溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
SQL,在數據處理和分析領域基本上類似“普通話”的地位,幾乎是一項必備的能力,但是要使用 SQL,又離不開關系數據庫系統,也就是 RDBMS,這就好比普通話主要還是得在中國說才管用。當然,如果為了去英國美國,學個英語還算值,這就像學個 Python、Hadoop,出去找工作也算是個技能。但是如果要在一般的文本數據,或者 Excel 表格上作分析,就像是去個基里巴斯之類的小國家,為了能夠愉快的購物,難道還要卷起舌頭,從背單詞、學語法開始?這種時候,恐怕第一時間想到的,就是上某寶,淘個好用的翻譯器吧。
集算器,在這個問題上,可以說是一款居家旅行的必備神器了!
事實上,用 SQL 處理結構規整的文本或者 Excel 表格數據,除了是一種偷懶的想法外,也是一個很自然的思路。一個文件或者表格由若干數據行構成,而每行數據要么由確定的分隔符(空格、逗號、制表符……巴拉巴拉)分隔項目,要么就是規定了每個項目的固定長度。這種表示方式,和關系數據庫中的表(Table)幾乎是如出一轍,連變長字段和定長字段也都似乎有模有樣。不同之處,是文件上沒有主鍵、數據類型、是否可空這些概念。另外,就是文件之間關系的說明也沒有像數據庫那樣明確,往往只是作為業務規則或者經驗,存在于用戶的腦袋里或者一些給人看的文件里面。
集算器的思路,也是如此,通過自動解析結構化文本或者 Excel 文件,將文件映射為 “表”,并在此基礎上,充分支持 SQL 的語法和功能。
好了,閑言少敘,進入正題。我們以兩個有關聯的文件作為樣例,看看如何在不“安裝數據庫 -> 建數據庫表 -> 導入數據”的情況下,輕輕松松地進行查詢分析:
首先,看一下樣例數據,一共是兩個文件:員工信息(employee.txt)和州的基本信息(state.xlsx),注意!這里我們使用了兩種文件,一個是格式化的 TXT 文本,另一個是 Excel 電子表格,也就是說,集算器可以同時連接不同類型的數據源,神不神奇?意不意外?
更神奇的是,集算器可以根據文件后綴,自動識別和讀取四種文件類型!分別是:文本(txt)、Excel(xls、xlsx)和 csv 文件。
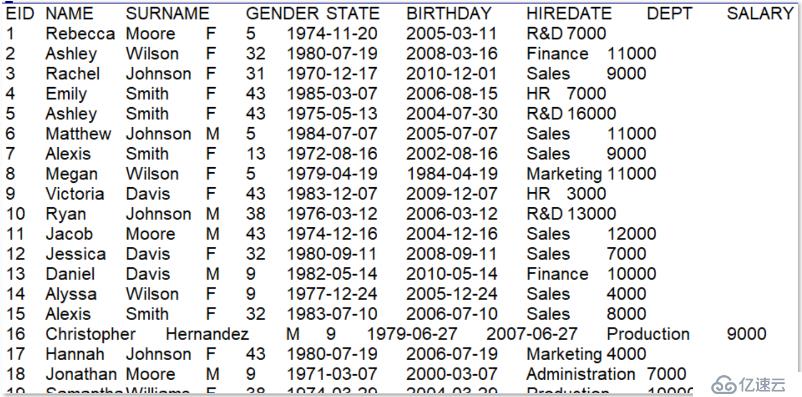
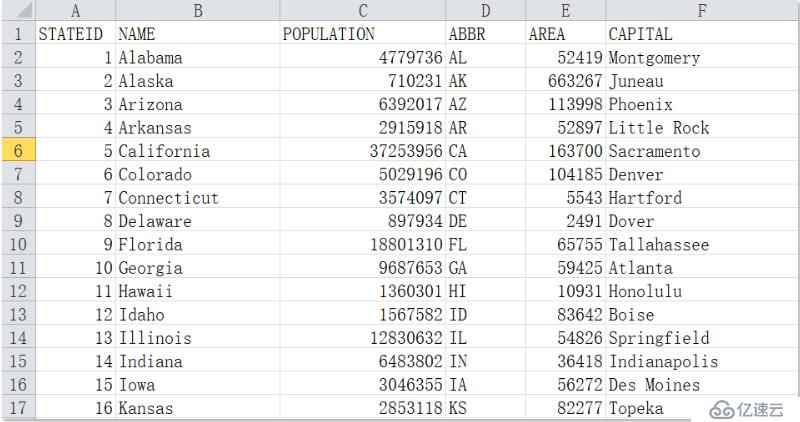
下面兩張圖分別是員工信息和州信息的樣本數據,兩個文件之間通過員工信息中的 STATE 項(第 5 列)和州信息中的 STATEID 項(第 1 列)進行關聯。
員工信息數據樣本:
州信息數據樣本:
好了,馬上開始干活。首先,最簡單的單表查詢,看看員工中薪酬大于 10000(SALARY>10000)的女(GENDER=’F’)員工,輸出結果按照員工編號(EID)排序,集算器代碼如下:
