溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天給大家介紹一下.NET+PostgreSQL實踐與避坑技巧是怎么樣。文章的內容小編覺得不錯,現在給大家分享一下,覺得有需要的朋友可以了解一下,希望對大家有所幫助,下面跟著小編的思路一起來閱讀吧。
.NET+PostgreSQL(簡稱PG)這個組合我已經用了蠻長的一段時間,感覺還是挺不錯的。不過大多數人說起.NET平臺,還是會想起跟它“原汁原味”配套的Microsoft SQL Server(簡稱MSSQL),其實沒有MSSQL也沒有任何問題,甚至沒有Windows Server都沒問題,誰說用.NET就一定要上微軟全家桶?這都什么年代了……
PG和MSSQL的具體比較我就不詳細展開了,自行搜一下,這種比較分析文章很多。應該說兩個RDBMS各有特色,MSSQL工具集龐大(大多我們都用不到或不會用),安裝較為麻煩,PG比較小巧,但功能也不弱,我們要的它都有,性能方面我做過簡單的增刪查改的測試,兩者看不出什么明顯差別,MSSQL貌似最近才提供了Linux版,而PG天生跨平臺,MSSQL的授權費似乎不低(沒深究),PG開源免費,對比較摳的客戶來說,是不太愿意另外花錢買一套MSSQL的,PG就是非常不錯的選擇。
PG應該選擇什么版本?Linux還是Windows?當然是首選Linux,但開發環境無所謂,你在你自己的工作電腦上安裝一個Windows版也是沒問題的,有人說兩者性能差距較大,Linux明顯要好于Windows,但我有做過測試,這個并沒有被證實如此,然而,我還是推薦Linux,一來安裝簡便,二來配置簡單(命令行界面用起來感覺比較一致),三來方便寫一些腳本來實現數據庫定時備份之類的。其實你并不需要擔心安裝了PG后電腦會變慢,我完全感覺不出來,它是個安靜的乖萌寵,你不叫它,它就靜靜坐在那里,我的Windows電腦上也安裝了一個PG,我經常用它來做一些腳本測試或試驗。另外,現在也能在Windows下直接安裝Linux版本的PG了,WSL了解下?
PG有很多的版本,現在的最新版是10.4,它前面的版本是9.6.x,嗯?有點奇怪不是?10.4只有“兩段”,而9.6.x有三段,其實之前一直是三段,9表示大版本,6表示中版本,后面是小版本,小版本只有小的功能改進,不會對數據格式造成任何影響,就是說,你的PG從9.6.1升級到9.6.9,你直接升了把舊程序替換掉就是,保證沒有任何問題。但如果你之前的版本是9.5.3,要升級到9.6.9,那就不行了,因為中間版本變了,你需要用一個遷移工具去把你的舊的數據格式轉為新的方可,那對10.4這個版本而言,哪個是大版本,哪個是中版本,哪個是小版本?這里我感覺有點不連貫,PG在從9升級到10的時候,似乎丟掉了“大版本”,10雖然是9的后繼,但它應該算一個中版本,所以,10.1升級到10.4是不用轉換數據的,直接升級程序即可。那PG的下一個中版本是什么?沒錯,是11,再下一個應該就是12了。軟件這個東西,如果你沒什么歷史包袱,我覺得直接選擇最新的,比如選擇10.4,將來升級10.5,10.6的時候也簡單。
說點額外的,PG10是去年(2017)正式推出的,距離現在都不到一年,剛出來的時候我就想,這個“重大升級”(想想看iPhone X,Mac OS X,10這個數字是很特別不是?)能不能帶來性能上的大提升呢?我試了一下,結論是:沒有。確實它的升級文檔上也沒提及到性能有什么明顯提升,它主要增加了對表分區的原生支持,表分區,就是你的表中的數據的數量很多很多的時候,通過表分區來提高讀寫速度,至于表要多大才推薦分區呢?PG的官方文檔說是:如果表的尺寸趕上了你主機的內存的時候,可以考慮表分區……所以,對于那些只有區區幾千萬行或幾百萬行數據的表,你確定要分區嗎?
