溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
溫馨提示:要看高清無碼套圖,請使用手機打開并單擊圖片放大查看。
1.問題描述
CDH中默認不支持Lzo壓縮編碼,需要下載額外的Parcel包,才能讓Hadoop相關組件如HDFS,Hive,Spark支持Lzo編碼。
具體請參考:
https://www.cloudera.com/documentation/enterprise/latest/topics/cm\_mc\_gpl\_extras.html
https://www.cloudera.com/documentation/enterprise/latest/topics/cm\_ig\_install\_gpl\_extras.html#xd\_583c10bfdbd326ba-3ca24a24-13d80143249--7ec6
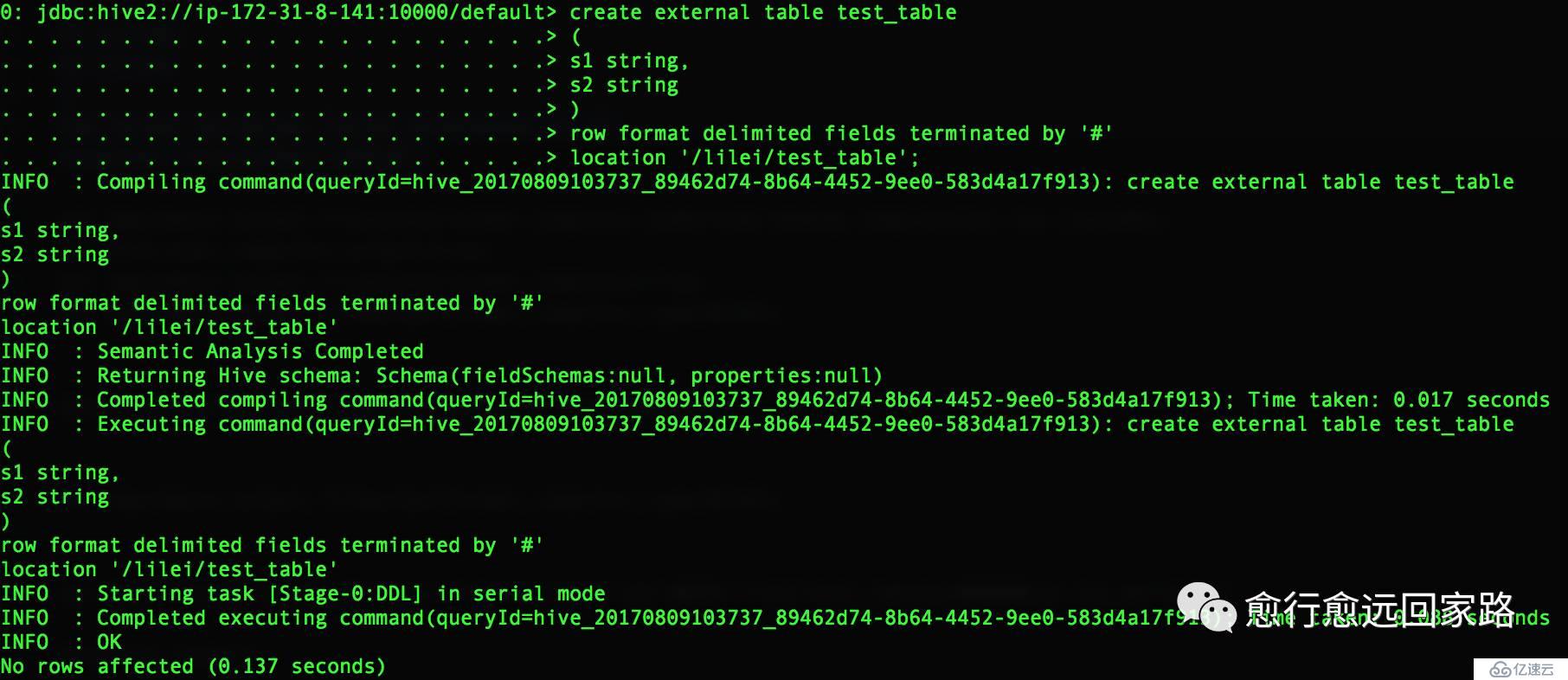
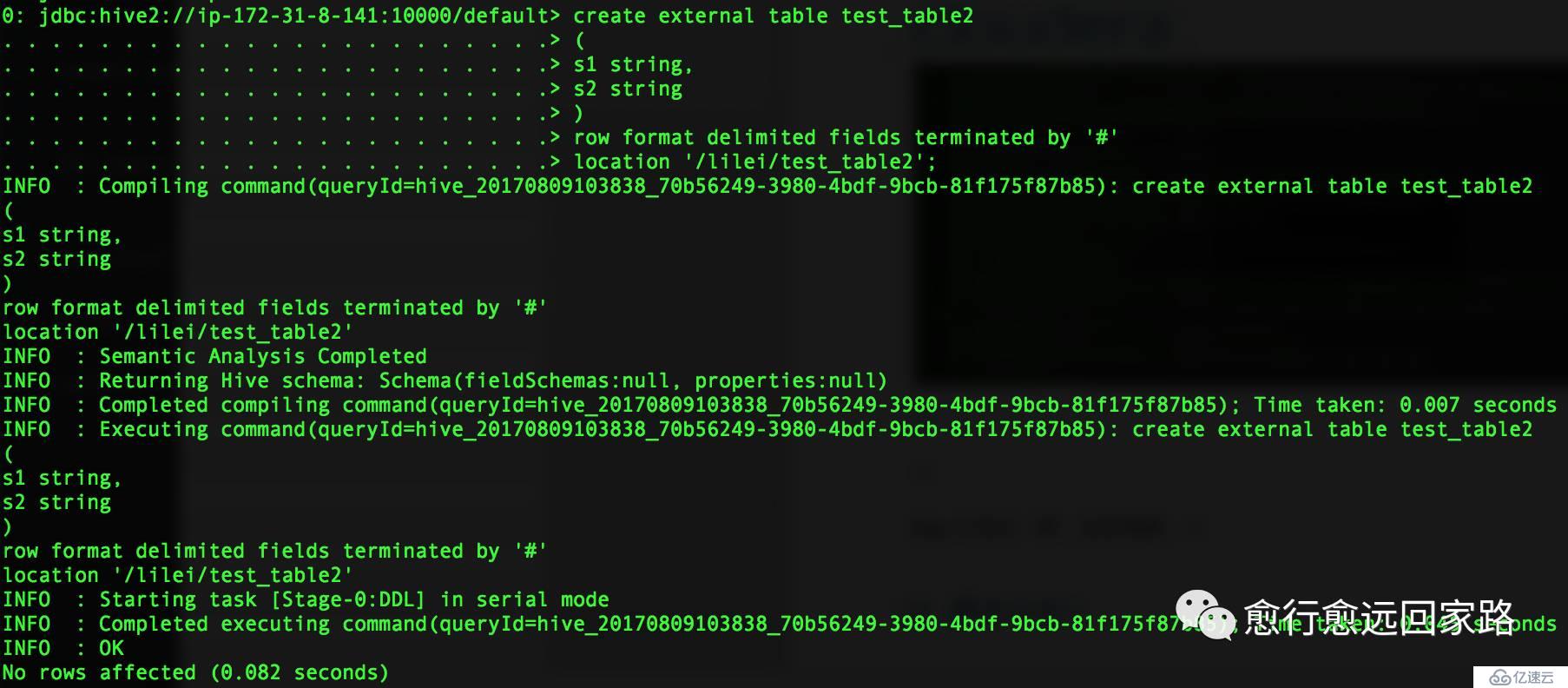
首先我在沒做額外配置的情況下,生成Lzo文件并讀取。我們在Hive中創建兩張表,test_table和test_table2,test_table是文本文件的表,test_table2是Lzo壓縮編碼的表。如下:
| create external table test_table(s1 string,s2 string)row format delimited fields terminated by '#'location '/lilei/test_table'; insert into