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select * from c:/sql/employee.txt where gender=’F’ and salary>10000 order by eid”) |
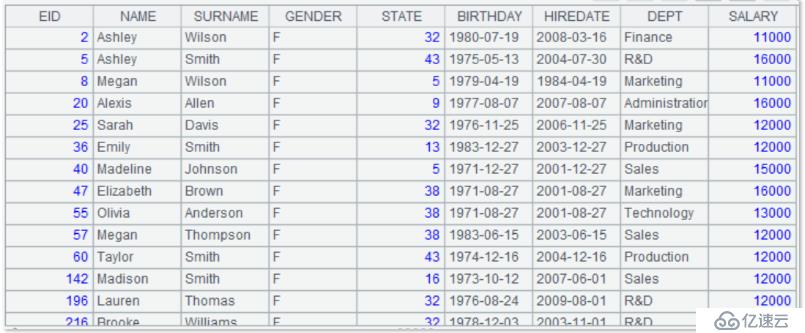
沒錯,就這么簡單,就這么熟悉!第 1 步,連接數據庫……呃,這里沒有指定參數,所以直接連接的就是文件系統,第 2 步,使用 query() 函數執行 SQL 查詢,而這里的 SQL,除了把 from 后的表名,換成了文件名,別的和數據庫查詢一模一樣!查詢結果如下:
注意,windows 環境下,集算器里的文件路徑用斜杠“/”而不是反斜杠“\”,這和 Java 語言一致。
好吧,這也太像了,下面我們來個不太像的,查詢不早于 1980 年 01 月 01 日出生的,薪酬大于 10000 的員工:
| A | |
|---|---|
| 1 | $()select * from c:/sql/employee.txt where BIRTHDAY>=date(‘1980-01-01’) and SALARY>10000 |
很簡單,使用 $()相當于 connect() 函數,后面直接寫 SQL 即可。事實上,括號中可以寫不同的數據源名稱,從而同時連接多個數據源。
另外,這個例子使用了 SQL 中的字符串轉日期的函數 date()。
接下來,是 SQL 數據庫有別于單個文件的關鍵,關聯查詢。對于薪酬大于 10000 的女員工,還想再看看她們都在哪個州:
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select t1.eid eid,t1.name name,t1.gender gender,t2.name state,t2.population population,t1.salary salary from c:/sql/employee.txt t1 left join c:/sql/state.xlsx t2 on t1.state=t2.stateid where t1.gender=’F’ and t1.salary>10000 “) |
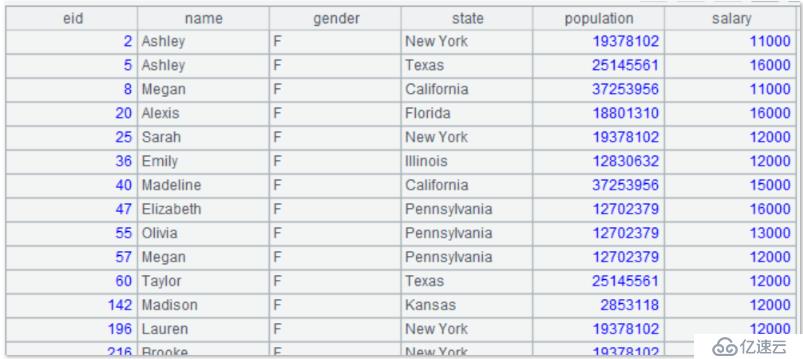
嗯,用文件名代替表名確實有點長,所以我們用了 SQL 中別名的用法,結果如下:
除了使用別名代替文件的絕對路徑,對于特別長的路徑或者文件很多的情況,為了方便書寫和清晰閱讀,還可以在集算器 - 菜單 - 工具 - 選項中配置主目錄,這樣就可以在 SQL 中直接使用文件名或者相對路徑了。這是不是更像指定了一個數據庫,直接訪問其中的表了?
