溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“機器學習的K-NN算法是怎么工作的”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“機器學習的K-NN算法是怎么工作的”吧!
K最近鄰(k-Nearest Neighbor,KNN)是數據挖掘分類技術中最簡單的方法之一,是機器學習中唯一一個不需要訓練過程的算法。K最近鄰,即每個樣本都可以用它最近的k個鄰居代表。核心思想是如果兩個樣本的特征足夠相似,它們就有更高的概率屬于同一個類別,并具有這個類別上樣本的特性。比較通俗的說法就是“近朱者赤近墨者黑”。
優點是簡單,易于理解,易于實現,無需估計參數,無需訓練;適合對稀有事件進行分類;特別適合于多分類問題, kNN比SVM的表現要好。
缺點是算法復雜度高,每一個待分類的樣本都要計算它到全體已知樣本的距離,效率較低;預測結果不具有可解釋性,無法給出像決策樹那樣的規則;
kNN算法的過程如下:
1、選擇一種距離計算方式, 通過數據所有的特征計算新數據與已知類別數據集中數據點的距離;
2、按照距離遞增次序進行排序, 選取與當前距離最小的 k 個點;
3、對于離散分類, 返回 k 個點出現頻率最多的類別作為預測分類; 對于回歸, 返回 k 個點的加權值作為預測值。
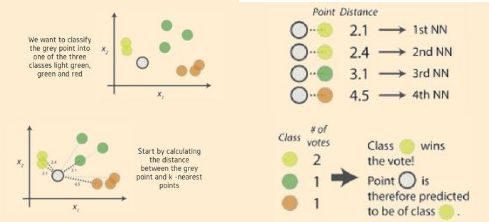
如上圖中,對灰色圓點進行分類,劃分其屬于綠、黃、紅何種類型。首先需要計算灰點和近鄰電之間的距離,確定其k近鄰點,使用周邊數量最多的最近鄰點類標簽確定對象類標簽,本例中,灰色圓點被劃分為黃色類別。
距離越近,表示越相似。距離的選擇有很多,通常情況下,對于連續變量, 選取歐氏距離作為距離度量; 對于文本分類這種非連續變量, 選取漢明距離來作為度量. 通常如果運用一些特殊的算法來作為計算度量, 可以顯著提高 K 近鄰算法的分類精度,如運用大邊緣最近鄰法或者近鄰成分分析法。
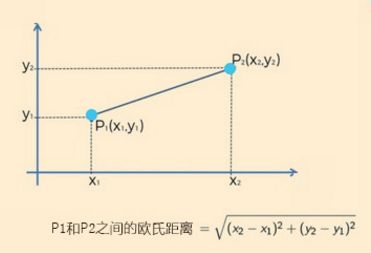
歐氏距離
切比雪夫距離
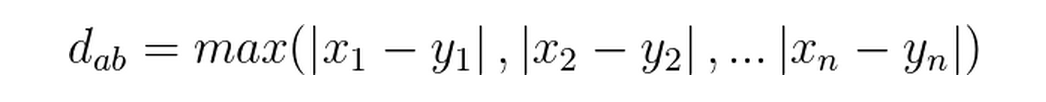
馬氏距離
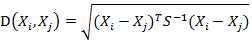
夾角余弦距離
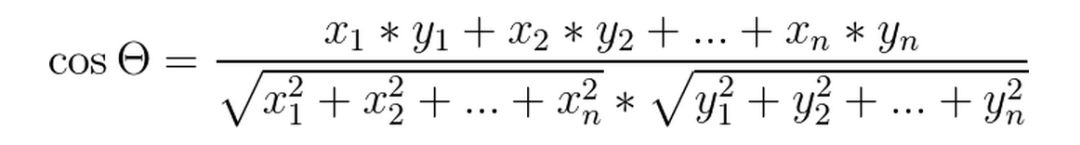
切比雪夫距離
曼哈頓(Manhattan)距離
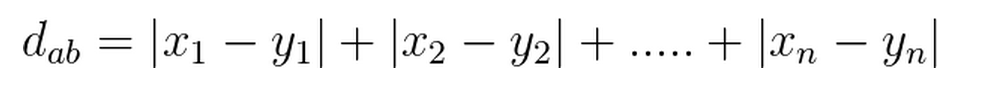
感謝各位的閱讀,以上就是“機器學習的K-NN算法是怎么工作的”的內容了,經過本文的學習后,相信大家對機器學習的K-NN算法是怎么工作的這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