要用.NET使用PG,就得用nuget引入Npgsql這個包,這是它的官方網站:http://www.npgsql.org/,完全開源,它其實就是針對PG數據庫的ADO.NET引擎(ADO.NET Data Provider)。這里是它的幫助手冊:http://www.npgsql.org/doc/index.html
這里邊并沒有太多難點,你所需要做的,就是安裝好你的PG數據庫(Windows版/Linux版都行,沒有什么影響),然后創建一個.NET項目(我推薦使用.NET Core),引入Npgsql,然后照著說明手冊上的簡單例子入一下門即可。
本文當然不會具體帶你如何開始使用SELECT語句,下面主要講述在使用過程中,我們所克服的一些困難或踩過的坑。
MSSQL中用得最多的的文本類型是NVARCHAR,這是一個帶長度限制的文本類型,對應地,PG中有VARCHAR,這樣用沒問題,但PG中的文本類型其實跟MSSQL中的文本類型是有點區別的,PG的文本基本上可以認為不限長度,VARCHAR及TEXT對PG內部來說,并沒有什么差別,只是在寫入的時候,VARCHAR會檢查一下長度,所以性能上來看,VARCHAR并不比TEXT要快,較真的話可能還會慢點,因為它要檢查長度嘛,所以你在設計數據庫的時候可以無腦地將所有文本類型設置為TEXT(或后面提到的CITEXT),長度檢查工作放在業務系統中去做即可。
絕大多數時候,我們都是希望大小寫不敏感的,大小寫敏感反倒會帶來很多困惑,查詢不出,或者系統中存在同名的用戶,一個叫John另一個叫john,MSSQL可以在創建庫的時候指定大小寫不敏感,而PG似乎沒有這樣的功能,它需要借助一個額外的組件,叫CITEXT,CI的意思就是Case Insensitive。要使用CITEXT組件,你需要安裝postgresql10-contrib包(假設你安裝的是PG10,如果不是的話你去找對應的包),再使用以下命令創建CITEXT類型:
CREATE EXTENSION IF NOT EXISTS CITEXT WITH SCHEMA public;
注:一個database只需要執行一次這個命令即可
如果你使用的是psql客戶端連上去使用PG的話,這時候已經OK了,你會發現CITEXT的字段已經是大小寫不敏感了,但如果你用的是Npgsql用代碼去訪問PG的話,CITEXT似乎沒生效,其實原因是這樣的,CITEXT并不是PG的原生類型,你在用查詢語句的時候,需要在參數后面加上“::CITEXT”顯式地告訴PG,你的參數是CITEXT類型,例子如下:
SELECT * FROM test_table WHERE test_name=@TextName::CITEXT AND category=@Category::CITEXT
嗯,我承認是有點麻煩,但習慣就好,我現在還不知道有什么更佳方法。
這個異常的呈現內容大致如此:
System.NotSupportedException: The field 'application_id' has a type currently unknown to Npgsql (OID 41000). You can retrieve it as a string by marking it as unknown, please see the FAQ. 在 Npgsql.NpgsqlDataReader.GetValue(Int32 ordinal) 在 Npgsql.NpgsqlDataReader.get_Item(Int32 ordinal) ……
這個錯誤對我們而言,曾經像個幽靈似的,時不時出現,出現的時候重啟一下服務程序就好了,不再出現,然后過幾個星期或者幾個月又出現,有時候一天出現多次也不是沒有可能。最后是到github上面求助才最終搞懂了原因。鏈接:https://github.com/npgsql/npgsql/issues/1635
簡單地說,PG對各種數據類型,是有一個內部的ID值的(叫oid),Npgsql在第一次連接數據庫的時候,會獲取到這些oid值并緩存起來,對于PG的內部類型,如INT什么的,這些oid值是固定的,但對于CITEXT似乎不是這樣,因為CITEXT這個類型是我門自己用CREATE EXTENSION命令創建的(請參考本文前面內容),創建的時候確定其oid。我們在還原數據庫的時候,也相當于重新創建了CITEXT類型,這樣會導致CITEXT的oid發生變化,但Npgsql并不知道,所以就出現了這個異常。我們在開發過程中常常需要做還原數據庫的動作,所以導致了這個問題的發生。
解決方法1,當數據庫還原了之后,調用NpgsqlConnection.ReloadTypes(),刷新各類型oid,但這個很難,因為還原數據庫都是手動操作,做完之后打開網頁,在上面點一下通知程序嗎?