配置方法如下圖所示:
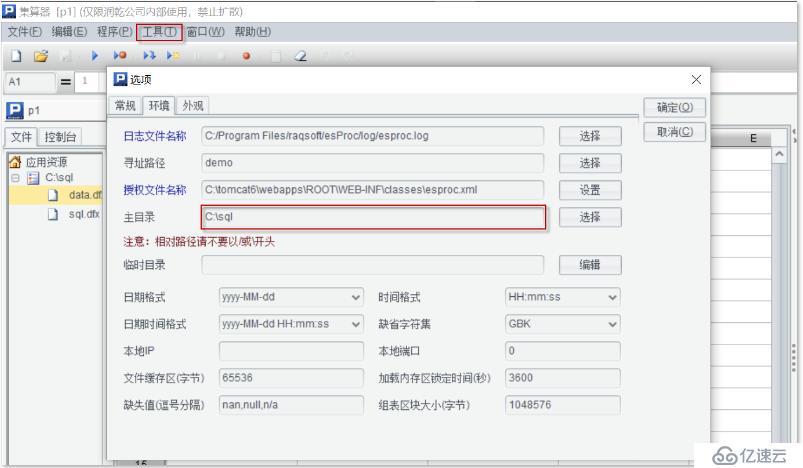
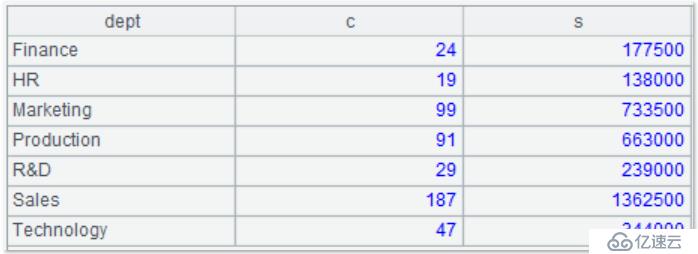
配置了主目錄后的查詢是這個樣子,查詢工資總額大于 100000 的部門對應的人數和工資總額:
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select dept,count(1) c,sum(salary) s from employee.txt group by dept having s>100000”) |
查詢結果如下:
下面,進入一些細節內容:
1)集算器支持邏輯運算 and、or 和 not,例如:查詢員工姓 Smith 或者 Robinson,并且是 Sales 部門之外的男員工:
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select * from employee.txt where (surname=’Smith’ or surname=’Robinson’) and gender=’M’ and not dept=’Sales’ “) |
2)集算器中,支持用 is null 來判斷是否為空,用 is not null 判斷非空,例如:找出 surname 為空的員工:
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select EID,NAME,SURNAME from employee.txt where surname is null”) |
同時支持用 coalesce 函數處理空值,例如:員工 surname 字段為空時在結果中顯示為“UNKNOWN”:
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select EID,NAME,SURNAME,coalesce(SURNAME,’UNKNOWN’) as SURNAME1 from employee.txt”) |
查詢結果為:
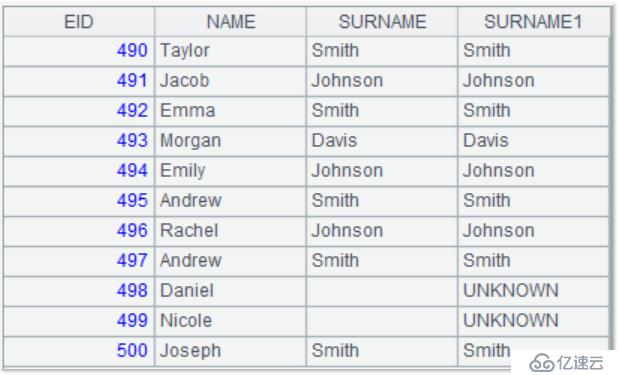
注意:集算器中的字段別名,不能和文件中的字段名重復。
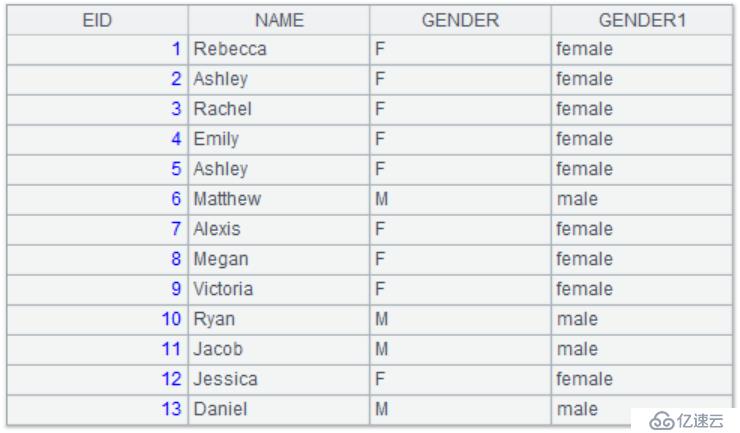
3)集算器支持 Case when,例如:性別字段為“F”的要顯示為“female”,為“M”的要顯示為“male”。
