溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關如何避免Duplicate key在數據表插入中的應用,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
在一個數據表中插入數據,防止有重復的數據插入,一般DBA大多的做法是
唯一索引,主鍵,在重復的數據插入的過程中,就通過數據庫的唯一約束或檢查,將這些重復的數據拒之門外。
而很多場合下,這樣的作法并不合適,因為你遇到的程序員他可能不大會處理在數據拒絕插入的后續處理,這是比較尷尬的問題。如何能讓他用很簡單的SQL語句,來將這個問題解決,這需要 DBA 做點什么。
在SQL SERVER 中一般的情況是這樣使用的,(看下面的語句),通過在插入的過程中,進行判斷,判斷插入tbl_A 來自于 tbl_B的數據不應該和 tbl_A重復,也就是在插入的前邊要來一次機遇標識鍵的過濾
INSERT tbl_A (col, col2) SELECT col, col2 FROM tbl_B WHERE NOT EXISTS (SELECT col FROM tbl_A A2 WHERE A2.col = tbl_B.col);
這樣看著比較LOW 其實效率也一般。 所以微軟推薦的方法是下面的
Merge 功能,這個功能的在我工作的十幾年的經歷中,是比較少的,因為大多數的場景在現在的應用開發中,CRUD 的操作已經能覆蓋大部分數據庫操作的功能,大部分的計算和判斷的功能大多是在應用層來做的,通過程序來實踐,數據庫越來越多變得像一個容器被使用,數據庫只要做好MVCC,ISOLATE的事情就OK 了, 所以MERGE 的功能比較少的被引用到數據庫的使用中。
而何時要使用MERGE 功能,最近的一個項目的修改中,就遇到了,在原先的數據插入,使用了游標,這樣的結果可想而知,一定是糟糕的,數據庫使用游標本來就是下下的選擇,如果一個程序員使用了游標,除非數據量很小,并且邏輯非常復雜,而且必須要用數據庫 PROCEDURE 來做,否則游標應該被踢出數據庫的語句層。
在修改后的存儲過程中,已經沒有了游標,這是一個可喜的事情,但不好的事情又發生了,程序的邏輯中,需要判斷插入的數據是否已經在數據庫中存在,如果存在,就不要插入,否則就插入。
當然要解決這個問題,其實方法很多,相應的每種方法的限制也不少。
1 唯一索引,聯合唯一索引 (被回絕,顧問提供的存儲過程是不會使用這樣的方法來處理那些中斷,錯誤,使用這樣的方法還是要程序報錯,目的沒有達到) PASS
2 insert into ....... select ...... where not exist (select .... ) 這個就不說了,上面已經有這樣的語句了
3 本次的重點,merge into 語句, 我們還拿上面的的語句改寫成merge into 來實現。INSERT tbl_A (col, col2) SELECT col, col2 FROM tbl_B WHERE NOT EXISTS (SELECT col FROM tbl_A A2 WHERE A2.col = tbl_B.col);
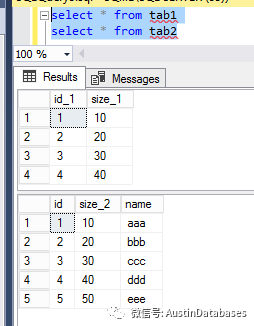
改寫后,
merge into tab1 as tab1
using (select id,size_2 from tab2) as tab2 on tab1.id_1 = tab2.id
WHEN NOT MATCHED THEN
insert (size_1) values (size_2);
結果:在沒有報錯的情況下,將兩個表重合的記錄去除后,在將不同的結果插入。
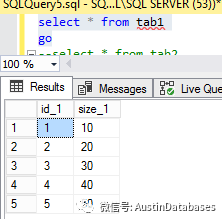
問題解決
在MYSQL 中,處理這樣的事情比SQL SERVER的方法要多,主要有兩種
1 REPLACE INTO
2 DUPLICATE KEY UPDATE
以上兩種方法,在這樣的情況下,使用 DUPLICATE KEY UPDATE 是比較合適的,具體Replace into
這里就不在介紹,這兩個區別也是顯而易見的,一個 匹配 DELETE ,在INSERT ,另一個是 匹配UPDATE
這是明顯的兩個方式的不同。
這里還是MYSQL的兩個類似SQL SERVER 表
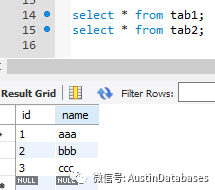
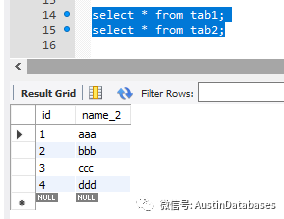
還是要將 tab2 的與 tab1 不同的數據插入到 tab1
insert into tab1 (id,name) select id,name_2 from tab2 on duplicate key update tab1.name= tab2.name_2;
以上的一條語句就可以完成這個工作,根據主鍵或者唯一索引,來判斷重復的數據,并緊緊進行更新,否則就插入tab1中在tab2中不存在的數據。
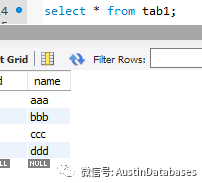
對比 SQL SERVER , MySQL在這項工作中顯然是要方便的多。
——————————————————————————————

