溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Kafka Stream是什么意思,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
首先,KafkaStream相比于主流的Storm、SparkStreaming、Flink等,優勢在于輕量級,不要要特別指定容器資源等。非常適合一些輕量級的ETL場景,比如在常用的ETL中,大部分輕量級的Filter、LookUp、WriteStorage等操作可以使用KafkaStreams進行。理想的架構是,KafkaStream這樣的輕量級計算框架+Lamdba,就能做到安全按需使用的流計算模式。
Kafka Streams構建在Kafka上,建立在流處理的一系列重要功能基礎之上,比如正確區分事件事件和處理時間,處理遲到數據以及高效的應用程序狀態管理。
功能強大
高拓展性,彈性,容錯
有狀態和無狀態處理
基于事件時間的Window,Join,Aggergations
輕量級
無需專門的集群
沒有外部依賴
一個庫,而不是框架
完全集成
100%的Kafka 版本兼容
易于集成到現有的應用程序
程序部署無需手工處理(這個指的應該是Kafka多分區機制對Kafka Streams多實例的自動匹配)
實時性
毫秒級延遲
并非微批處理
窗口允許亂序數據
允許遲到數據
更簡單的流處理:Kafka Streams的設計目標為一個輕量級的庫,就像Kafka的Producer和Consumer似得。可以輕松將Kafka Streams整合到自己的應用程序中。對應用程序的額外要求僅僅是打包和部署到應用程序所在集群罷了。
除了Apache Kafka之外沒有任何其它外部依賴, 并且可以在任何Java應用程序中使用。不需要為流處理需求額外部署一個其它集群。
使用Kafka作為內部消息通訊存儲介質,不需要重新加入其它外部組件來做消息通訊。Kafka Streams使用Kafka的分區水平拓展來對數據做有序高效的處理。這樣同時兼顧了高性能,高擴展性,并使操作簡便。不必了解和調整兩個不同的消息傳輸層(數據在不同伸縮介質中間移動和流處理的獨立消息處理層),同樣,Kafka的性能和高可靠性方面的改進,都會使得Kafka Streams直接受益。
Kafka Streams能夠更加無縫的集成到現有的開發、打包、部署和業務實踐當中去。你可以自由地使用自己喜歡的工具,比如java 應用服務器,Puppet, Ansible,Mesos,Yarn,Docket, 甚至在一臺手工運行你自己應用程序進行驗證的機器上。
支持本地狀態容錯。這樣就可以進行非常高效快速的包含狀態的Join和Window 聚合操作。本地狀態被保存在Kafka中,在機器故障的時候,其他機器可以自動恢復這些狀態繼續處理。
每次處理一條數據以實現低延時,這也是Kafka Streams和其他基于微批處理的流處理框架的不同。另外,KafkaStreams的API與Spark中的非常相似,有非常多相同意義的算子,但是目前版本對于scala支持還是有些問題,不過對于擅長Spark編程的人員來說,寫一個Kafka流處理不需要額外進行太多的學習。
Stream是KafkaStream中最重要的概念,代表大小沒有限制且不斷更新的數據集,一個Stream是一個有序的,允許重復的不可變的數據集,被定義為一個容錯的鍵值對。
一個流處理程序可以是任何繼承了KafkaSteams庫的程序,在實際使用中,也就是我們寫的Java代碼。
處理拓撲定義了由流處理應用程序進行數據處理的計算邏輯,一般情況下,我們可以通過 StreamsBuilder builder = new StreamsBuilder();StrinmBuilder會在類內部為我們創建一個處理拓撲,如果需要自定義處理拓撲,可以通過Low-level API或者通過Kafka Streams的DSL來構建拓撲。
流處理器用來處理拓撲中的各個節點,代表拓撲中的每個處理步驟,用來完成數據轉換功能。一個流處理同一時間從上游接收一條輸入數據,產生一個或多個輸出記錄到下個流處理器。Kafka有兩種方法定義流處理器:
DSL API,也就是map,filter等算子。
Low-Level API,低級API,允許開發人員定義和連接處理器的狀態存儲器進行交換。
一些比如窗口函數的算子就是基于時間界限定義的。
事件時間:時間或者記錄產生的時間,也就是時間在源頭最初創建的時間
處理時間:流處理應用程序開始處理時間的時間點,即時間進入流處理系統的時間
攝取時間:數據記錄由KafkaBroker保存到kafka topic對應分區的時間點,類似于時間時間,都是嵌入數據記錄中的時間戳字段,不過攝取時間是KafkaBroker附加在目標Topic上的.
