溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
R語言jiebaR包文本中文分詞及詞云制作的示例分析,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
微信出現之前,qq群是我和讀者交流的主要陣地,一般我會問大家為什么入群這樣一個問題,收集到一些有趣的回答,今天就以這組文本數據練習中文分詞和詞云圖的制作。

首先我們先從excel讀取數據
data <- read.xlsx("why.xlsx")data <- data[,1]準備jiebaR包和分詞引擎
library(jiebaR)engine <- worker()
開始分詞
fc <- segment(data,engine)

我們會發現分詞質量不高,有些詞語要剔除。
準備停止詞stopwords.txt
t <- readLines('stopwords.txt')stopwords<-c(NULL)for(i in 1:length(t)){stopwords[i]<-t[i]}開始過濾
fc2 <- filter_segment(fc,stopwords)
過濾之后,我們發現此時的關鍵詞更加凸顯。

統計詞頻
freq <- sort(table(fc2),decreasing = T)
簡單畫個餅圖看看效果咋樣吧
pie(head(freq))
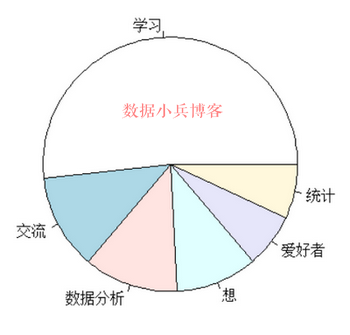
聯想造句:愛好者想學習和交流數據分析和統計(這個意思非常符合入qq群目標)。
把關鍵詞和詞頻轉換為數據框結構
mydata=data.frame(word=names(freq),freq=as.vector(freq),stringsAsFactors= F)
制作一個詞云圖吧
library(wordcloud2)wordcloud2(mydata,size = 1.5)
這就是最終效果了,簡單總結一下:入群最主要的目的是“學習”“數據分析”以及“統計”了,ta們都有誰內?有“愛好者”、“新手”、“研究生”,不管是“交流”,或是“請教”“咨詢”,總是是要“謝謝”“數據小兵”(純屬娛樂造句)。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





