溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Pandas如何實現groupby分組的apply轉換”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!

這里的split指的是pandas的groupby,我們自己實現apply函數,apply返回的結果由pandas進行combine得到結果
function的第一個參數是dataframe
function的返回結果,可是dataframe、series、單個值,甚至和輸入dataframe完全沒關系
怎樣對數值列按分組的歸一化?
怎樣取每個分組的TOPN數據?
將不同范圍的數值列進行歸一化,映射到[0,1]區間:
更容易做數據橫向對比,比如價格字段是幾百到幾千,增幅字段是0到100
機器學習模型學的更快性能更好
歸一化的公式:

每個用戶的評分不同,有的樂觀派評分高,有的悲觀派評分低,按用戶做歸一化
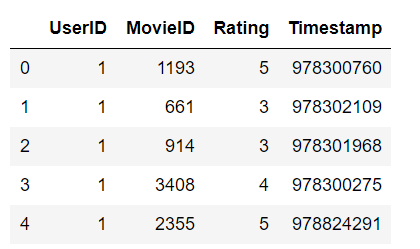
import pandas as pd
ratings = pd.read_csv(
"./datas/movielens-1m/ratings.dat",
sep="::",
engine='python',
names="UserID::MovieID::Rating::Timestamp".split("::")
)
ratings.head()
# 實現按照用戶ID分組,然后對其中一列歸一化
def ratings_norm(df):
"""
@param df:每個用戶分組的dataframe
"""
min_value = df["Rating"].min()
max_value = df["Rating"].max()
df["Rating_norm"] = df["Rating"].apply(
lambda x: (x-min_value)/(max_value-min_value))
return df
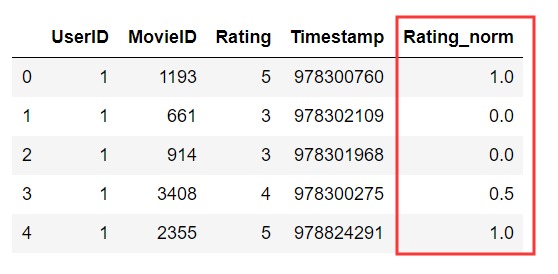
ratings = ratings.groupby("UserID").apply(ratings_norm)
ratings[ratings["UserID"]==1].head()
可以看到UserID==1這個用戶,Rating==3是他的最低分,是個樂觀派,我們歸一化到0分;
獲取2018年每個月溫度最高的2天數據
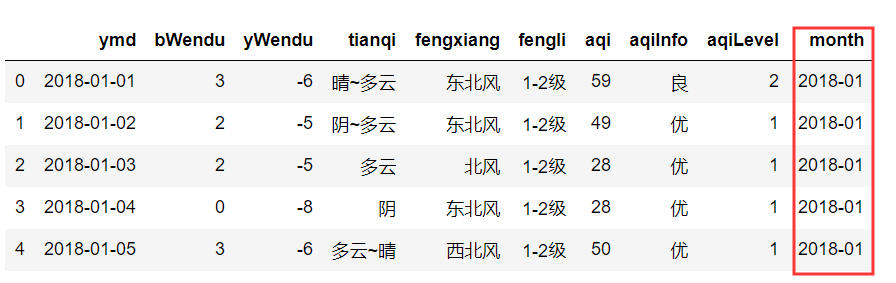
fpath = "./datas/beijing_tianqi/beijing_tianqi_2018.csv"
df = pd.read_csv(fpath)
# 替換掉溫度的后綴℃
df.loc[:, "bWendu"] = df["bWendu"].str.replace("℃", "").astype('int32')
df.loc[:, "yWendu"] = df["yWendu"].str.replace("℃", "").astype('int32')
# 新增一列為月份
df['month'] = df['ymd'].str[:7]
df.head()
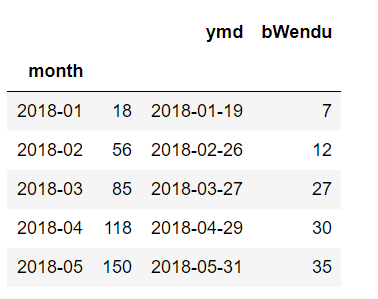
def getWenduTopN(df, topn):
"""
這里的df,是每個月份分組group的df
"""
return df.sort_values(by="bWendu")[["ymd", "bWendu"]][-topn:]
df.groupby("month").apply(getWenduTopN, topn=1).head()
我們看到,grouby的apply函數返回的dataframe,其實和原來的dataframe其實可以完全不一樣
“Pandas如何實現groupby分組的apply轉換”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。