解決方法2,重啟一下程序。這個其實跟解決方法1差不多,只不過不需要寫什么額外代碼,考慮到還原數據庫這個動作其實也不是太頻繁,只是在開發環境中做,所以重啟就重啟吧,我們現在就干,規定還原數據庫后自己重啟下服務程序。(寫個腳本干這個事情很簡單)
這個問題我同樣到github上求助了,鏈接:https://github.com/npgsql/npgsql/issues/1838
這個問題比前面的問題可能更嚴重,因為我很可能捕捉不到異常(就是說有時候可以捕捉到,有時候不行),程序直接崩潰了,對于一個.NET程序來說,這是很不應該的事情,即便我沒單獨寫try-catch,程序的最外層異常處理器應該也能捕捉到相關的Exception并log對不?但偏不,沒有log,也捕捉不到。所以至今我懷疑這是一個.NET的bug,可能跟Npgsql并沒有關系。
問題的原因如github上所描述,是找到了,但卻無法從根本上修正,這個問題其實是個簡單的“事務超時”問題。
我們的程序在第一次啟動的時候會初始化數據庫的表,插入大量的初始化數據,由于我們公司的開發環境比較特殊,數據庫延遲十分高,所以導致插入速度很慢,每條插入耗時可高達幾十毫秒,(生產環境并沒有這個問題)這樣一萬多條數據下來就導致了事務超時(事務超時默認時間是1分鐘)。解決方法當然很明顯了:初始化的時候,臨時增加 TransactionScope的超時值,增加到10分鐘,這樣總歸沒問題了。
類似這種問題我們只能通過一些外部的workaround來預防,很難從根本上解決。
這又是一個有點棘手的事情,首先是這個中文翻譯得很不好,這是一條數據庫拋出來的出錯信息,它的英文是“Prepared transactions are disabled”,其正確的中文翻譯我覺得應該是:預處理事務已被禁用。唉,所以我說為什么要英文版,如果提示中文,想在網上找答案都會多些障礙。
對事務的使用,這里有個簡單的例子:
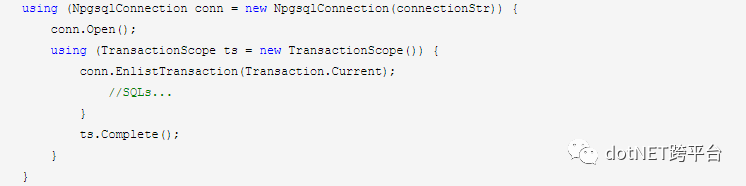
什么叫“預處理事務”?其實很簡單,就是“事務包事務”,就是可以分步提交的事務,比如我先開啟了一個事務A,在這個事務中我又開啟了一個事務B,B提交,A再提交。PG對于預處理事務是默認關閉的,當然了,你可以打開它,編輯配置文件postgresql.conf,把max_prepared_transactions改為100(默認是0,0表示禁用),重啟PG服務即可。
但你確定你真的用得到預處理事務嗎?我看下來我們是用不到的,但為什么出現這個問題?——還是我們程序寫得有問題,即便你從單個方法上看不出來事務包事務。以下兩種場景可能會出現“預處理事務”:
1,我創建了一個方法A訪問數據庫,這個方法可能會被其它方法調用,所以它有個DbConnection類型的參數,表示調用者負責打開數據庫連接傳遞過來,而A里面開啟了事務,而調用者并不知情,也開啟了事務,形成預處理事務
2,這種情況更隱晦些,數據庫連接字符串,如:Host=192.168.1.101; Username=postgres; Password=123456; Database=testdb; Enlist=true,在后面有個叫Enlist的參數為true,這表示這個連接在打開的時候,會自動Enlist到當前執行上下文的Transaction中去,如果當前執行上下文中打開了事務(從代碼上看包含在了using(TransactionScope)中),那這個數據庫連接就自動Enlist上去了,再考慮這樣的場景:A方法會自己打開數據庫連接去查詢點什么東西,B方法也會訪問數據庫,且B方法會使用事務,事務中調用了A方法,A方法打開數據庫連接的時候發現當前執行上下文中存在Transaction,于是自動Enlist上去了,不經意間形成了預處理事務,且還是“分布式”的(A和B打開的可能是不同的數據庫連接),這種情況應該并不是你所需要的
