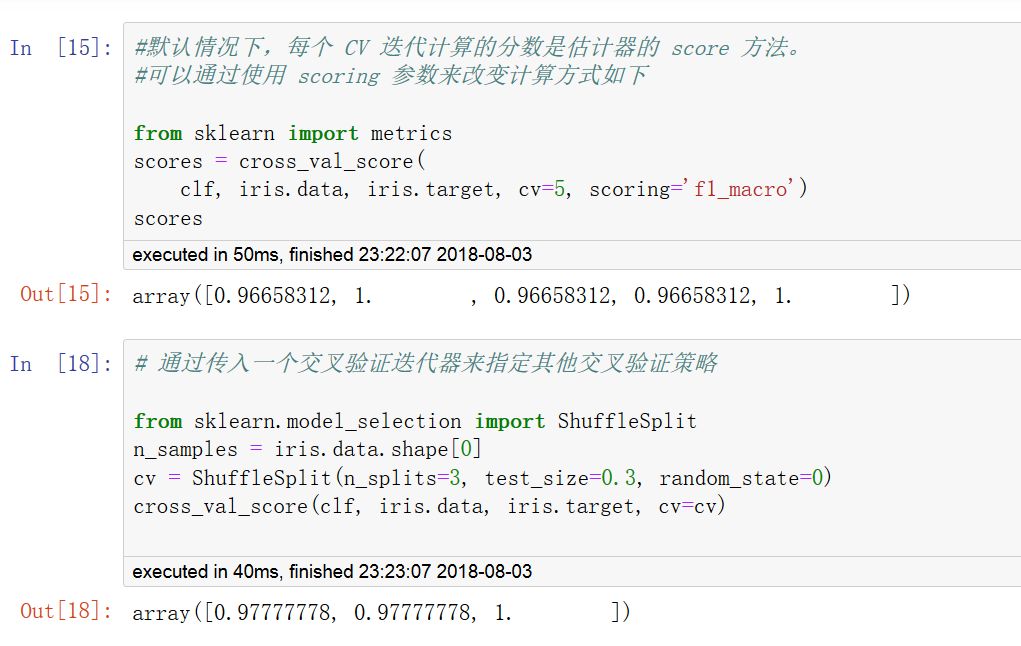
可以指定metrics中的打分函數,也可以指定交叉驗證迭代器。
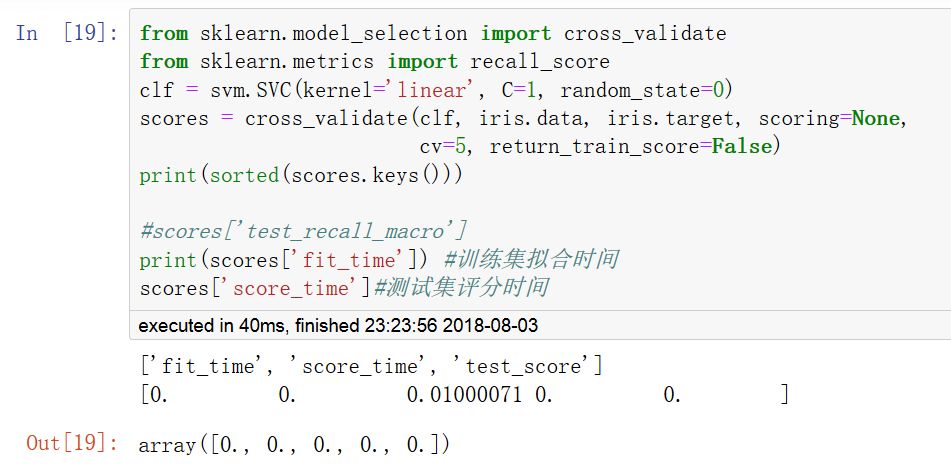
cross_validate函數和cross_val_score函數類似,但功能更為強大,它允許指定多個指標進行評估,并且除返回指定的指標外,還會返回一個fit_time和score_time即訓練時間和評分時間。
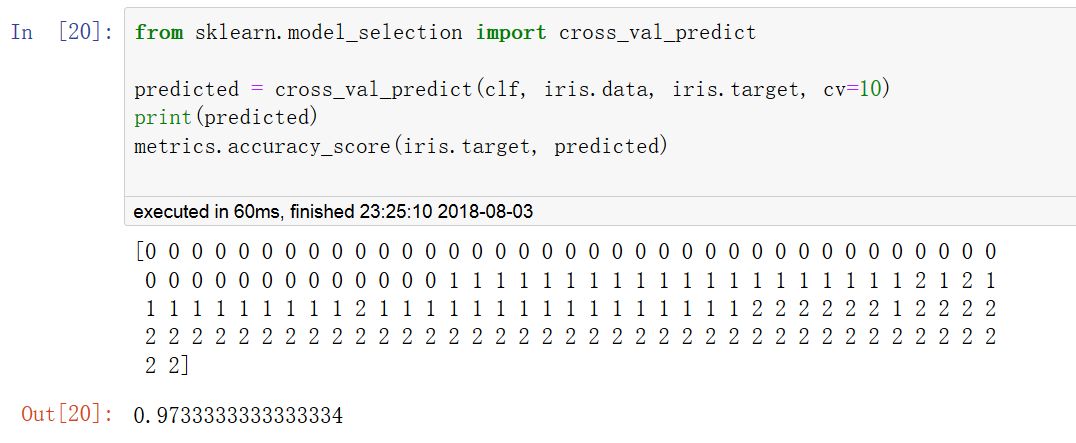
使用cross_val_predict可以返回每條樣本作為CV中的測試集時,對應的模型對該樣本的預測結果。
這就要求使用的CV策略能保證每一條樣本都有機會作為測試數據,否則會報異常。
關于“python模型的評估實例分析”這篇文章的內容就介紹到這里,感謝各位的閱讀!相信大家對“python模型的評估實例分析”知識都有一定的了解,大家如果還想學習更多知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





