溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關spark的概念與架構、工作機制是怎樣的,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
一、Hadoop、Spark、Storm三大框架比較
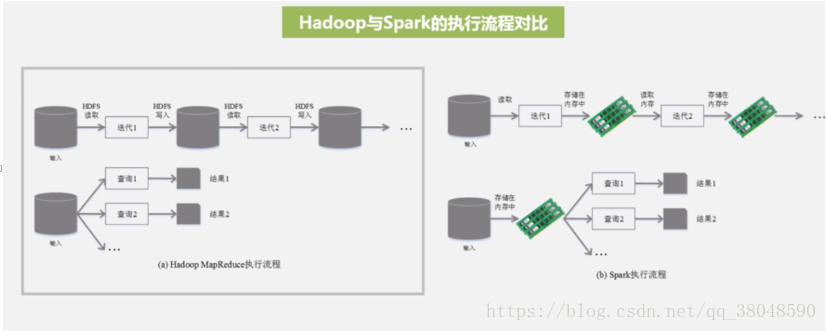
Hadoop:離線海量數據批處理,基于磁盤的
Spark:基于內存。
Spark特點:運行速度快,使用DAG執行引擎以支持循環數據流與內存計算,
2、容易使用:多種語言編程,通過spark shell進行交互式編程
3、通用性:提供了完整而強大的技術棧,包括sQL查詢、流式計算、機器學習和圖算法組件
4、運行模式多樣:可運行在獨立集群模式中,可以運行與hadoop中,也可以運行在AmazonEC2等云環境中,并可以訪問HDFS、HBase、Hive等多種數據源
Scala:多范式編程語言
函數式編程(lisp語言,Haskell語言)
運行于java平臺(jvm,虛擬機),兼容java程序
scala特性:具備強大的并發性,支持函數式編程,支持分布式系統,
語法簡潔,能提供優雅的API
scala兼容java,運行速度快,能融合到hadoop生態圈中。
scala是spark的主要編程語言,提供REPL(交互式解釋器),提高程序開發效率
Spark與Hadoop的對比
hadoop的缺點:1、表達能力有限,只能用map和reduce來表示
2、磁盤開銷大
3、延遲高,由于要寫磁盤,因此延遲高
4、任務之間的銜接涉及IO開銷
Spark相對于hadoop MapReduce的優點:
1、不局限于MapReduce,提供多種數據集操作類型,編程模型比Hadoop MapReduce更靈活
2、spark提供內存計算,可將中間結果放到內存中,對于迭代運算效率更高
3、基于DAG的任務調度機制,效率更高
二、Spark生態系統
spark生態系統主要包含了Spark Core、SparkSQL、SparkStreaming、MLLib和GraphX等組件。
1、海量數據批量處理 MapReduce
2、基于歷史數據的交互式查詢 Cloudera Impala
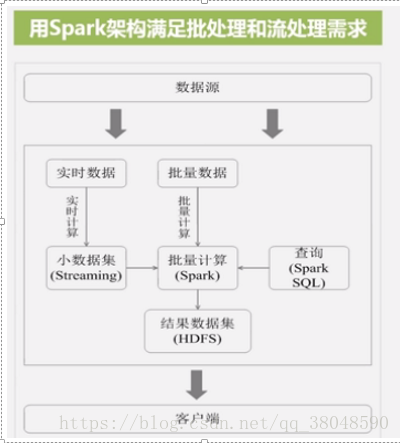
3、實時數據流的處理
spark可以部署在資源管理器Yarn之上,提供一站式大數據解決方案
spark可以同時支持海量數據批量處理、歷史數據分析、實時數據處理
spark生態系統已經成為伯克利數據分析軟件棧(BDAS)
Spark生態系統組件的應用場景
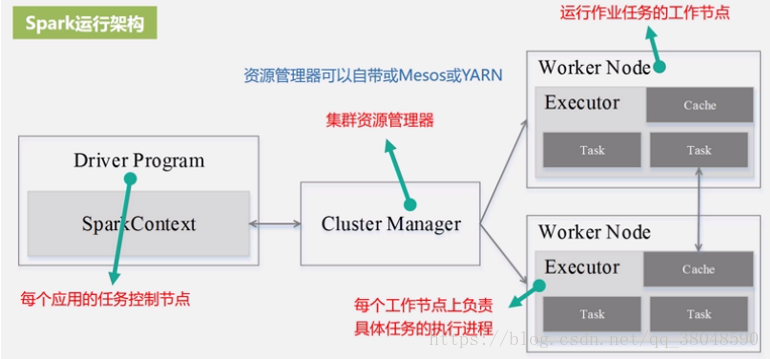
三、Spark運行架構
