溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關基于消息隊列的分布式事務解決方案是什么,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
在我們還在“牙牙學語”的時候,老師經常會通過轉賬的栗子來跟我們講解事務,但跟這里場景不一樣的是,老師講的是本地事務,而這里面對的是分布式事務!我們先來簡單回顧一下本地事務!
?? 談到本地事務,大家可能都很熟悉,因為這個數據庫引擎層面能支持的!所以也稱數據庫事務,數據庫事務四大特征:原子性(A),一致性(C),隔離性(I)和持久性(D),而在這四大特性中,我認為一致性是最基本的特性,其它的三個特性都為了保證一致性而存在的!
?? 回到學生時代老師給我們舉的經典栗子,A賬戶給B賬戶轉賬100元(A、B處于同一個庫中),如果A的賬戶發生扣款,B的賬戶卻沒有到賬,這就出現了數據的不一致!為了保證數據的一致性,數據庫的事務機制會讓A賬戶扣款和B在賬戶到賬的兩個操作要么同時成功,如果有一個操作失敗,則多個操作同時回滾,這就是事務的原子性,為了保證事務操作的原子性,就必須實現基于日志的REDO/UNDO機制!但是,僅有原子性還不夠,因為我們的系統是運行在多線程環境下,如果多個事務并行,即使保證了每一個事務的原子性,仍然會出現數據不一致的情況。例如A賬戶原來有200元的余額, A賬戶給B賬戶轉賬100元,先讀取A賬戶的余額,然后在這個值上減去100元,但是在這兩個操作之間,A賬戶又給C賬戶轉賬100元,那么最后的結果應該是A減去了200元。但事實上,A賬戶給B賬戶最終完成轉賬后,A賬戶只減掉了100元,因為A賬戶向C賬戶轉賬減掉的100元被覆蓋了!所以為了保證并發情況下的一致性,又引入的隔離性,即多個事務并發執行后的狀態,和它們串行執行后的狀態是等價的!隔離性又有多種隔離級別,為了實現隔離性(最終都是為了保證一致性)數據庫又引入了悲觀鎖、樂觀鎖等等……本文的主題是分布式事務,所以本地事務就只是簡單回顧一下,需要記住的一點是,事務是為了保證數據的一致性!
??還記得剛畢業那年,帶著滿腔的熱血就去到了一家互聯網公司,領導給我的第一個任務就是在列表上增加一個修改數據的功能。這能難倒我?我分分鐘給你搞出來!不就是在列表上增加了一個“修改”按鈕,點擊按鈕彈出框修改后保存就好了么。然而一切不像我想象的那么順利,點擊保存并刷新列表后,頁面上的數據還是顯示的修改之前的內容,像沒有修改成功一樣!過一會兒再刷新列表,數據就能正常顯示了!測試多次之后都是這樣!沒見過什么大場面的我開始有點慌了,是我哪里寫得不對么?最終,我不得不求助組內經驗比較豐富的前輩!他深吸了一口氣告訴我說:“畢竟是剛畢業的小伙子啊!我來跟你講講原因吧!我們的數據庫是做了讀寫分離的,部分讀庫與寫庫在不同的網絡分區。你的數據更新到了寫庫,而讀數據的時候是從讀庫讀取的。更新到寫庫的數據同步到讀庫是有一定的延遲的,也就是說讀庫與寫庫會有短暫的數據不一致”!“這樣不會體驗不好么?為什么不能做到寫入的數據立馬能讀出來?那我這個功能該怎么實現呢?” 面對我的一堆問題,同事有些不耐煩的說:“聽說過CAP理論嗎?你先自己去了解一下吧”!是我開始查閱各種資料去了解這個陌生的詞背后的秘密!
??CAP理論是由加州大學Eric Brewer教授提出來的,這個理論告訴我們,一個分布式系統不可能同時滿足一致性(Consistency)、可用性(Availability)、分區容錯性(Partition tolerance)這三個基本需求,最多只能同時滿足其中兩項。
??一致性:這里的一致性是指數據的強一致,也稱為線性一致性。是指在分布式環境中,數據在多個副本之間是否能夠保持一致的特性。也就是說對某個數據進行寫操作后立馬執行讀操作,必須能讀取到剛剛寫入的值。(any read operation that begins after a write operation completes must return that value, or the result of a later write operation) ??可用性:任意被無故障節點接收到的請求,必須能夠在有限的時間內響應結果。(every request received by a non-failing node in the system must result in a response) ??分區容錯性:如果集群中的機器被分成了兩部分,這兩部分不能互相通信,系統是否能繼續正常工作。(the network will be allowed to lose arbitrarily many messages sent from one node to another)
??在分布式系統中,分區容錯性是基本要保證的。也就是說只能在一致性和可用性之間進行取舍。一致性和可用性,為什么不可能同時成立?回到之前修改列表的例子,由于數據會分布在不同的網絡分區,必然會存在數據同步的問題,而同步會存在網絡延遲、異常等問題,所以會出現數據的不一致!如果要保證數據的一致性,那么就必須在對寫庫進行操作時,鎖定其他讀庫的操作。只有寫入成功且完成數據同步后,才能重新放開讀寫,而這樣在鎖定期間,系統喪失了可用性。更詳細關于CAP理論可以參考這篇文章(https://mwhittaker.github.io/blog/an_illustrated_proof_of_the_cap_theorem/),該文章講得比較通俗易懂!