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select EID,NAME,GENDER,(case gender when ‘F’ then ‘female’ else ‘male’ end) as GENDER1 from employee.txt”) |
查詢結果為:
4)集算器支持 like 關鍵字進行模糊查詢,例如:在員工中,查詢 surname 字段包含“son”的員工。
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select * from employee.txt where surname like ‘%son%’”) |
其中的“%”為通配符,表示一個或者多個字符。另外,“_”表示一個字符。如果要查詢以“son”結尾,并且前面有三個字符的情況,可以寫成 surname like ‘___son’;“[WJ]”表示包含“W”和“J”的字符列表。surname like ‘[WJ]%’表示 surname 是以“W”或者“J”開頭。surname like ‘[!WJ]%’表示 surname 不是以“W”或者“J”開頭。
5)集算器支持通過 In 關鍵字在多個值中查詢數據。例如:查詢“Finance、Sales、R&D”三個部門的員工。
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select * from employee.txt where dept in (‘Finance’,’Sales’,’R&D’) “) |
6)集算器支持通過 with T as (x) 的方式定義一個外部表。例如:employee.txt 中的 state 字段和另一個數據源 demo 數據庫的 state 表的 stateid 字段左連接,查出每個員工所在州的名字和人口:
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“with t2 as (connect(\”demo\”).query(\”select * from states\”)) select t1.eid eid,t1.name name,t1.gender gender,t2.name state,t2.population population,t1.salary salary from employee.txt t1 left join t2 on t1.STATE=t2.STATEID”) |
在這個 SQL 中:
with t2 as (connect(\”demo\”).query(\”select * from states\”)) 定義了一個外部表 t2,連接 demo 數據源(實際上是集算器自帶的 hsql 演示數據庫),用 query 函數執行 SQL“select * from states”。(其中,\”是在字符串中使用雙引號的轉義寫法)