事件時間和攝取時間的選擇是通過在Kafka(不是KafkaStreams)上進行配置實現的。從Kafka 0.10.X起,時間戳會被自動嵌入到Kafka的Message中,可以根據配置選擇事件時間或者攝取時間。配置可以在broker或者topic中指定。Kafka Streams默認提供的時間抽取器會將這些嵌入的時間戳恢復原樣。因此,應用程序的有效時間語義上依賴于這種嵌入時時間戳讀取的配置。請參考:Developer Guide
如果每個消息處理都是彼此獨立的,那么其就不需要狀態,比如只需要進行消息轉換,或者是篩選,那么流處理的拓撲也非常簡單。如果能夠保存狀態,流處理可以應用在更多場景,可以進行Join、Group By或者Aggregate擦左,KafkaStreams DSL提供了很多這樣的包含狀態的DSL。
首先,流和表具有雙重性,一位著一個流可以作為表,表也可以作為流。Kafka的Log compact功能就是利用了這種雙重性。Kafka日志壓縮的影響, 考慮KStream和KTable的另一種形式,如果一個KTable存儲到Kafka的topic中,你就需要啟用Kafka的日志壓縮功能以節省空間。然而,這種方式在KStream的情況下是不安全的,因為,一旦開啟日志壓縮,Kafka就會刪除比較舊的Key值,這樣就會破壞數據的語義。以數據重放為例,你會突然得到一個值為3的alice,而不是4,因為以前的記錄都被日志壓縮功能刪除了。因此,日志壓縮在KTable中使用是安全的,但是在KStream中使用是錯誤的
表的簡單形式就是一個KV對的集合。
Stream as table:流可以被認為是一張表,可以通過重建日志的方式變成一張真正的表。
Table as Stream:一個表可以被認為是流上一個時間點的快照,每行記錄都代表該鍵的最新值。可以通過遍歷表中的每個KV很容易形成一個真正的流。
只有KafkaStreams的DSL才有KSteam的概念。一個KSteam是一個事件流,每條時間記錄代表了無限的包含數據的數據集的抽象,用表來解釋流的概念,數據的記錄始終被解釋為Insert,只有追加,因為沒有辦法替換當前已經存在的相同的key的行數據。
只有KafkaSteams的DSL才有KTable的概念。一個KTable是一個changelog的更新日志流。每個數據記錄代表一個更新的抽象。每個條記錄都是該Key最后一個值的更新結果。KTable提供了通過key查找數據值的功能,該功能可以用在Join等功能上。
Join可以實現在Key上對應兩個流的記錄和并,產生新流。一個基于流上的Join通常是基于窗口的,否則所有數據都會被保存,記錄就回無限增長。KafkaStreamsDSL支持不同的Join,比如KSteam之間的Join以及KStream和KTable之間的Join。
####(11)Aggregations 聚合操作,比如sum、count,需要一個輸入流,并且以多個輸入記錄為單位組成單個記錄并產生新流。流上的聚合必須基于敞口進行,負責數據和join一樣會無限制增長。聚合輸入可以是KStream或者KTable,但輸出一定是KTable,使得KafkaStreams的輸出結果會不斷被更新,當數據亂序到達之后,數據也可以被即使更新,因為輸出的是KTable,數據會被及時覆蓋。
