溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
不使用selenium插件如何抓取網頁的動態加載數據,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
下面講的是不使用selenium插件模擬瀏覽器,如何獲得網頁上的動態加載數據。
步驟如下:
一、找到正確的URL。
二、填寫URL對應的參數。
三、參數轉化為urllib可識別的字符串data。
四、初始化Request對象。
五、urlopen這個Request對象,獲得數據。
url='http://www.*****.*****/*********'formdata = {'year': year,'month': month,'day': day}data = urllib.urlencode(formdata)request=urllib2.Request(url,data = data) #如果URL不帶參數就是request=urllib2.Request(url)r = urllib2.urlopen(request)html=r.read() # html就是你要的數據,可能是html格式,也可能是json,或去他格式
后面步驟都是相同的,關鍵在于如何獲得URL和參數。我們以新冠肺炎的疫情統計網頁為例(https://news.qq.com/zt2020/page/feiyan.htm#/)。
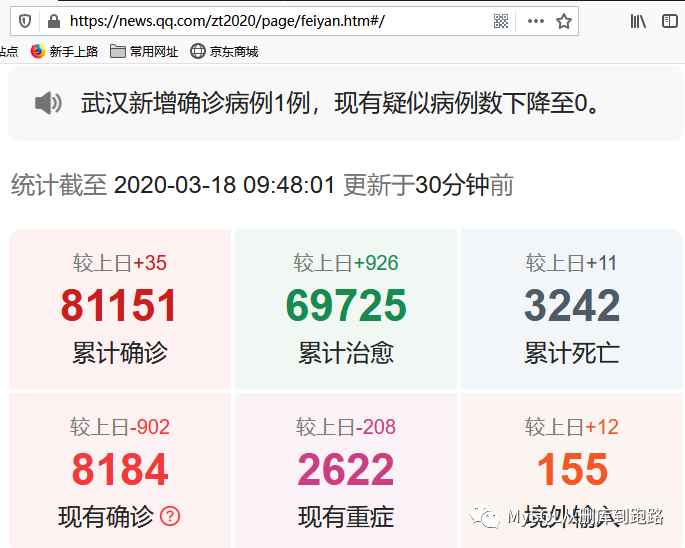
如果直接抓瀏覽器的網址,你會看見一個沒有數據內容的html,里面只有標題、欄目名稱之類的,沒有累計確診、累計死亡等等的數據。因為這個頁面的數據是動態加載上去的,不是靜態的html頁面。需要按照我上面寫的步驟來獲取數據,關鍵是獲得URL和對應參數formdata。下面以火狐瀏覽器講講如何獲得這兩個數據。
肺炎頁面右鍵,出現的菜單選擇檢查元素。
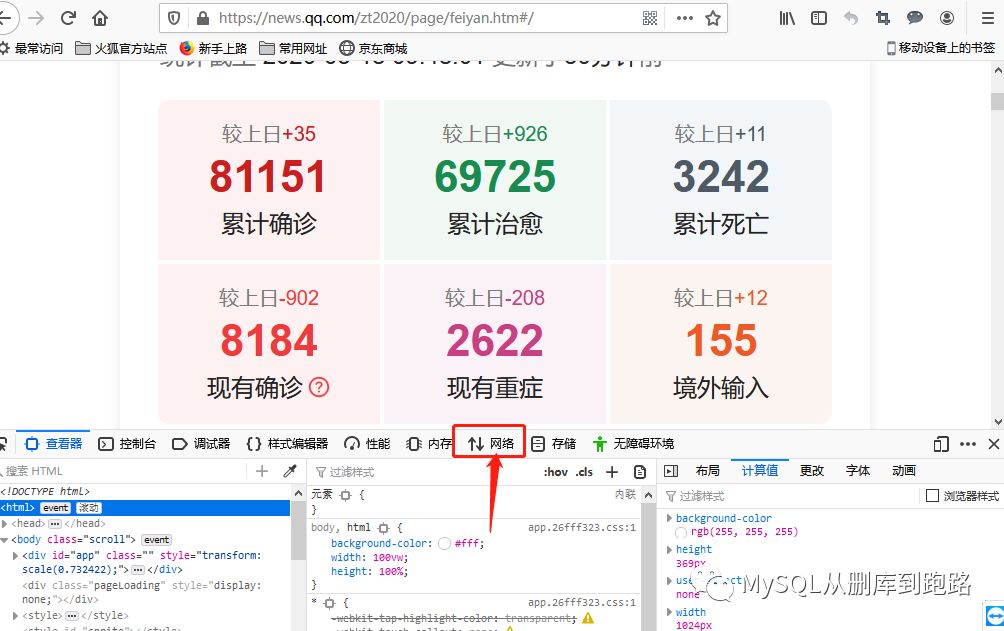
點擊上圖紅色箭頭網絡選項,然后刷新頁面。如下,
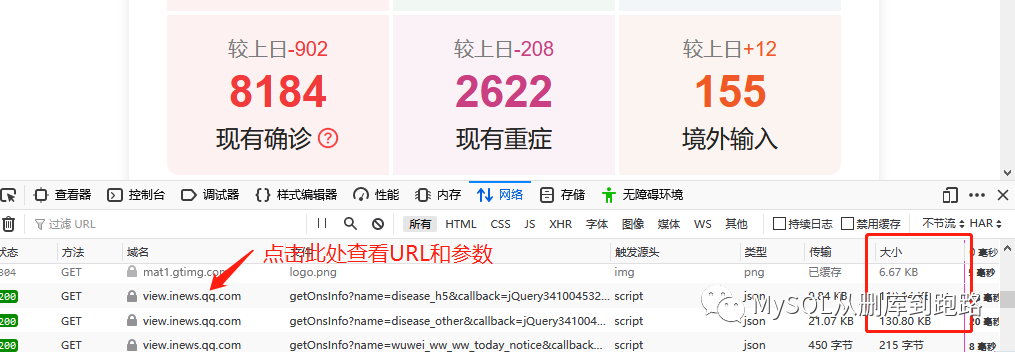