test_table values('1','a'),('2','b'); create external table test_table2(s1 string,s2 string)row format delimited fields terminated by '#'location '/lilei/test_table2'; |
|---|
通過beeline訪問Hive并執行上面命令:
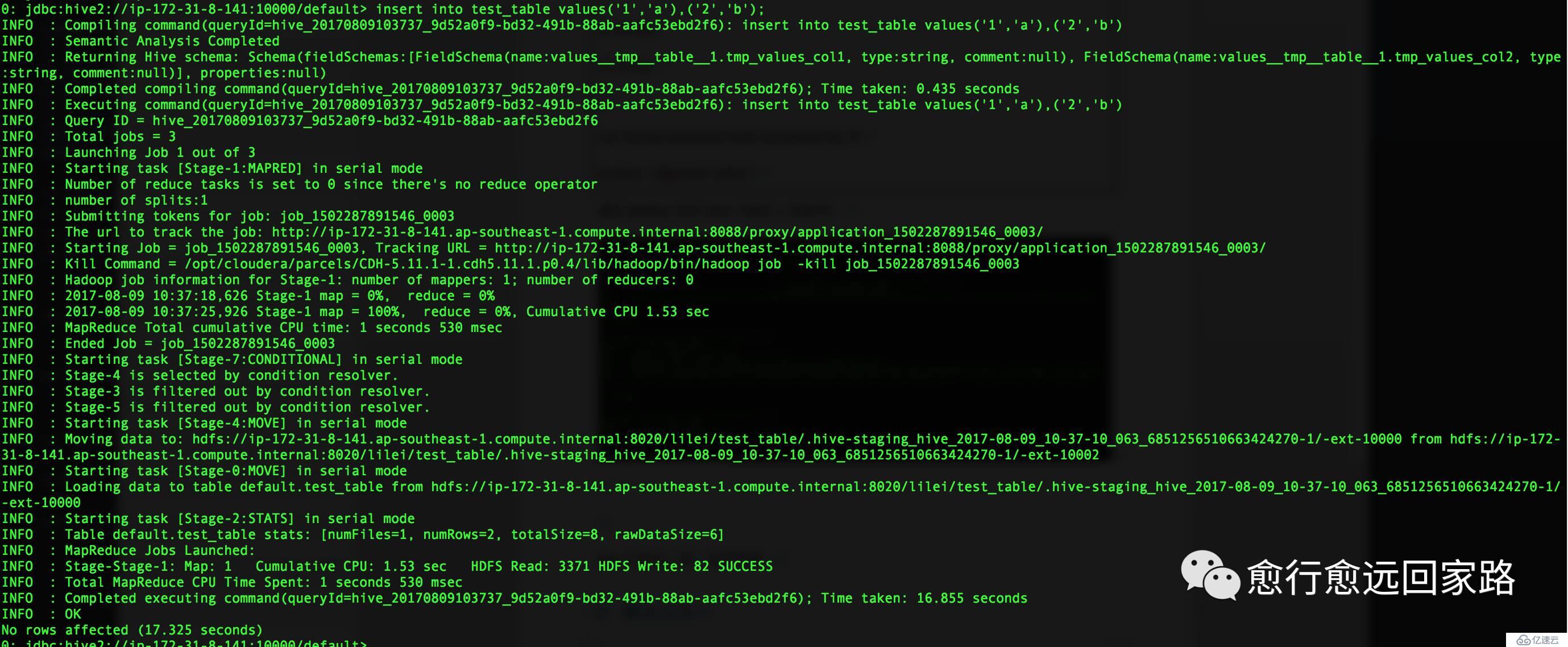
查詢test_table中的數據:

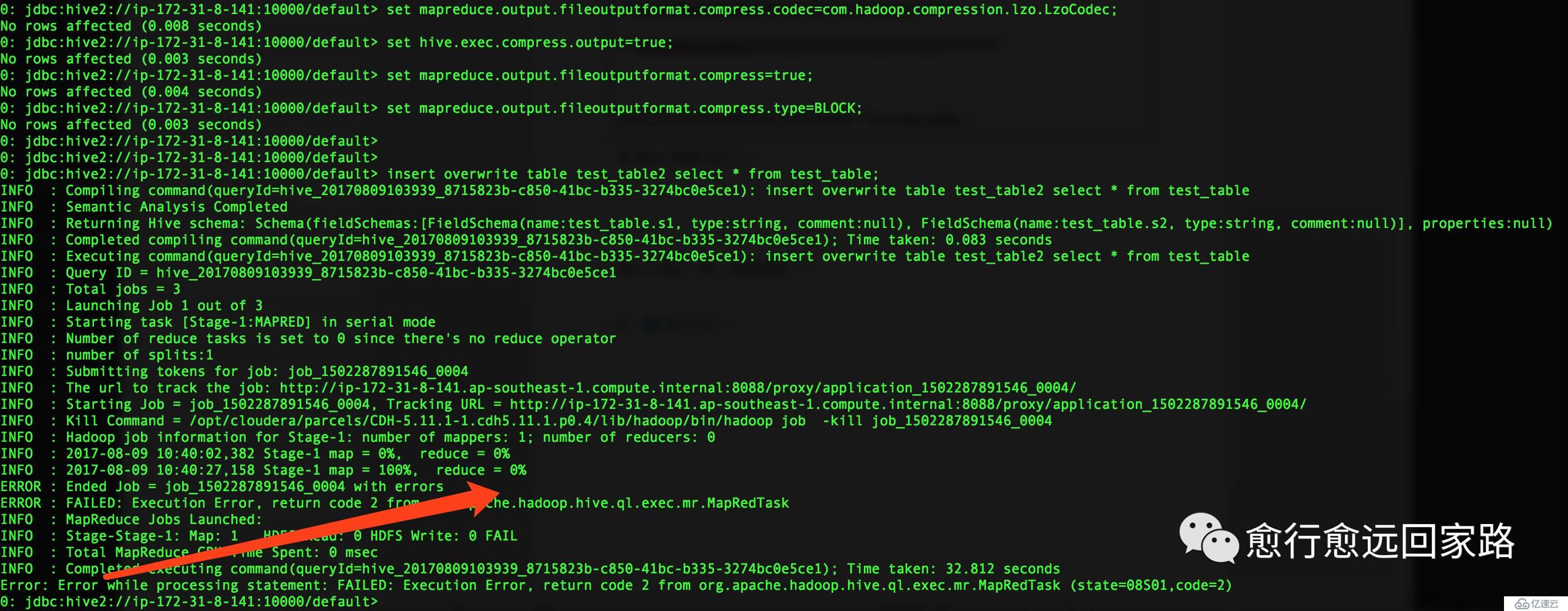
將test_table中的數據插入到test_table2,并設置輸出文件為lzo壓縮:
| set mapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzoCodec;set hive.exec.compress.output=true;set mapreduce.output.fileoutputformat.compress=true;set mapreduce.output.fileoutputformat.compress.type=BLOCK; insert overwrite table test_table2 select * from test_table; |
|---|
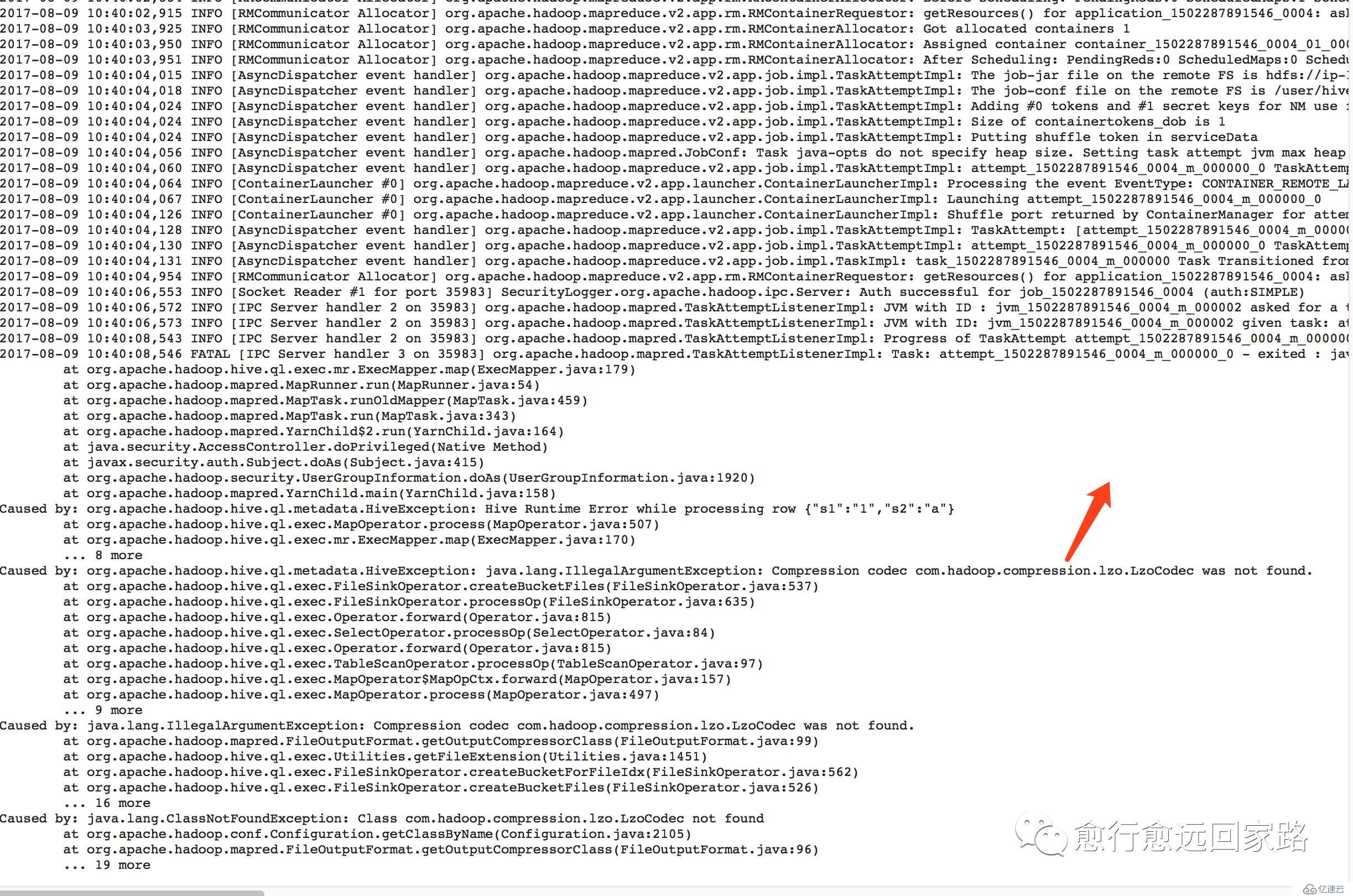
在Hive中執行報錯如下:
| Error:Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask (state=08S01,code=2) |