后邊的“select t1.eid … left join t2 on t1.STATE=t2.STATEID”則利用定義好的 t2 和 employee.txt 左連接,查出每個員工所在州的名字和人口。
這個查詢是典型的數據庫和文本文件的聯合查詢。實際上,with 關鍵字可以定義各種數據源查出的數據,從而非常靈活的實現跨異構數據源的聯合查詢。
7)集算器支持通過 into to 將查詢結果輸出的文件中。例如:查詢工資總額大于 100000 的部門對應的人數和工資總額,結果寫入 deptResult.xlsx。這里,新的文件就類似關系數據數據庫里的一個新表。
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select dept,count(1) c,sum(salary) s into deptResult.xlsx from employee.txt group by dept having s>100000”) |
說了這么多,可以看出,通過集算器,我們就能夠基本實現在結構化的文本數據(txt、csv 等)和 Excel 文件(xls、xlsx)上輕松、直接地使用 SQL。
當然,集算器并不是完全“平移”復制了 SQL 的能力,對于 SQL 中的子查詢,集算器目前并不能直接支持,而是會以更加靈活、方便、直觀的分步式計算方式加以解決。同時,對于有些特殊的 join 計算,集算器和傳統數據庫相比會慢一點。
最后,我們再來看看通過集算器進行 SQL 計算,還能額外獲得哪些福利:
1)根據輸入參數動態計算:
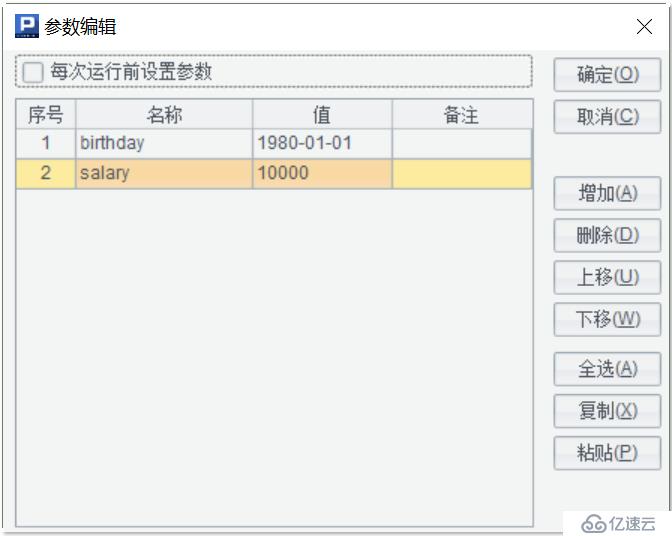
在進行數據查詢時,常常需要根據不同的條件進行計算,也就是我們說的動態執行。這時,我們可以定義“網格參數”,為可能發生變化的條件預留位置。例如:想要找出公司里較高薪水的年輕員工有哪些,但是年齡段和薪酬起始線還不確定,我們就可以在集算器 IDE 的菜單“程序 / 網格參數”中,定義兩個參數:birthday 和 salary:
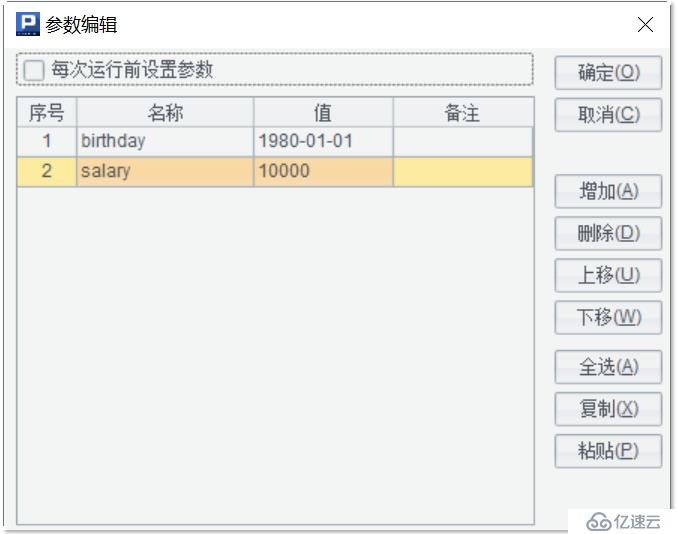
然后在查詢語句中用占位符“?”寫出 SQL,并按順序指定對應的網格參數名作為輸入:
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select * from employee.txt where BIRTHDAY>=? and SALARY>?”,birthday,salary) |