這里會出現很多網絡傳輸記錄,觀察最右側紅框“大小”那列,這列表示這個http請求傳輸的數據量大小,動態加載的數據一般數據量會比其它頁面元素的傳輸大,119kb相比其它按字節計算的算是很大的數據了,當然網頁的裝飾圖片有的也很大,這個需要按照文件類型那列來甄別。
然后點擊域名列對應那行,如下

可以在消息頭中看見請求網址,這個就是url,點擊參數可以看見url對應的參數
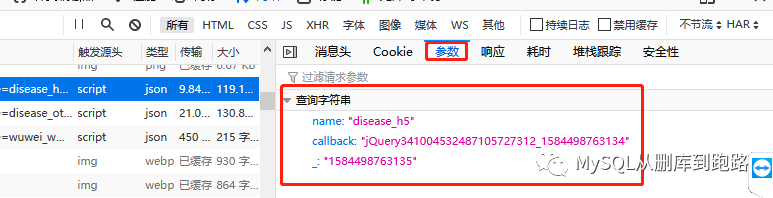
https://view.inews.qq.com/g2/getOnsInfo?name=disease_h6&callback=jQuery341004532487105727312_1584498763134&_=1584498763135
可以看到url的尾部?后面已經把參數寫上了。
我們如果使用帶參數的URL,那么就
request=urllib2.Request(url),不加data參數。
如果使用request=urllib2.Request(url,data = data)
那么url="https://view.inews.qq.com/g2/getOnsInfo"
formdata = {'name': 'disease_h6',
'callback': '',
'_': 當前時間戳
}
name是disease_h6,callback是頁面回調函數,我們不需要有回調動作,所以設置為空,_對應的是時間戳(Python很容易獲得時間戳的),因為查詢肺炎患者數量和時間是緊密相關的。
如果都寫在一個url中是下面形式的
url='https://view.inews.qq.com/g2/getOnsInfo?name=disease_h6&callback=&_=%d'%int(stamp*1000)
按照這個思路就可以獲得疫情數據了。兩種方案任你選擇。
找url和參數是一項需要耐心,需要一定的分析能力的,才能正確甄別url和參數的含義,進行正確的編程實現。參數是否可以空,是否可以硬編碼寫死,是否有特殊要求,其實是一個很考驗經驗的事情。
有的url很簡單,返回一個.dat文件,里面直接就是json格式的數據,這種是最友好的了。有的需要你設置大量參數,才能獲得,而且獲得的是html格式的,需要解析才能提取數據。
關于不使用selenium插件如何抓取網頁的動態加載數據問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