|---|
通過Yarn的8088可以發現是因為找不到Lzo壓縮編碼:
| Compression codec com.hadoop.compression.lzo.LzoCodec was not found. |
|---|
2.解決辦法
通過Cloudera Manager的Parcel頁面配置Lzo的Parcel包地址:
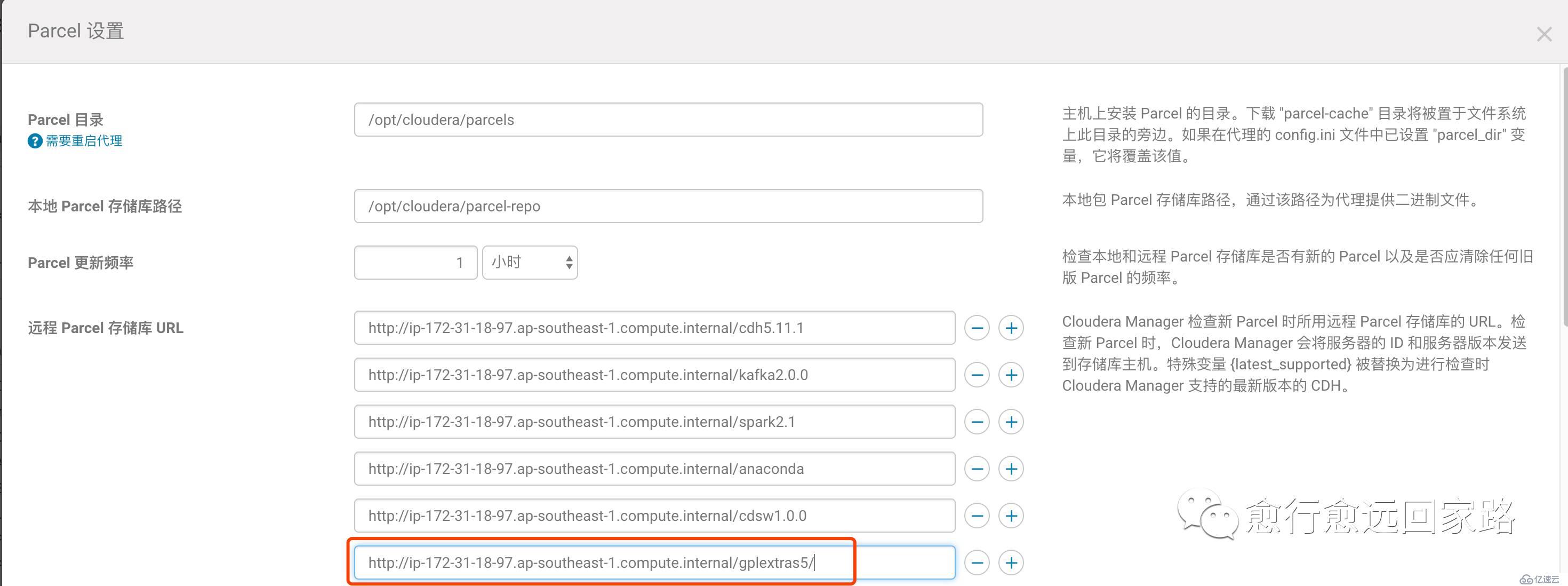
注意:如果集群無法訪問公網,需要提前下載好Parcel包并發布到httpd
下載->分配->激活





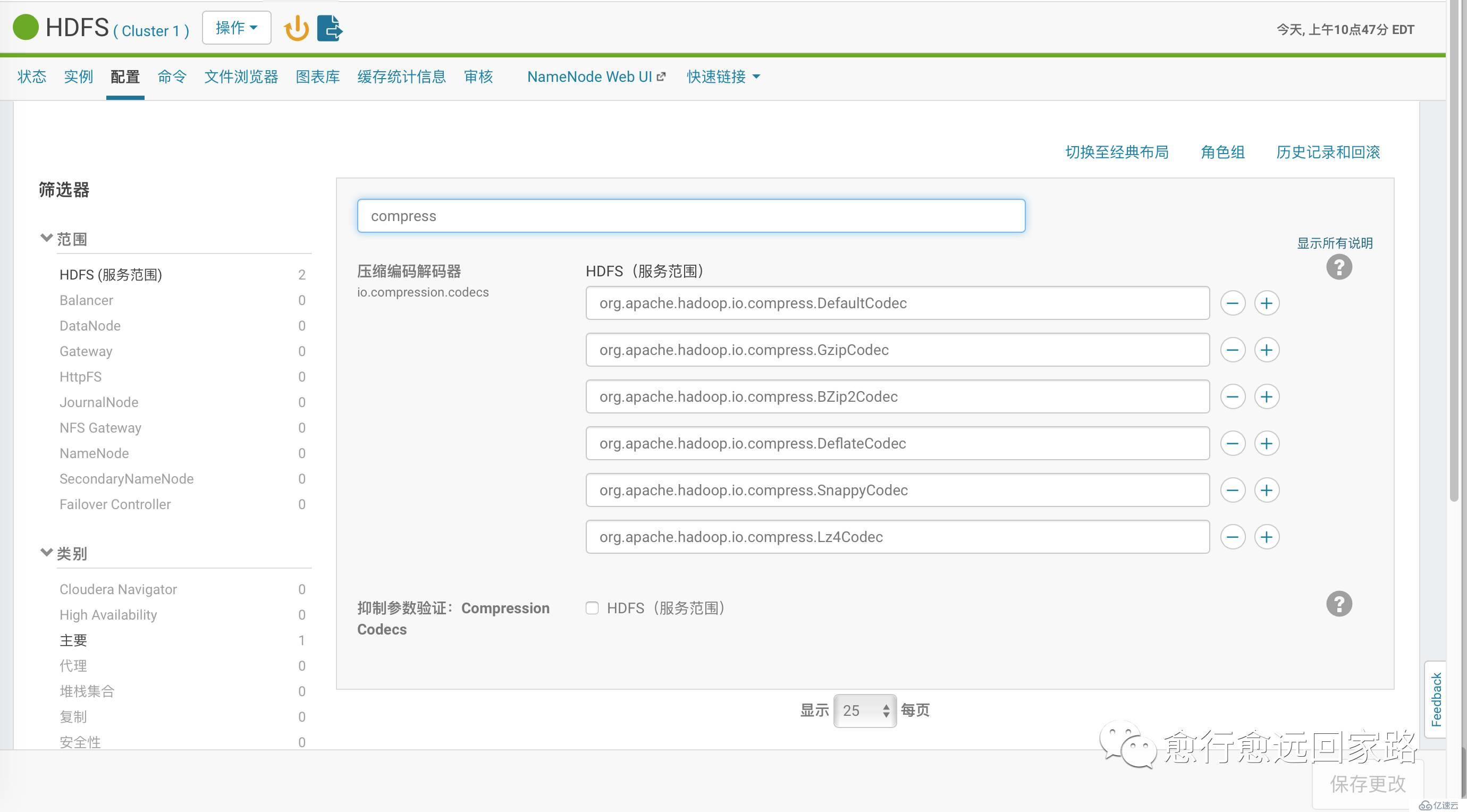
配置HDFS的壓縮編碼加入Lzo:
| com.hadoop.compression.lzo.LzoCodeccom.hadoop.compression.lzo.LzopCodec |
|---|
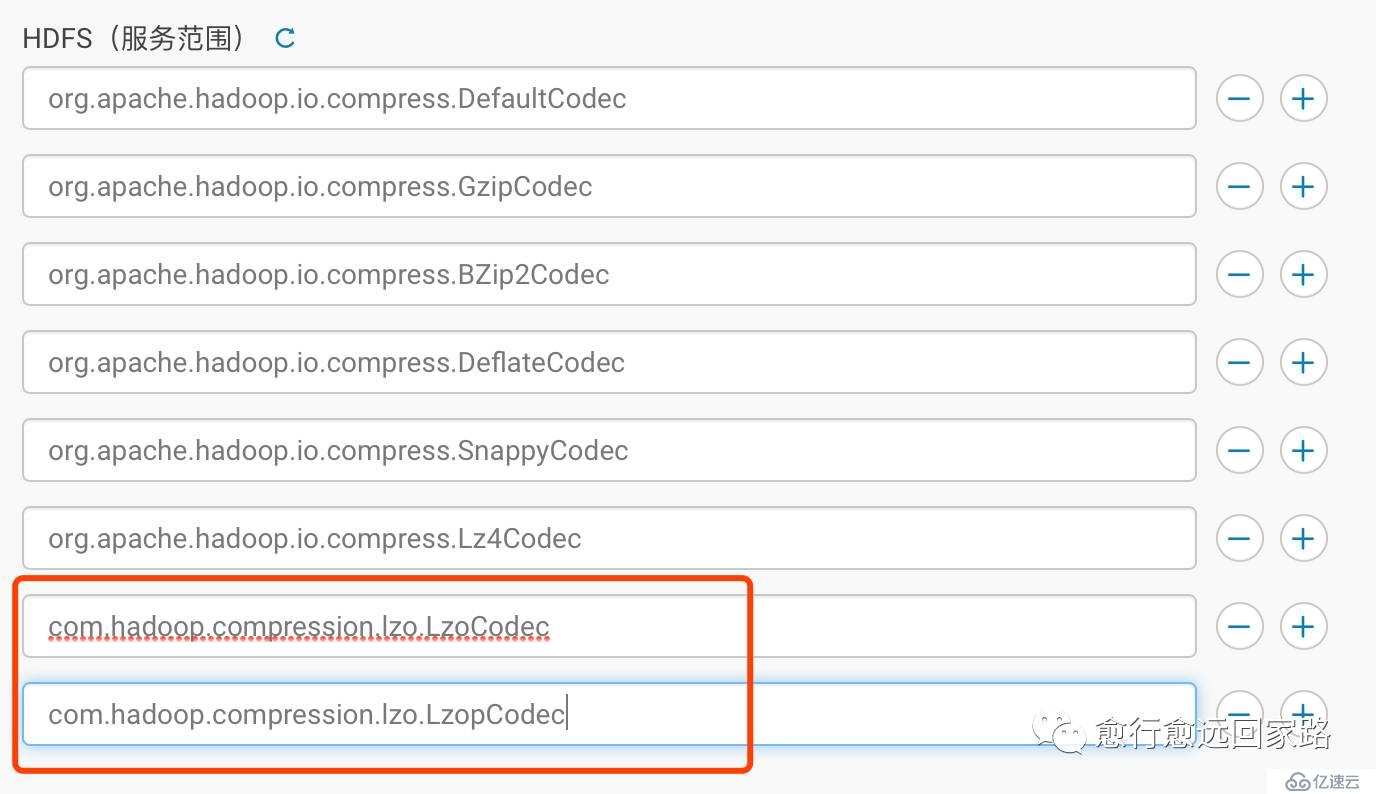
保存更改,部署客戶端配置,重啟整個集群。
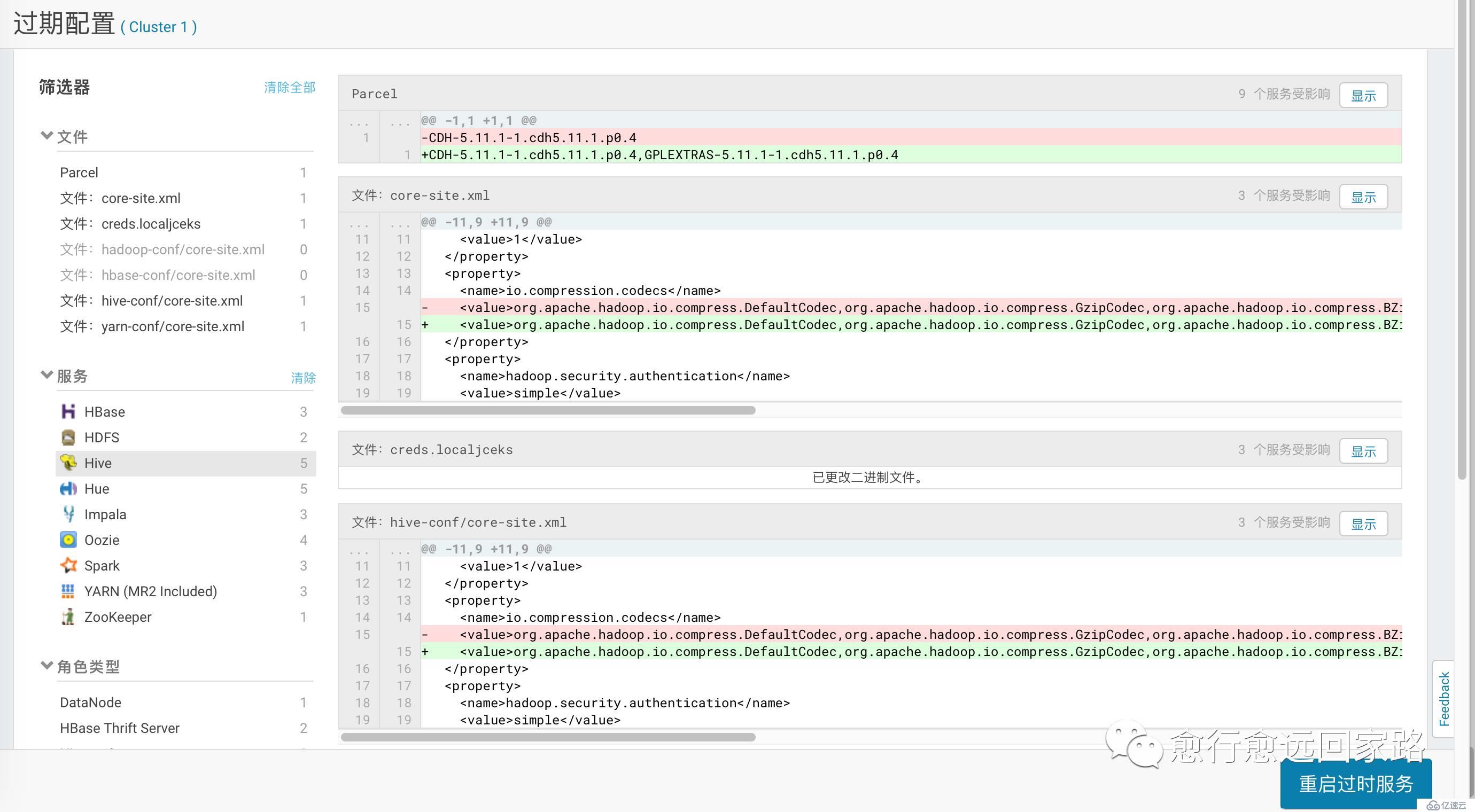
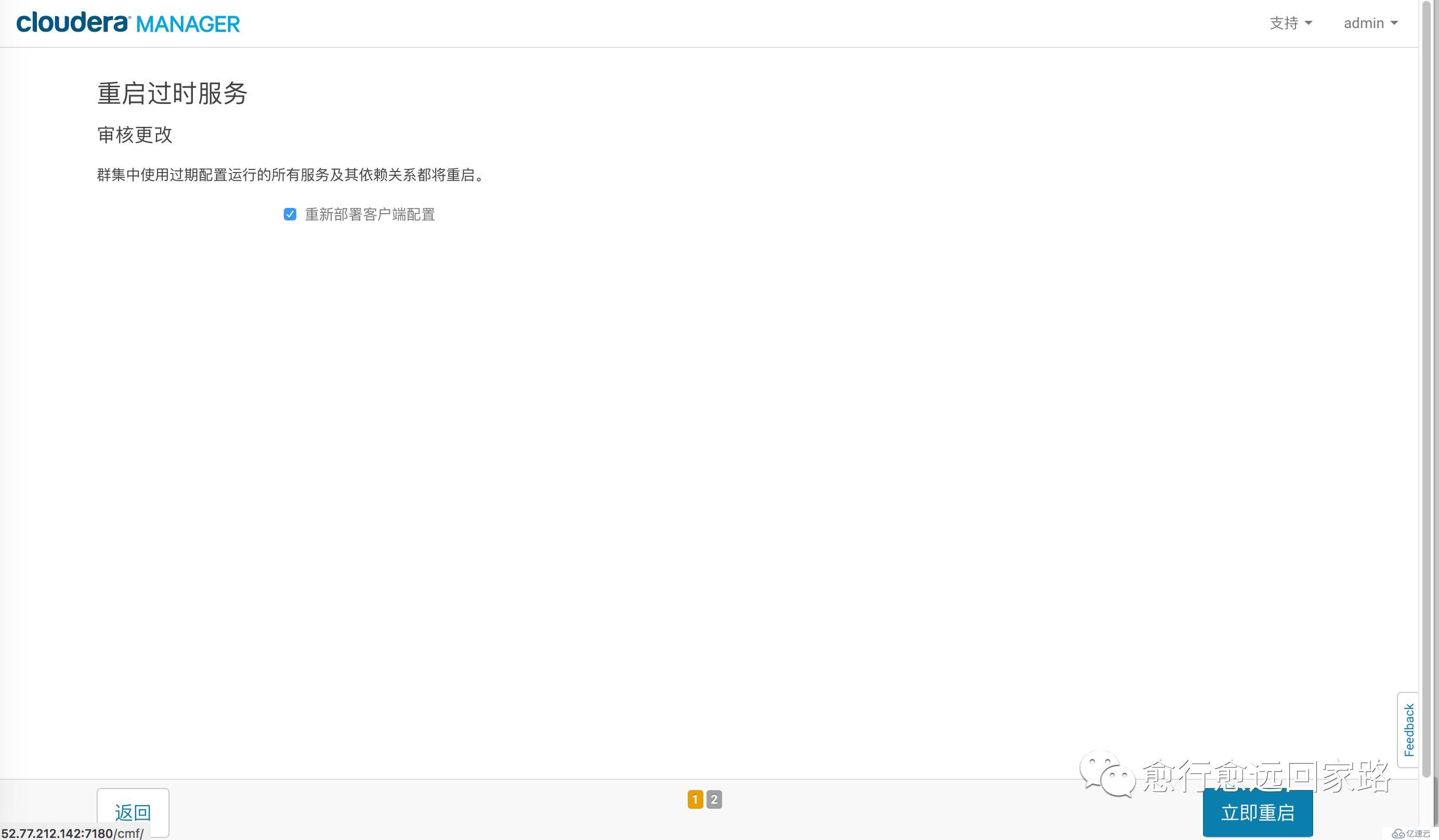
等待重啟成功:
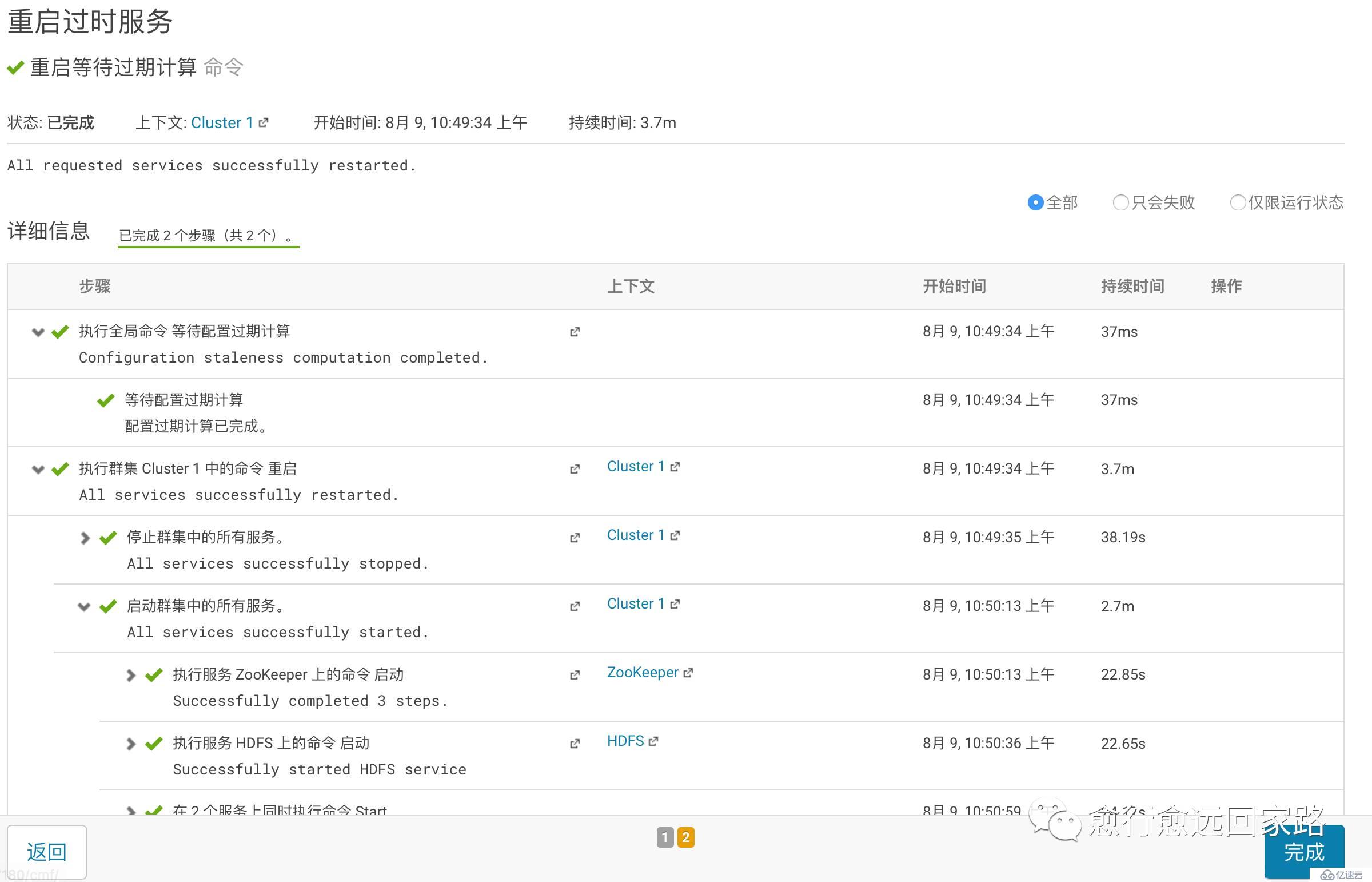
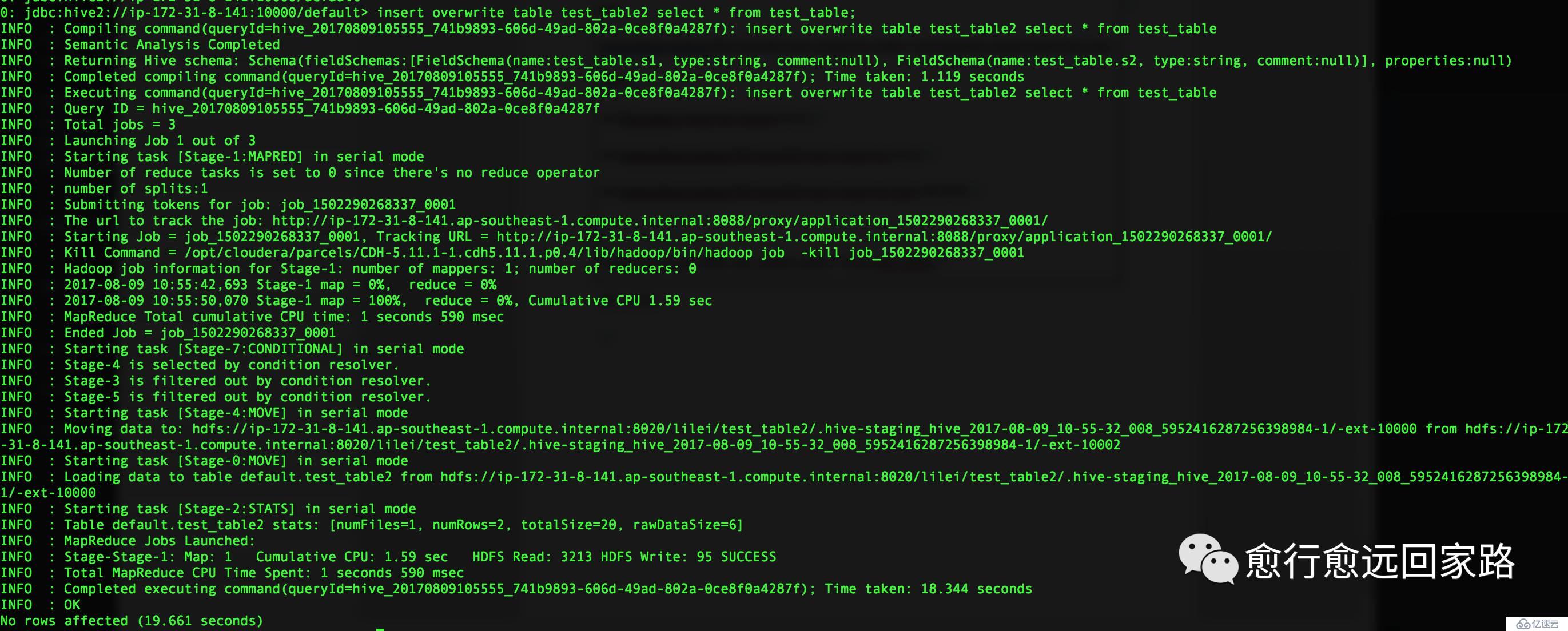
再次插入數據到test_table2,設置為Lzo編碼格式:
| set mapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzoCodec;set hive.exec.compress.output=true;set mapreduce.output.fileoutputformat.compress=true;set mapreduce.output.fileoutputformat.compress.type=BLOCK; insert overwrite table test_table2 select * from test_table; |
|---|
插入成功:
首先確認test_table2中的文件為Lzo格式:

在Hive的beeline中進行測試:

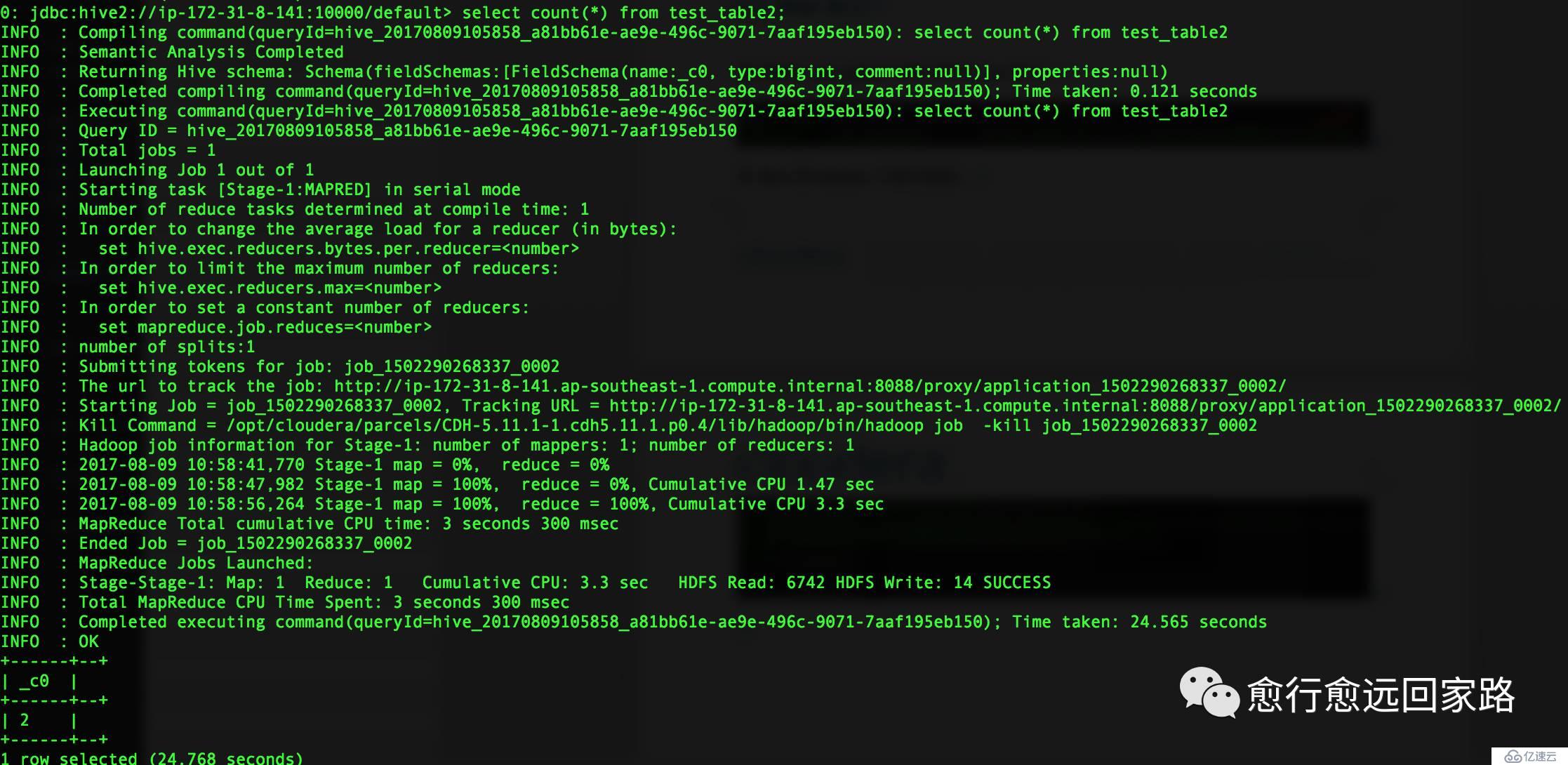
Hive基于Lzo壓縮文件運行正常。