1、基本概念:RDD、DAG、Executor、Application、Task、Job、Stage
RDD:彈性分布式數據集的簡稱,是分布式內存的一個抽象概念 ,提供了一個高度共享的內存模型。
和MapReduce相比有兩個優點
1、利用多線程來執行具體任務,減少任務的啟動開銷。
2、同時利用內存和磁盤作為共同的存儲設備,有限的減少IO開銷。
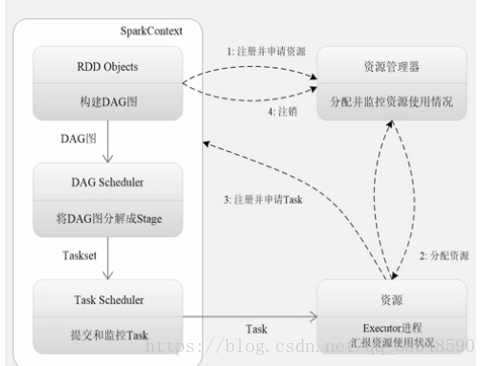
2、Spark運行基本原理
1、構建基本的運行環境,由dirver創建一個SparkContext,分配并監控資源使用情況
2、資源管理器為其分配資源,啟動Excutor進程
3、SparkContext根據RDD 的依賴關系構建DAG圖,GAG圖提交給DAGScheduler解析成stage,然后提交給底層的taskscheduler處理。
executor向SparkContext申請task,taskscheduler 將task發放給Executor運行并提供應用程序代碼
4、Task在Executor運行把結果反饋給TaskScheduler,一層層反饋上去。最后釋放資源
運行架構特點:多線程運行、運行過程與資源管理器無關、Task采用了數據本地性和推測執行來優化。
3、RDD概念
設計背景,迭代式算法,若采用MapReduce則會重用中間結果;MapReduce不斷在磁盤中讀寫數據,會帶來很大開銷。
RDD的典型執行過程
1)讀入外部數據源進行創建,分區
2)RDD經過一系列的轉化操作,每一次都會產生不同的RDD供給下一個轉化擦操作使用
3)最后一個RDD經過一個動作操作進行計算并輸出到外部數據源
優點:惰性調用、調用、管道化、避免同步等待,不需要保存中間結果
高效的原因:
1)容錯性:現有方式是用日志記錄的方式。而RDD具有天生的容錯,任何一個RDD出錯,都可以去找父親節點,代價低。RDD的每次轉換都會生成一個新的RDD,所以RDD之間就會形成類似于流水線一樣的前后依賴關系。在部分分區數據丟失時,Spark可以通過這個依賴關系重新計算丟失的分區數據,而不是對RDD的所有分區進行重新計算。
2)中間結果保存到內存,避免了不必要的內存開銷
3)存放的數據可以是java對象,避免了對象的序列化和反序列化。
RDD的依賴關系:窄依賴和寬依賴
窄依賴:(narrow dependency)是指每個父RDD的一個Partition最多被子RDD的一個Partition所使用,例如map、filter、union等操作都會產生窄依賴;(獨生子女)即rdd中的每個partition僅僅對應父rdd中的一個partition。父rdd里面的partition只去向子rdd里的某一個partition!這叫窄依賴,如果父rdd里面的某個partition會去子rdd里面的多個partition,那它就一定是寬依賴!