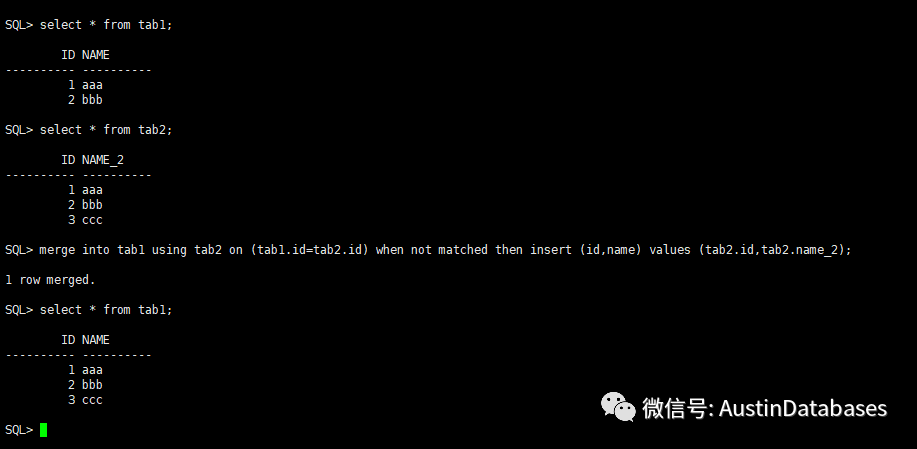
ORACLE 在處理這樣數據的方式和SQL SERVER 類似,
merge into tab1 using tab2 on (tab1.id=tab2.id) when not matched then insert (id,name) values (tab2.id,tab2.name_2);
_____________________________________________________________

Postgresql 簡述: Postgresql 的確是數據庫界的黑馬,無論是MYSQL的
duplicate key update ,還是 ORACLE SQL SERVER 支持的 MERGE INTO 語法均在數據庫中支持(11版本)
——————————————————————————————————總結:
相比MYSQL ,SQL SERVER 和ORACLE 在處理重復值上比較麻煩,雖然SQL SERVER 和ORACLE 在處理的路數上近似一致,但也有不同點,PostgreSQL 的確是后來者居上,三種數據庫支持的方式均在最新版的數據庫中支持

1 ORACLE 勝出,在MATCH 下的語句還是可以添加 where 條件,這樣操作會更靈活,SQL SERVER 不可以

2 SQL SERVER 勝出, SQL SERVER 可以在判斷中,將目標表未操作的數據刪除,但ORACLE 不可以

3 MYSQL 在使用中針對去重記錄,是最簡便最快速的,但功能簡單,如果要進行ORACLE 或者 SQL SERVER 復雜的功能,則沒有現成的語句完成。

4 PostgreSQL,勝出,三種數據庫支持的方法均都支持,缺點,需要更新的 11版本的PostgreSQL.
上述就是小編為大家分享的如何避免Duplicate key在數據表插入中的應用了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