?? 分布式事務就是在分布式的場景下,需要滿足事務的需求!上篇文章我們聊過了消息中間件,那這篇文章我們要聊的是分布式事務,把兩者一結合,便有了基于消息中間件的分布式事務解決方案!不管是本地事務,還是分布式事務,都是為了解決數據的一致性問題!一致性這個詞咱們前面多次提及!與本地事務不同的是,分布式事務需要保證的是分布式環境下,不同數據庫表中的數據的一致性問題。分布式事務的解決方案有多種,如XA協議、TCC三階段提交、基于消息隊列等等,本文只會涉及基于消息隊列的解決方案!
?? 本地事務講到了一致性,分布式事務不可避免的面臨著一致性的問題!回到最開始跨行轉賬的例子,如果A銀行用戶向B銀行用戶轉賬,正常流程應該是:
1、A銀行對轉出賬戶執行檢查校驗,進行金額扣減。
2、A銀行同步調用B銀行轉賬接口。
3、B銀行對轉入賬戶進行檢查校驗,進行金額增加。
4、B銀行返回處理結果給A銀行。
?? 
?? 在正常情況對一致性要求不高的場景,這樣的設計是可以滿足需求的。但是像銀行這樣的系統,如果這樣實現大概早就破產了吧。我們先看看這樣的設計最主要的問題:
1、同步調用遠程接口,如果接口比較耗時,會導致主線程阻塞時間較長。
2、流量不能很好控制,A銀行系統的流量高峰可能壓垮B銀行系統(當然B銀行肯定會有自己的限流機制)。
3、如果“第1步”剛執行完,系統由于某種原因宕機了,那會導致A銀行賬戶扣款了,但是B銀行沒有收到接口的調用,這就出現了兩個系統數據的不一致。
4、如果在執行“第3步”后,B銀行由于某種原因宕機了而無法正確回應請求(實際上轉賬操作在B銀行系統已經執行且入庫),這時候A銀行等待接口響應會異常,誤以為轉賬失敗而回滾“第1步”操作,這也會出現了兩個系統數據的不一致。
?? 對于問題的1、2都很好解決,如果對消息隊列熟悉的朋友應該很快能想到可以引入消息中間件進行異步和削峰處理,于是又重新設計了一個方案,流程如下:
1、A銀行對賬戶進行檢查校驗,進行金額扣減。
2、將對B銀行的請求異步寫入隊列,主線程返回。
3、啟動后臺程序從隊列獲取待處理數據。
4、后臺程序對B銀行接口進行遠程調用。
5、B銀行對轉入賬戶進行檢查校驗,進行金額增加。
6、B銀行處理完成回調A銀行接口通知處理結果。
?? 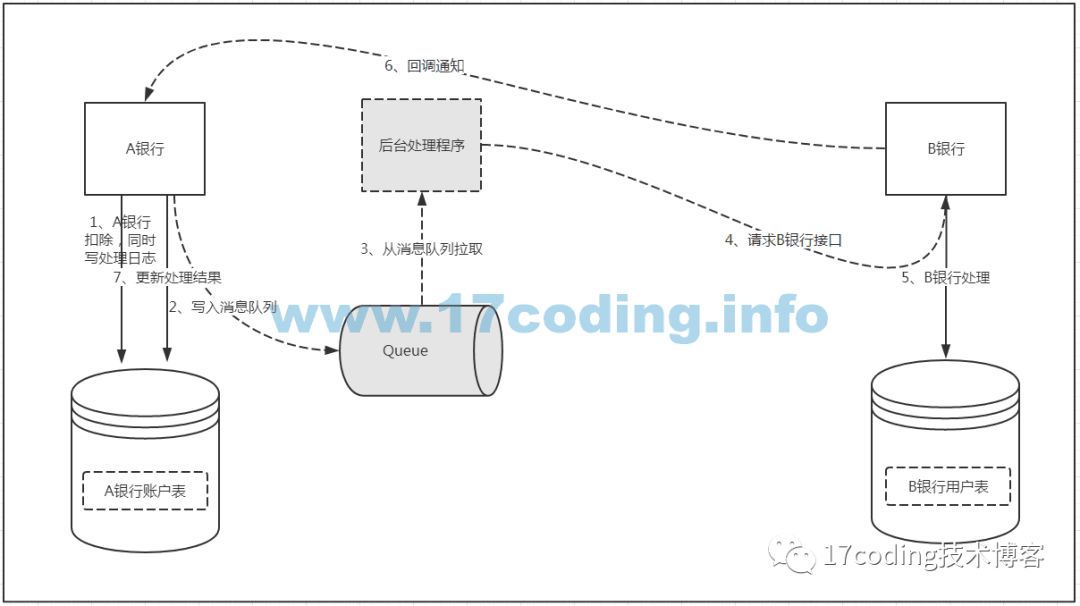
?? 通過上面的圖我們能看到,引入消息隊列后,系統的復雜性瞬間提升了,雖然彌補了我們第一種方案的幾個不足點,但也帶來了更多的問題,比如消息隊列系統本身的可用性、消息隊列的延遲等等!并且,這樣的設計依然沒有解決我們面臨的核心問題-數據的一致性!