2.2 Spark SQL驗證
| var textFile=sc.textFile("hdfs://ip-172-31-8-141:8020/lilei/test_table2/000000_0.lzo_deflate") textFile.count() sqlContext.sql("select * from test_table2") |
|---|
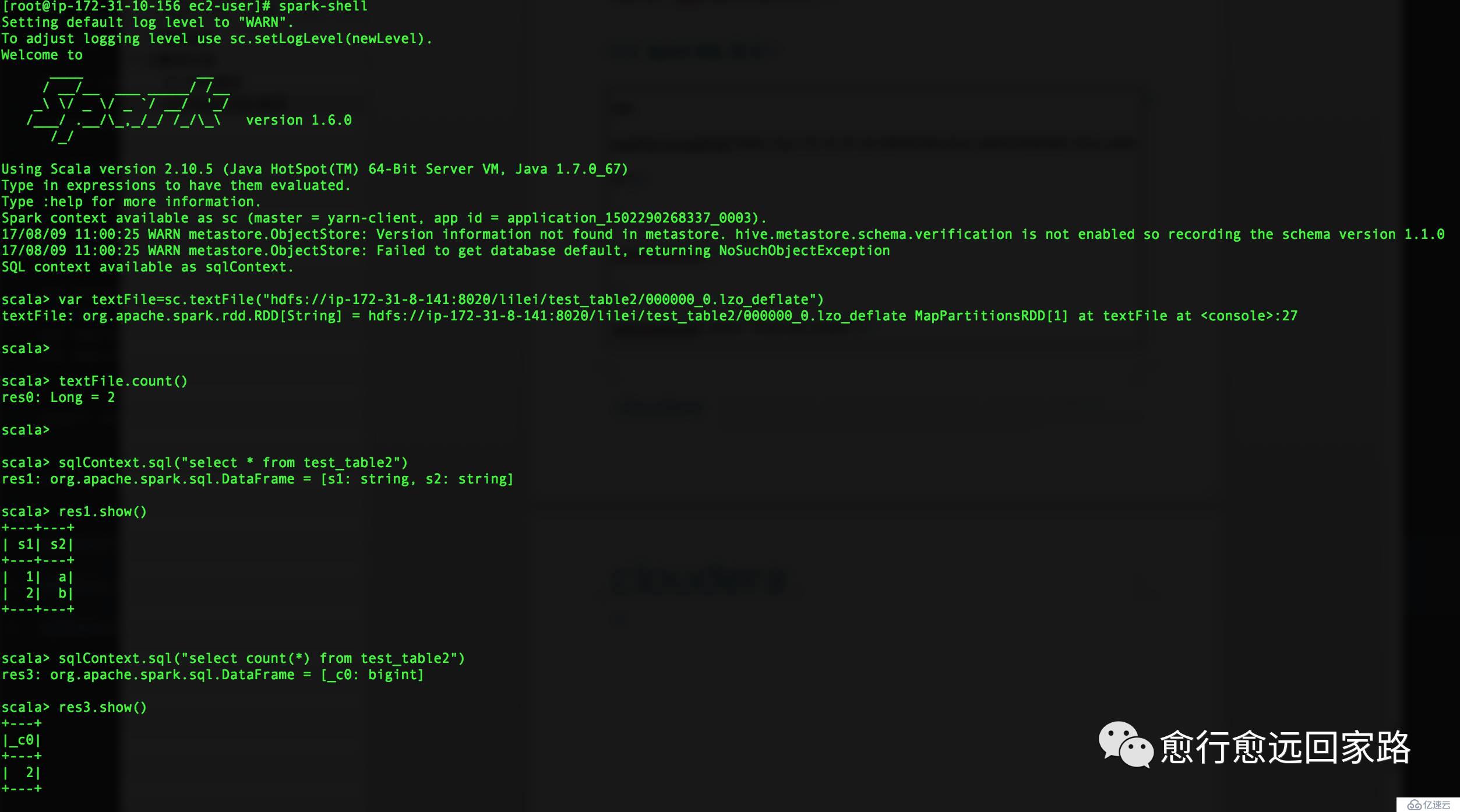
SparkSQL基于Lzo壓縮文件運行正常。
醉酒鞭名馬,少年多浮夸! 嶺南浣溪沙,嘔吐酒肆下!摯友不肯放,數據玩的花!

溫馨提示:要看高清無碼套圖,請使用手機打開并單擊圖片放大查看。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