首先放一張架構圖:
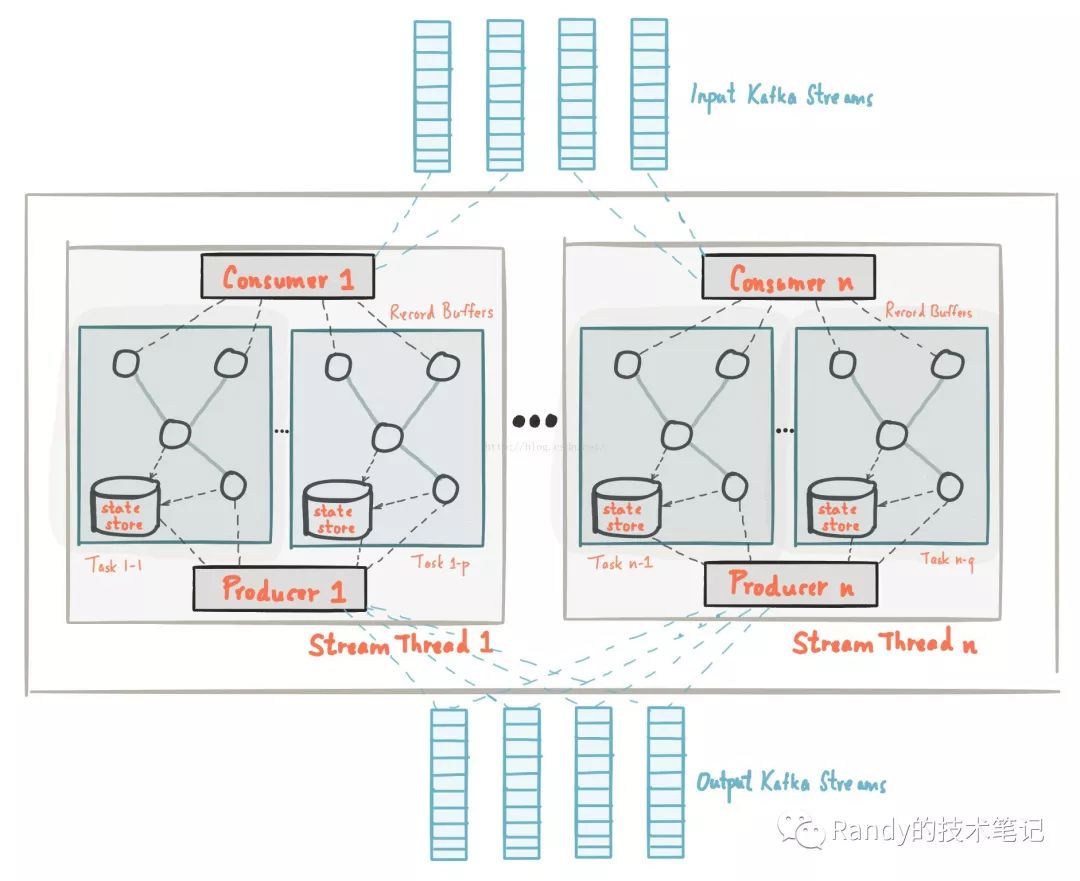
一個拓撲算子或者說簡單拓撲定義了流處理應用的計算邏輯,也就是輸入數據是如何轉為輸出數據的。一個拓撲算子是包含了用戶流處理代碼的邏輯抽象。在運行時,邏輯拓撲被實例化和復制在應用程序中并行執行。
每個Stream分區是kafka的一個分區中完整有序的數據記錄;一個Stream數據記錄映射中的數據記錄直接來自于Kafka topic 數據的key值是Kafak和KafkaStreams的關鍵,決定了數據是如何被路由到特定分區的。在流任務執行的過程中,輸入流的分區數決定了Task的數量,每個Task負責該分區的數據處理,kafkaStreams為每個分配到的分區分配了對應的緩沖區,基于緩沖區提供一次處理一條消息的時間處理機制。需要注意的是,KafkaStreams不是一個資源管理器,而是一個庫,可以運行在任何流處理應用程序中,應用程序的多個實例可以運行在相同的機器或者是被資源管理器分發到不同的節點上運行;分配給該Task的分區永遠不會改變,如果一個示例故障了,任務會被重新分配并在其他實例上啟動,并從相同分區繼續消費數據。
開發人員可以配置每個應用程序中的并行處理的線程數,每個線程與他們的拓撲算子獨立執行一個或者多個任務。比如一個線程中可以執行2個Task,這兩個Task對應Topic1的兩個分區,也可以同時處理Topic2的兩個分區,但是同一個Topic的不同分區必須使用不同的Task進行處理。
Kafka提供的狀態存儲,可以在流處理應用程序中保存和查詢數據。每個Task都內置了一個或多個狀態存儲空間,可以通過API來保存或查詢。這些狀態存儲空間是RocksDB數據庫,一個基于內存的HashMap或者其他更方便的數據結構。并且kafkaStreams基于本地狀態提供了容錯和自動恢復能力。
因為Kafka本身分區就是高可用可復制的,所以當流保存到Kafka的時候也是高可用的,即使流處理失敗了也沒有關系,KafkaStreams會在其他實例中重啟對應Task,利用了KafkaConsumer的失敗處理功能。而本地數據存儲可靠性依賴于更新日志,為每個狀態Kafkatopic保存一個可復制的changelog。changelog在本地存儲使用分區劃分,每個task都有自己的專用分區,如果一個task失敗了,kafka將會在其他實例上重啟并使用該topic上的changelog來更新task 的最新狀態。changelog的topic如果開啟kafka的日志壓縮永能,九數據就會被安全清除,放置changelog無限增長。
Kafka實現了至少一次的消息處理機制,即使發生鼓掌也不會有數據丟失和沒有處理,但是部分數據可能被處理多次。但是有一些非冪等操作,比如計數,在at-least-once可能會出現計算結果錯誤,KafkaStreams將在以后的版本中支持exactly-once的語義處理。
KafkaStreams通過同步調節所有輸入流的消息記錄上呃時間戳來進行流控,KafkaStreams默認提供了event-time的處理語義。
關于“Kafka Stream是什么意思”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





