溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關大數據中常用的無監督異常檢測算法技術有哪些,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
下面將介紹關于異常檢測類的文章,主要介紹了幾種無監督異常檢測方法,實驗部分僅供參考。
在仙俠劇中,有正魔之分,然何為正道,何為魔道,實屬難辨。自稱正道的人也許某一天會墮入魔道,被眾人稱為魔頭的人,或許內心自始至終都充溢著正義感!所以說,沒有絕對的黑,也沒有絕對的白。
話說回來,對于“異常”這個詞,每個人的心里大概都有一個衡量標準,擴展起來的確很廣(如異常點、異常交易、異常行為、異常用戶、異常事故等等),那么究竟何為異常呢?
異常是相對于其他觀測數據而言有明顯偏離的,以至于懷疑它與正常點不屬于同一個數據分布。異常檢測是一種用于識別不符合預期行為的異常模式的技術,又稱之為異常值檢測。
在商業中也有許多應用,如網絡入侵檢測(識別可能發出黑客攻擊的網絡流量中的特殊模式)、系統健康性監測、信用卡交易欺詐檢測、設備故障檢測、風險識別等。這里,將異常分為三種:
數據點異常:如果樣本點與其他數據相距太遠,則單個數據實例是異常的。業務用例:根據“支出金額”檢測信用卡欺詐。
上下文異常:在時間序列數據中的異常行為。業務用例:旅游購物期間信用卡的花費比平時高出好多倍屬于正常情況,但如果是被盜刷卡,則屬于異常。
集合異常:單個數據難以區分,只能根據一組數據來確定行為是否異常。業務用例:螞蟻搬家式的拷貝文件,這種異常通常屬于潛在的網絡攻擊行為。
異常檢測類似于噪聲消除和新穎性檢測。噪聲消除(NR)是從不需要的觀察發生中免疫分析的過程; 換句話說,從其他有意義的信號中去除噪聲。新穎性檢測涉及在未包含在訓練數據中的新觀察中識別未觀察到的模式。
在面對真實的業務場景時,我們往往都是滿腹激情、豪情壯志,心里默念著終于可以進入實操,干一番大事業了。然而事情往往都不是那么美好,業務通常比較特殊、背景復雜,對于業務的熟悉過程也會耗掉你大部分的時間。然后在你絞盡腦汁將其轉化為異常檢測場景后,通常又面臨著以下幾大挑戰:
不能明確定義何為正常,何為異常,在某些領域正常和異常并沒有明確的界限;
數據本身存在噪聲,致使噪聲和異常難以區分;
正常行為并不是一成不變,也會隨著時間演化,如正常用戶被盜號之后,進行一系列的非法操作;
標記數據獲取難:沒有數據,再好的算法也是無用。
針對上述挑戰,下面我們來看看具體的場景和用于異常檢測的算法。
這里將基于統計的作為一類異常檢測技術,方法比如多,下面主要介紹MA和3-Sigma。
識別數據不規則性的最簡單的方法是標記偏離分布的數據點,包括平均值、中值、分位數和模式。假定異常數據點是偏離平均值的某個標準偏差,那么我們可以計算時間序列數據滑動窗口下的局部平均值,通過平均值來確定偏離程度。這被技術稱為滑動平均法(moving average,MA),旨在平滑短期波動并突出長期波動。滑動平均還包括累加移動平均、加權移動平均、指數加權移動平均、雙指數平滑、三指數平滑等,在數學上,
缺點:
數據中可能存在與異常行為類似的噪聲數據,所以正常行為和異常行為之間的界限通常不明顯;
異常或正常的定義可能經常發生變化,因為惡意攻擊者不斷適應自己。因此,基于移動平均值的閾值可能并不總是適用。