如果在定義網格參數的時候指定了具體的數值,并且沒有勾選“每次運行前設置參數”那么運行腳步會直接指定的數值。如果勾選了“每次運行前設置參數”,那么每次運行腳本的時候,都會彈出“設置參數值”窗口。這樣,我們就可以隨時輸入我們需要的參數值了,相應地,查詢結果也會隨之改變了:
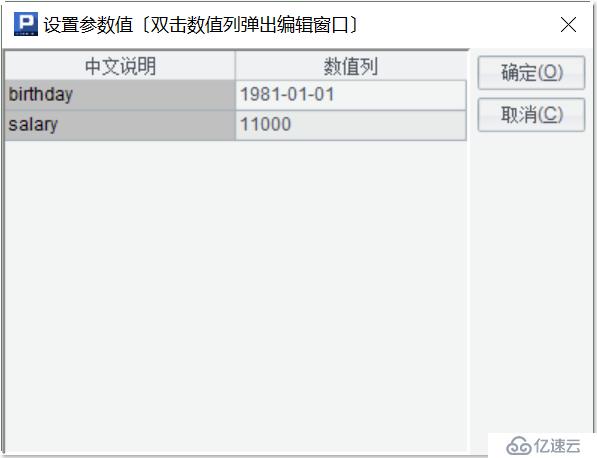
2)在命令行中使用 SQL 查詢文件
在 windows 或者 linux 系統中,我們還可以通過命令行中調用編寫好的集算器腳本,直接對文件數據進行查詢。如果結合操作系統的定時任務機制,就可以在指定時間完成批量數據計算了。
我們先看一個不返回結果集的例子。定期為財務部門提供工資總額大于 100000 的部門對應的人數和工資總額,結果寫入 deptResult.xlsx(然后可以通過郵件或其他方式發送給相關人員)。
首先,編寫集算器腳本,并保存為 deptResult.dfx。
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select dept,count(1) c,sum(salary) s into deptResult.xlsx from employee.txt group by dept having s>100000”) |
| 3 | >output(“create deptResult.xlsx successfully!”) |
然后,在命令行執行 esprocx.exe 命令,(在集算器安裝目錄的 bin 文件夾中),執行結果:
| C:\Program Files\raqsoft\esProc\bin>esprocx.exe deptResult.dfxcreate deptResult.xlsx successfully! |
其中,第二行是 Output 函數輸出的提示信息,可以用于監控程序執行和調試。
我們再看一個返回結果集的例子,同樣的查詢需求,但是不要求輸出到文件中,而是直接查看結果。這次我們把編寫的集算器腳本換個名字存為 deptQuery.dfx。
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select dept,count(1) c,sum(salary) s from employee.txt group by dept having s>100000”) |
| 3 | return A2 |
在命令行中的執行并查看結果:
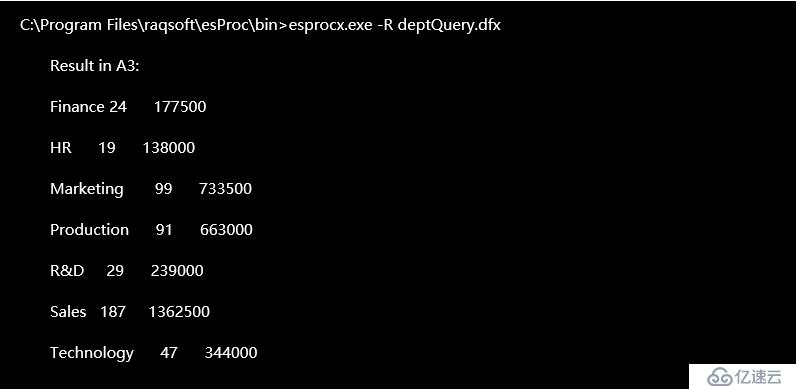
更進一步,集算器也可以做到直接在命令行寫完整的 SQL 語句,直接從文件中返回需要查詢的結果。是不是和數據庫命令行查詢工具一樣方便?
