溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下如何使用python爬取知乎全部回答,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
這個核心代碼是直接對上篇推文中使用的代碼進行修改,刪去了對書籍名稱的提取,添加了爬取內容的寫入文件,小伙伴只要把getAnswers(問題號)里的傳入參數改成想爬取回答的問題號,剩下的事情就只需要等待了
什么是知乎問題號?

def getAnswers(qid):
offset = 0
num = 1
f = open("知乎回答%s.txt" % qid, "a")
while True:
qid = qid
print('Offset =', offset)
# 知乎api請求
data = getAnser(qid, offset)
print(data)
if len(data['data']) == 0:
break
for line in data['data']:
# 保存回答數據
content = line['content']
pattern = re.compile(r'<[^>]+>', re.S)
result = pattern.sub('', content)
print(result)
f.write("\n【第%d個回答】" % num)
num += 1
f.write(result)
offset += 20
time.sleep(1)
f.close()
getAnswers(62096167)
對于不了解爬蟲的小伙伴,只需要打開一行數據爬取知乎回答.exe,修改問題號和選擇保存路徑,就可以將該知乎問題下的所有回答保存到當前路徑下,如下圖所示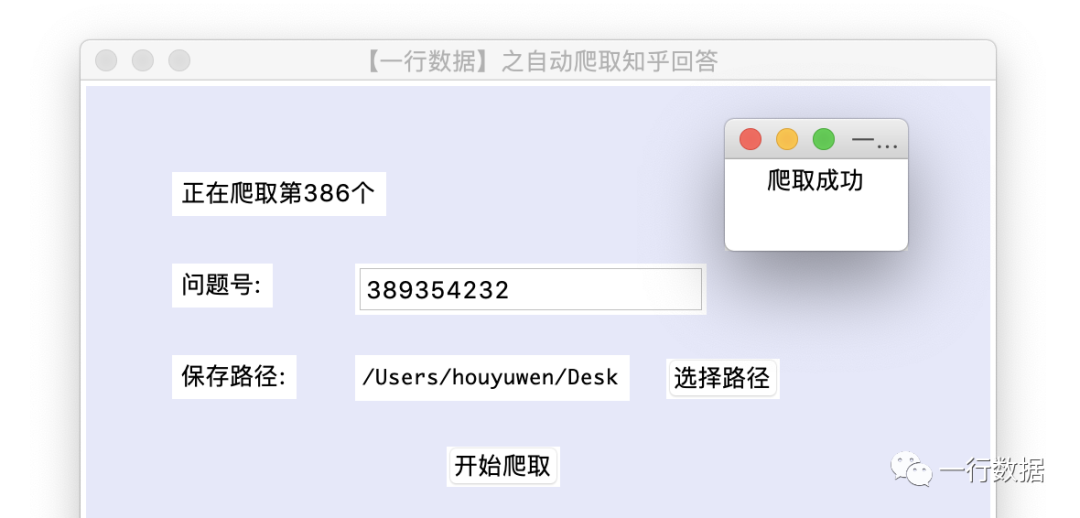
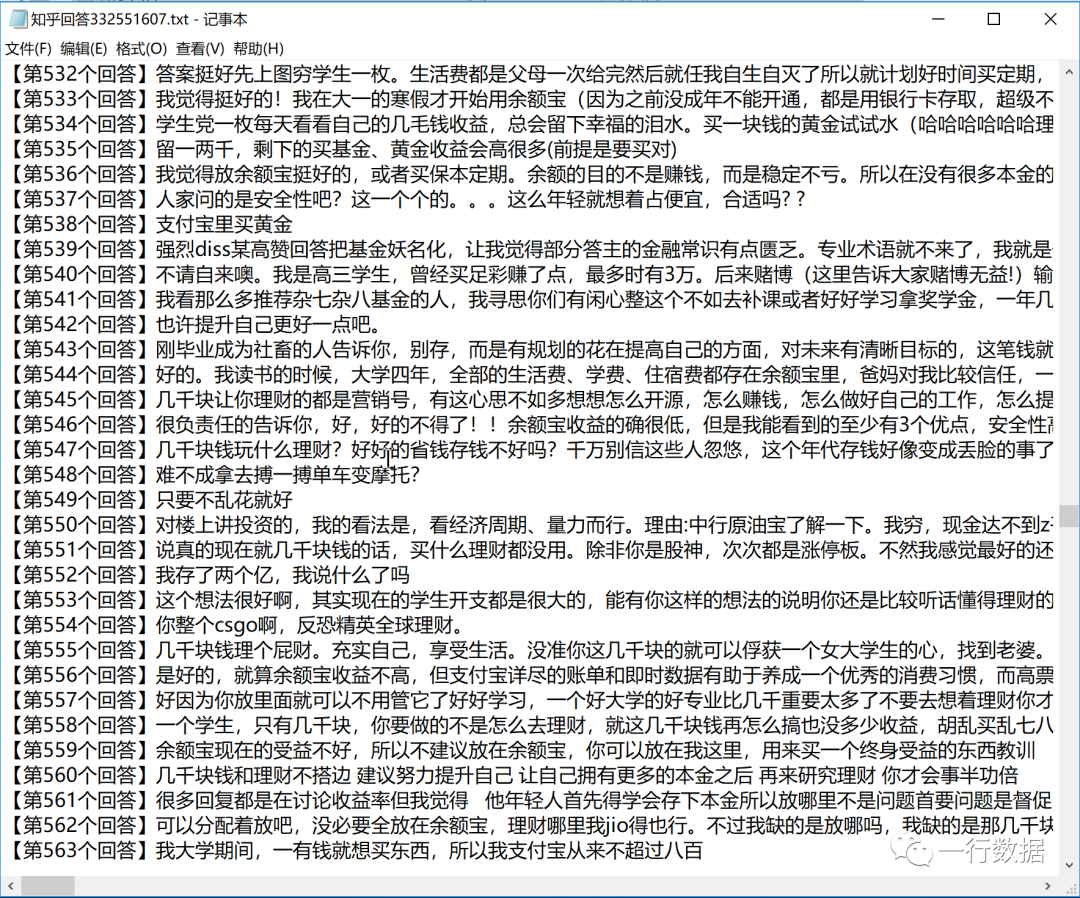
以上是“如何使用python爬取知乎全部回答”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