1、如果“第1步”剛執行完,系統由于某種原因宕機了,那會導致A銀行賬戶扣款了,但是寫入消息隊列失敗,無法進行B銀行接口調用,從而導致數據不一致。
2、如果B銀行在執行“第5步”時由于校驗失敗而未能成功轉賬,在回調A銀行接口通知回滾時網絡異常或者宕機,會導致A銀行轉賬無法完成回滾,從而導致數據不一致。
?? 面對上述問題,我們不得不對系統再次進行升級改造。為了解決“A銀行賬戶扣款了,但是寫入消息隊列失敗”的問題,我們需要借助一個轉賬日志表,或者叫轉賬流水表,該表簡單的設計如下:
| 字段名稱 | 字段描述 |
|---|---|
| tId | 交易流水id |
| accountNo | 轉出賬戶卡號 |
| targetBankNo | 目標銀行編碼 |
| targetAccountNo | 目標銀行卡號 |
| amount | 交易金額 |
| status | 交易狀態(待處理、處理成功、處理失敗) |
| lastUpdateTime | 最后更新時間 |
?? 這個流水表需要怎么用呢?我們在“第1步”進行扣款時,同時往流水表寫入一條操作流水,狀態為“待處理”,并且這兩個操作必須是原子的,也就是說必須通過本地事務保證這兩個操作要么同時成功,要么同時失敗!這就保證了只要轉賬扣款成功,必定會記錄一條狀態為“待處理”的轉賬流水。如果在這一步失敗了,那自然就是轉賬失敗,沒有后續操作了。如果這步操作后系統宕機了導致沒有將消息成功寫入消息隊列(也就是“第2步”)也沒關系,因為我們的流水數據已經持久化了!這時候我們只需要加入一個后臺線程進行補償,定期的從轉賬流水表中讀取狀態為“待處理”且最后更新的時間距當前時間大于某個閾值的數據,重新放入消息隊列進行補償。