寬依賴(shuffle dependency):是指一個父RDD的Partition會被多個子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都會產生寬依賴;(超生)每一個父rdd的partition數據都有可能傳輸一部分數據到子rdd的每一個partition中,即子rdd的多個partition依賴于父rdd。寬依賴劃分成一個stage!!!
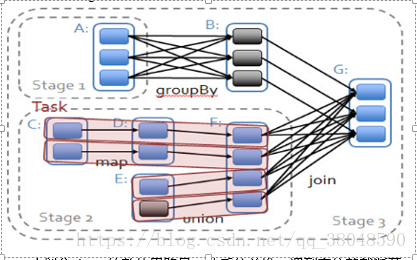
作用:完成Stage的劃分
spark劃分stage的整體思路是:從后往前推,遇到寬依賴就斷開,劃分為一個stage;遇到窄依賴就將這個RDD加入該stage中。因此在上圖中RDD C,RDD D,RDD E,RDDF被構建在一個stage中,RDD A被構建在一個單獨的Stage中,而RDD B和RDD G又被構建在同一個stage中。
Stage的劃分:
ShuffleMapStage和ResultStage:
簡單來說,DAG的最后一個階段會為每個結果的partition生成一個ResultTask,即每個Stage里面的Task的數量是由該Stage中最后一個RDD的Partition的數量所決定的!而其余所有階段都會生成ShuffleMapTask;之所以稱之為ShuffleMapTask是因為它需要將自己的計算結果通過shuffle到下一個stage中;也就是說上圖中的stage1和stage2相當于mapreduce中的Mapper,而ResultTask所代表的stage3就相當于mapreduce中的reducer。
四、Spark SQL
Spark的另外一個組件。先說一下shark(Hive on Spark),為了實現與Hive兼容,在HiveQL方面重用了HIveQL的解析、邏輯執行計劃翻譯等邏輯,把HiveQL操作翻譯成Spark上的RDD操作。相當于在最后將邏輯計劃轉換為物理計劃時將原來轉換成MapReduce替換成了轉換成Spark。
與spark相比,sparkSQL不再是依賴于Hive,而是形成了一套自己的SQL,只依賴了Hive解析、Hive元數據。從hql被解析成語法抽象樹之后,剩下的東西全部是自己的東西,不再依賴Hive原來的組件,增加了SchemaRDD,運行在SchemaRDD中封裝更多的數據,數據分析功能更強大。同時支持更多語言,除R語言外,還支持Scala、Java、python語言。
五、Spark安裝和部署
1Standalone 2、Spark on mesos 3、spark on yarn
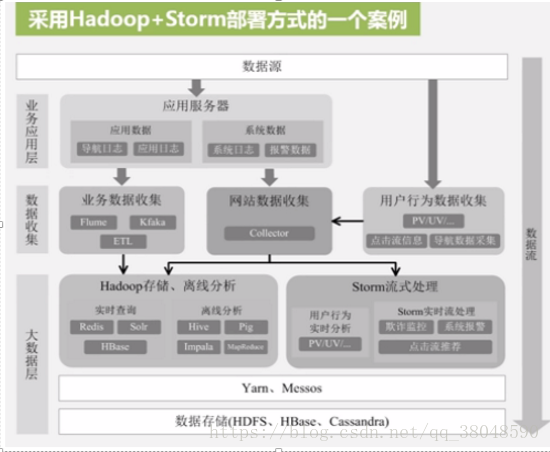
企業中的應用部署
六、spark編程
編寫應用程序
1、加載文件到RDD中
2、設置環境變量
3、創建SparkContext
4、轉換操作
5、Action計算操作1
6、創建sbt文件
7、使用sbt對其進行打包
8、把jar包提交到spark中運行。
上述就是小編為大家分享的spark的概念與架構、工作機制是怎樣的了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。