先定義一個參數 sql,用來傳入需要查詢的 SQL 語句。
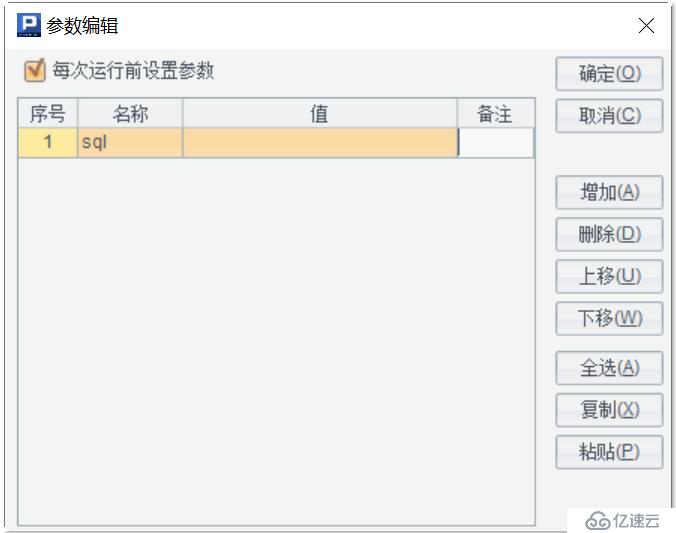
然后編寫如下集算器腳本,保存為 query.dfx,
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(sql) |
| 3 | return A2 |
執行命令時,在命令行中直接寫 SQL 語句,結果如下:
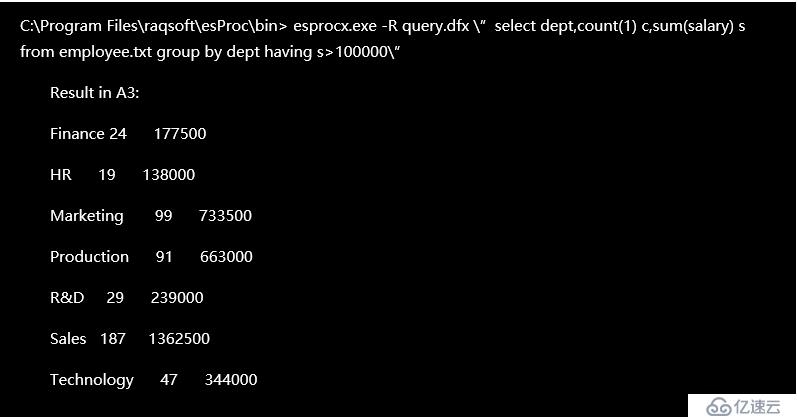
結合前面說的根據參數動態計算的方法,也可以在使用命令行計算時實現一定的交互。還是以前面說過的查詢公司里薪酬較高的年輕員工為例:
在集算器 IDE 菜單“程序 / 網格參數”中,定義兩個參數:birthday 和 salary。
編寫如下集算器腳本,保存為 empQueryParam.dfx,
| A | |
|---|---|
| 1 | =connect() |
| 2 | =A1.query(“select * from employee.txt where BIRTHDAY>=? and SALARY>?”,birthday,salary) |
| 3 | return A2 |
執行命令時,按照順序為兩個參數提供數值,結果如下:

至此,我們已經充分了解了利用集算器,就可以用 SQL 這把“金剛鉆”來攬數據文件這些“瓷器活兒”了。其實,這個故事里,集算器才是真正的“金剛鉆”!除了本文描述的將數據文件直接作為“表”來處理的方式,集算器真正有力的武器庫遠不止此。通過這款輕量級的數據分析工具,無論是數據庫還是文件系統中的數據,都可以被輕松處理,快刀斬亂麻!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