這樣,就保證了消息即使丟失,也會有補償機制!B銀行在處理完轉賬請求后會回調A銀行的接口通知轉賬的狀態,從而更新A銀行流水表中的狀態字段!這樣就完美解決了上一個方案中的兩個不足點。系統設計圖如下:??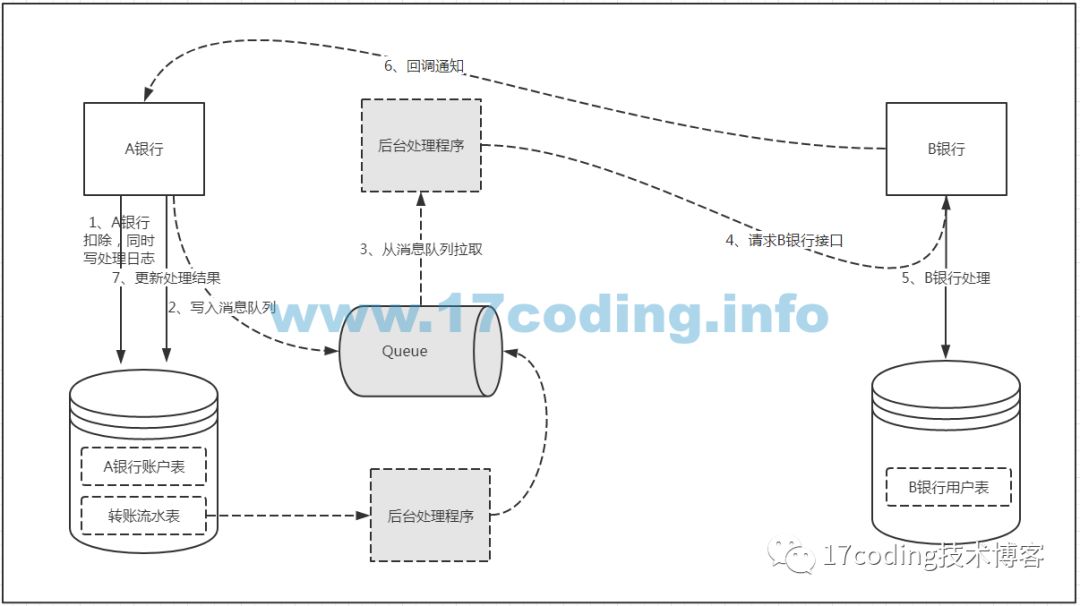
?? 到目前為止,我們很好的解決了消息丟失的問題,保證了只要A銀行轉賬操作成功,轉賬的請求就一定能發送到B銀行!但是該方案又引入了一個問題,通過后臺線程輪詢將消息放入消息隊列處理,同一次轉賬請求可能會出現多次放入消息隊列而多次消費的情況,這樣B銀行會對同一轉賬多次處理導致數據出現不一致!那怎么保證B銀行轉賬接口的冪等性呢?
?? 同樣的,我們可以在B銀行系統中需要增加一個轉賬日志表,或者叫轉賬流水表,B銀行每次接收到轉賬請求,在對賬戶進行操作的時候同時往轉賬日志表中插入一條轉賬日志記錄,同樣這兩個操作也必須是原子的!在接收到轉賬請求后,首先根據唯一轉賬流水Id在日志表中查找判斷該轉賬是否已經處理過,如果未處理過則進行處理,否則直接回調返回!最終的架構圖如下:??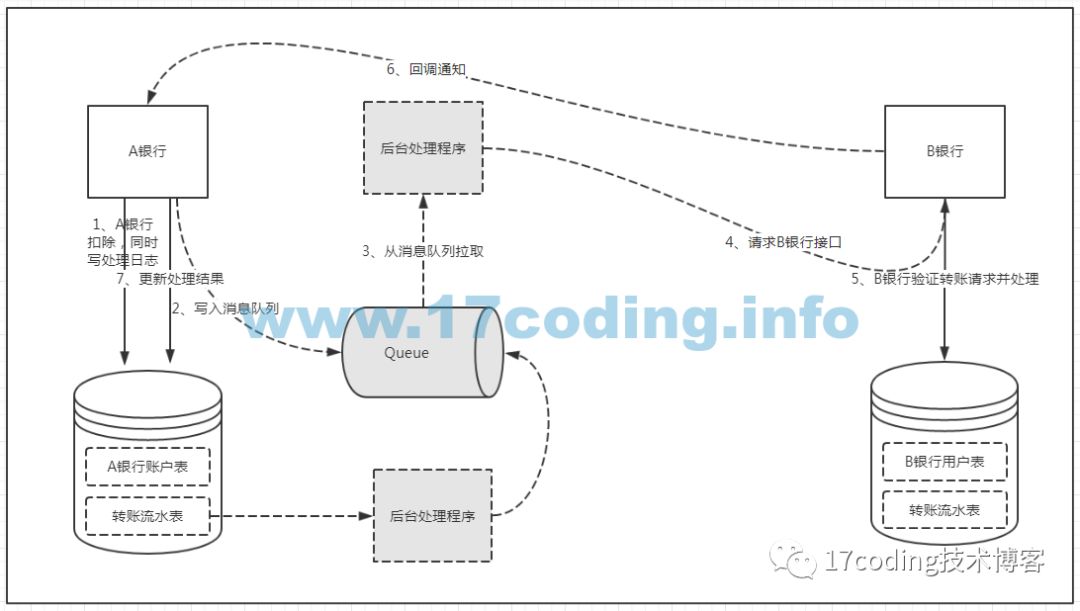
?? 所以,我們這里最核心的就是A銀行通過本地事務保證日志記錄+后臺線程輪詢保證消息不丟失。B銀行通過本地事務保證日志記錄從而保證消息不重復消費!B銀行在回調A銀行的接口時會通知處理結果,如果轉賬失敗,A銀行會根據處理結果進行回滾。
當然,分布式事務最好的解決方案是盡量避免出現分布式事務!
上述就是小編為大家分享的基于消息隊列的分布式事務解決方案是什么了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