3-Sigma原則又稱為拉依達準則,該準則定義如下:
假設一組檢測數據只含有隨機誤差,對原始數據進行計算處理得到標準差,然后按一定的概率確定一個區間,認為誤差超過這個區間的就屬于異常值。
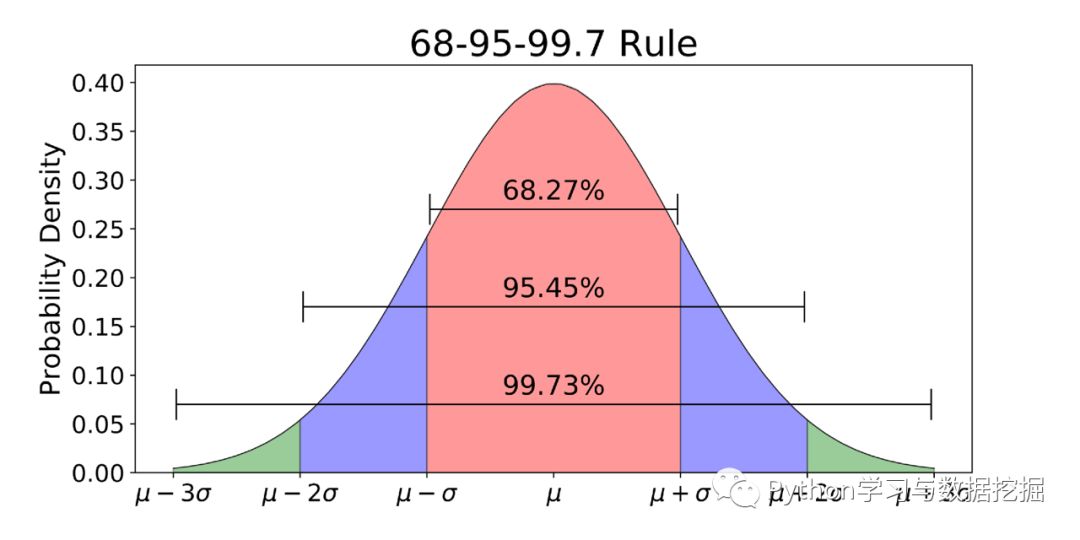
使用3-Sigma的前提是數據服從正態分布,當然如果x不服從正態分布可以使用log將其轉為正態分布。下面是3-Sigma的Python實現。
#3-sigma識別異常值def three_sigma(df_col): ''' df_col:DataFrame數據的某一列 ''' rule = (df_col.mean() - 3 * df_col.std() > df_col) | (df_col.mean() + 3 * df_col.std() < df_col) index = np.arange(df_col.shape[0])[rule] outrange = df_col.iloc[index] return outrange
對于異常值檢測出來的結果,有多種處理方式,如果是時間序列中的值,那么我們可以認為這個時刻的操作屬于異常的;如果是將異常值檢測用于數據預處理階段,處理方法有以下四種:
刪除帶有異常值的數據;
將異常值視為缺失值,交給缺失值處理方法來處理;
用平均值進行修正;
當然我們也可以選擇不處理。
基于密度的異常檢測有一個先決條件,即正常的數據點呈現“物以類聚”的聚合形態,正常數據出現在密集的鄰域周圍,而異常點偏離較遠。對于這種場景,我們可以計算得分來評估最近的數據點集,這種得分可以使用Eucledian距離或其它的距離計算方法,具體情況需要根據數據類型來定:類別型或是數字型。
iForest(isolation forest,孤立森林)算法是一種基于Ensemble的快速異常檢測方法,具有線性時間復雜度和高精準度,該算法是劉飛博士在莫納什大學就讀期間由陳開明(Kai-Ming Ting)教授和周志華(Zhi-Hua Zhou)教授指導發表的,與LOF、OneClassSVM相比,其占用的內存更小、速度更快。算法原理如下:

算法部分的代碼如下:
classifiers = {"Isolation Forest":IsolationForest(n_estimators=100, max_samples=len(X), contamination=0.005,random_state=state, verbose=0)}def train_model(clf, train_X): #Fit the train data and find outliers clf.fit(X) #scores_prediction = clf.decision_function(X) y_pred = clf.predict(X) return y_pred, clfy_pred,clf = train_model(clf=classifiers["Isolation Forest"], train_X=X)
以上就是大數據中常用的無監督異常檢測算法技術有哪些,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





