溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹Spark2.x中如何用源碼剖析SortShuffleWriter具體實現,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
一、概述
這里講解Spark Shuffle Write的第三種實現SortShuffleWriter,在ShuffleWrite階段,如果不滿足UnsafeShuffleWriter、BypassMergeSortShuffleWriter兩種條件,最后代碼執行SortShuffleWriter,這里來看看他的具體實現:
二、具體實現
這里直接看Write()函數,代碼如下:
/** Write a bunch of records to this task's output */override def write(records: Iterator[Product2[K, V]]): Unit = {// 根據是否在map端進行數據合并初始化ExternalSorter//ExternalSorter初始化對應參數的含義// aggregator:在RDD shuffle時,map/reduce-side使用的aggregator// partitioner:對shuffle的輸出,使用哪種partitioner對數據做分區,比如hashPartitioner或者rangePartitioner// ordering:根據哪個key做排序// serializer:使用哪種序列化,如果沒有顯示指定,默認使用spark.serializer參數值sorter = if (dep.mapSideCombine) {require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")new ExternalSorter[K, V, C](context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)} else {// 如果沒有map-side聚合,那么創建sorter對象時候,aggregator和ordering將不傳入對應的值new ExternalSorter[K, V, V](context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)}//通過insertAll方法先寫數據到buffersorter.insertAll(records)// 構造最終的輸出文件實例,其中文件名為(reduceId為0):// "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId;val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)//在輸出文件名后加上uuid用于標識文件正在寫入,結束后重命名val tmp = Utils.tempFileWith(output)try {val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)//將排序后的record寫入輸出文件val partitionLengths = sorter.writePartitionedFile(blockId, tmp)//生成index文件,也就是每個reduce通過該index文件得知它哪些是屬于它的數據shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)//構造MapStatus返回結果,里面含有ShuffleWriter輸出結果的位置信息mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)} finally {if (tmp.exists() && !tmp.delete()) {logError(s"Error while deleting temp file ${tmp.getAbsolutePath}")}}}
其中ExternalSorter是SortShuffleWriter一個排序類,這個類用于對一些(K, V)類型的key-value對進行排序,如果需要就進行merge,生的結果是一些(K, C)類型的key-combiner對。combiner就是對同樣key的value進行合并的結果。它首先使用一個Partitioner來把key分到不同的partition,然后,如果有必要的話,就把每個partition內部的key按照一個特定的Comparator來進行排序。它可以輸出只一個分區了的文件,其中不同的partition位于這個文件的不同區域(在字節層面上每個分區是連續的),這樣就適用于shuffle時對數據的抓取。
2.這里接著看上面代碼第14行的 sorter.insertAll(records)函數,里面其實干了很多事情,代碼如下:
def insertAll(records: Iterator[Product2[K, V]]): Unit = { //這里獲取Map是否聚合標識 val shouldCombine = aggregator.isDefined //根據是否進行Map端聚合,來決定使用map還是buffer, // 如果需要通過key做map-side聚合,則使用PartitionedAppendOnlyMap; // 如果不需要,則使用PartitionedPairBuffer if (shouldCombine) { // 使用AppendOnlyMap優先在內存中進行combine // 獲取aggregator的mergeValue函數,用于merge新的值到聚合記錄 val mergeValue = aggregator.get.mergeValue // 獲取aggregator的createCombiner函數,用于創建聚合的初始值 val createCombiner = aggregator.get.createCombiner var kv: Product2[K, V] = null val update = (hadValue: Boolean, oldValue: C) => { //創建update函數,如果有值進行mergeValue,如果沒有則createCombiner if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2) } while (records.hasNext) { addElementsRead() kv = records.next() ////通過key計算partition ID,通過partition ID對數據進行排序 //這里的partitionID其實就是Reduce個數 // 對key計算分區,然后開始進行merge map.changeValue((getPartition(kv._1), kv._1), update) // 如果需要溢寫內存數據到磁盤 maybeSpillCollection(usingMap = true) } } else { // Stick values into our buffer while (records.hasNext) { addElementsRead() val kv = records.next() //通過key計算partition ID,通過partition ID對數據進行排序 //這里的partitionID其實就是Reduce個數 buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C]) // 當buffer達到內存限制時(buffer默認大小32k,由spark.shuffle.file.buffer參數決定),會將buffer中的數據spill到文件中 maybeSpillCollection(usingMap = false) } } }
3.下面繼續跟蹤maybeSpillCollection()函數,如何對內存數據溢寫的,代碼如下:
private def maybeSpillCollection(usingMap: Boolean): Unit = { var estimatedSize = 0L // 如果是map ,也就是Map端需要聚合的情況 if (usingMap) { //這里預估一個值,根據預估值判斷是否需要溢寫, // 如果需要,溢寫完成后重新初始化一個map estimatedSize = map.estimateSize() if (maybeSpill(map, estimatedSize)) { map = new PartitionedAppendOnlyMap[K, C] } // 這里執行的map不需要聚合的情況 } else { //這里預估一個值,根據預估值判斷是否需要溢寫, // 如果需要,溢寫完成后重新初始化一個buffer estimatedSize = buffer.estimateSize() if (maybeSpill(buffer, estimatedSize)) { buffer = new PartitionedPairBuffer[K, C] } } if (estimatedSize > _peakMemoryUsedBytes) { _peakMemoryUsedBytes = estimatedSize } }
4.上面涉及到溢寫判斷函數maybeSpill,我們看下他是如何進行判斷的,代碼如下:
// maybeSpill函數判斷大體分了三步// 1.為當前線程嘗試獲取amountToRequest大小的內存(amountToRequest = 2 * currentMemory - myMemoryThreshold)。// 2.如果獲得的內存依然不足(myMemoryThreshold <= currentMemory),則調用spill,執行溢出操作。內存不足可能是申請到的內存為0或者已經申請得到的內存大小超過了myMemoryThreshold。// 3.溢出后續處理,如elementsRead歸零,已溢出內存字節數(memoryBytesSpilled)增加線程當前內存大小(currentMemory),釋放當前線程占用的內存。 protected def maybeSpill(collection: C, currentMemory: Long): Boolean = { var shouldSpill = false //其中內存閾值myMemoryThreshold 由參數spark.shuffle.spill.initialMemoryThreshold控制,默認是5M if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) { // Claim up to double our current memory from the shuffle memory pool val amountToRequest = 2 * currentMemory - myMemoryThreshold //底層調用TaskMemoryManager的acquireExecutionMemory方法分配內存 val granted = acquireMemory(amountToRequest) // 更新現在內存閥值 myMemoryThreshold += granted //再次判斷當前內存是否大于閥值,如果還是大于閥值則spill shouldSpill = currentMemory >= myMemoryThreshold } shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold // Actually spill if (shouldSpill) { _spillCount += 1 logSpillage(currentMemory) //進行spill,這了溢寫肯定先寫到緩沖區,后寫到磁盤, //有個比較重要的參數spark.shuffle.file.buffer 默認32k, 優化時常進行調整 spill(collection) _elementsRead = 0 _memoryBytesSpilled += currentMemory releaseMemory() } shouldSpill }
里面還有更深層次的代碼,這里就不再跟蹤了,只要是了解了整個大體思路即可,有興趣的自己去跟蹤看下即可。
為方便大家理解,下面給大家畫了下SorteShuffleWriter執行的流程圖,BypassMergeSortShuffleWriter和UnsafeShuffleWriter的處理流程與這個流程基本一致,只是具體的實現稍有差異,水平有限,僅供參考:
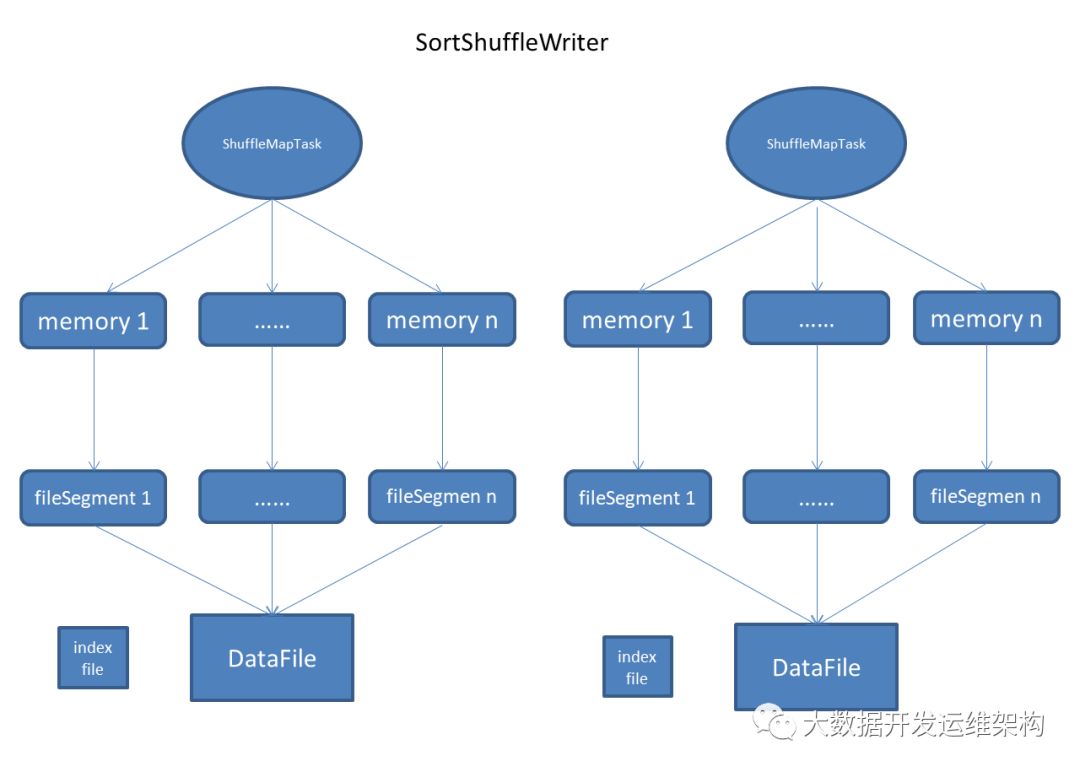
關于Spark2.x中如何用源碼剖析SortShuffleWriter具體實現就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