那我們應該怎么做?下面是我的做法:
1,max_prepared_transactions還是設置為0,關掉,因為我們真用不到,如果用得到,那就是我們代碼寫錯了,所以一旦出現“禁用已準備好的事務”這個異常,就回去檢查代碼
2,把Enlist=true在數據庫連接字符串中去掉,這么一來,每次使用事務都需要顯式地調用 conn.EnlistTransaction(Transaction.Current),雖然對了一行代碼,但語義更明確,也不用考慮到底是TransactionScope包DbConnection或反過來DbConnection包TransactionScope
3,規范化我們的數據庫訪問代碼,明確哪些是需要事務哪些是不需要的,在各個方法的注釋上注明
它對應的英文是:Cound not serialize access due to read/write dependencies among transactions,這個應該怎么理解呢?其實了解數據庫事務隔離級別的人對這個應該不會陌生。.NET的TransactionScope默認使用的是事務隔離級別中的最高級別——Serializable(可序列化)。這個級別最大程度上確保了數據的一致性,但代價也挺高,一來速度較慢,二來很容易出現“事務間讀/寫依賴”,就是這個錯誤了,舉個簡單的例子:
A、B兩個事務,同時訪問test表中id為50的一條記錄,A讀出這條記錄,接著B更新了這條記錄并提交,根據可序列化的隔離級別的規則,A并不知道B更新了記錄,A在B提交后嘗試修改這條記錄,這時候數據庫就會讓A事務失敗,并拋出這個異常,因為讓A修改成功的話,就會導致B之前的修改不經意間丟失了,可序列化隔離級別并不允許這種情況的發生。
所以,這是個“正常的錯誤”,按常規的業務邏輯來說,應該很少會出現,如果真的出現,且頻繁出現,那需要考慮下是不是業務邏輯設計得不太合理,看看能不能從設計上避免這個問題,如果業務邏輯一定如此,那可以用下面的方法嘗試一下:
1,將這種并行事務用客戶端代碼排個隊,弄個線程安全隊列,逐個執行,這樣速度會慢點,但確保了每個事務都能成功
2,捕捉這個異常,然后自動重試,其實這也是數據庫推薦的正統的做法
3,降低事務隔離級別,這個可能會出現問題,也可能不出現,這完全取決于你的業務,關于事務隔離級別,這是個蠻大的話題,我考慮適當時候再寫一篇文章
4,對于極少出現的頻次來說,可以不處理,僅僅需要捕捉這個異常類型,然后提示用戶重試即可,很多網站貌似都這么干的
以上就是.NET+PostgreSQL實踐與避坑技巧是怎么樣的全部內容了,更多與.NET+PostgreSQL實踐與避坑技巧是怎么樣相關的內容可以搜索億速云之前的文章或者瀏覽下面的文章進行學習哈!相信小編會給大家增添更多知識,希望大家能夠支持一下億速云!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





