溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在整個spark任務的編寫、提交、執行分三個部分:
① 編寫程序和提交任務到集群中
②sparkContext的初始化
③觸發action算子中的runJob方法,執行任務
①編程spark程序的代碼
②打成jar包到集群中運行
③使用spark-submit命令提交任務
在提交任務時,需要指定 --class 程序的入口(有main方法的類),
1) spark-submit --class xxx
2) ${SPARK_HOME}/bin/spark-class org.apache.spark.deploy.SparkSubmit $@
3) org.apache.spark.launcher.Main
submit(appArgs, uninitLog)
doRunMain()
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
childMainClass:…./.WordCount (自己編寫的代碼的主類)
mainClass = Utils.classForName(childMainClass)
val app: SparkApplication = if() {} else {new JavaMainApplication(mainClass)}
app.start(childArgs.toArray, sparkConf) // 通過反射調用mainClass執行
// 到此為止,相當于調用了我們的自己編寫的任務類的main方法執行了。!!!
val mainMethod = klass.getMethod("main", new ArrayString.getClass)
mainMethod.invoke(null, args)
④開始執行自己編寫的代碼
當自己編寫的程序運行到:new SparkContext()時,就開始了精妙而細致的sparkContext的初始化。
sparkContext的相關介紹:sparkContext是用戶通往spark集群的唯一入口,可以用來在spark集群中創建RDD、累加器和廣播變量。sparkContext也是整個spark應用程序的一個至關重要的對象,是整個應用程序運行調度的核心(不是資源調度的核心)。在初始化sparkContext時,同時的會初始化DAGScheduler、TaskScheduler和SchedulerBackend,這些至關重要的對象。
sparkContext的構建過程: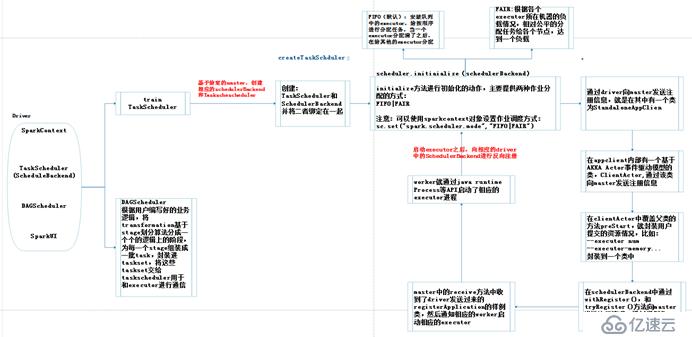
初始化 TaskScheduler
初始化 SchedulerBackend
初始化 DAGScheduler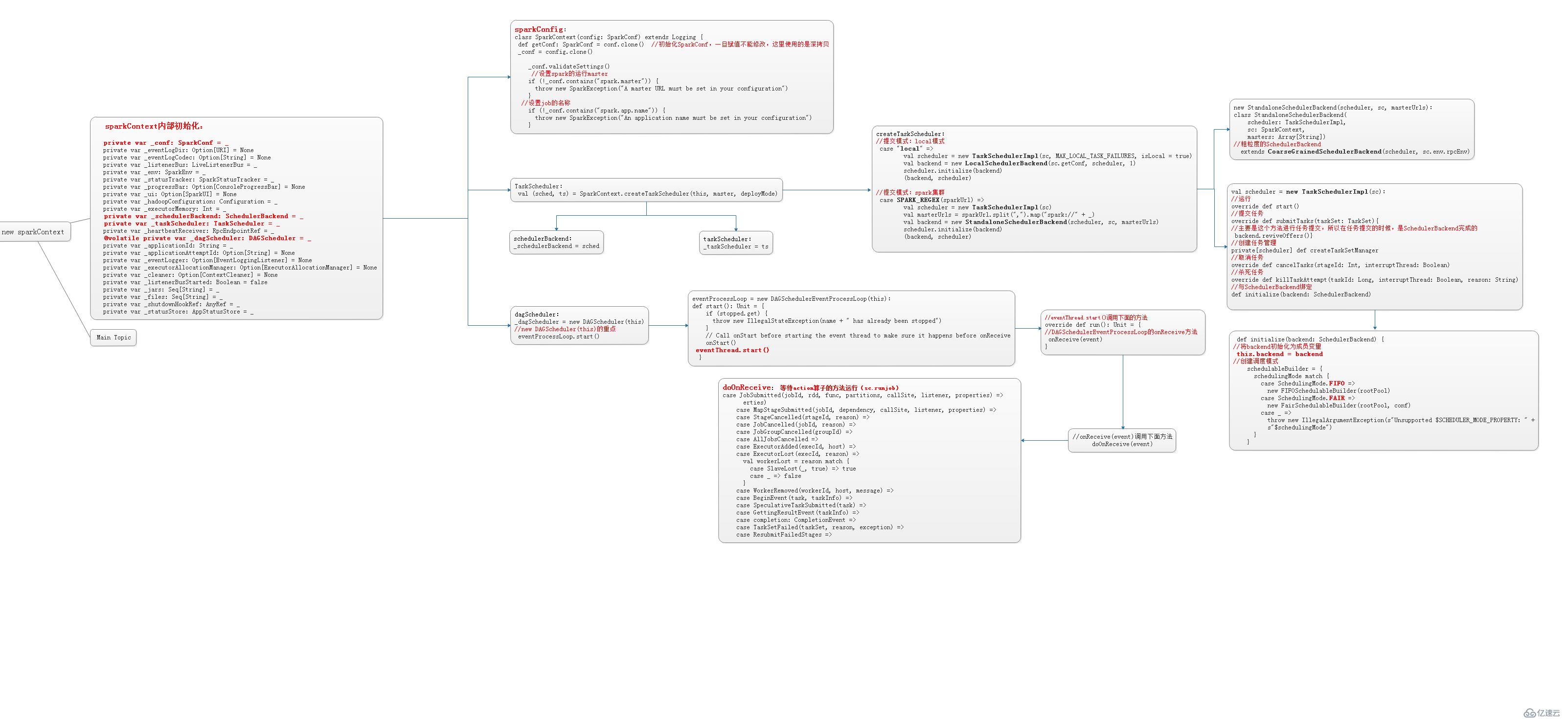
driver向master注冊申請資源。
Worker負責啟動executor。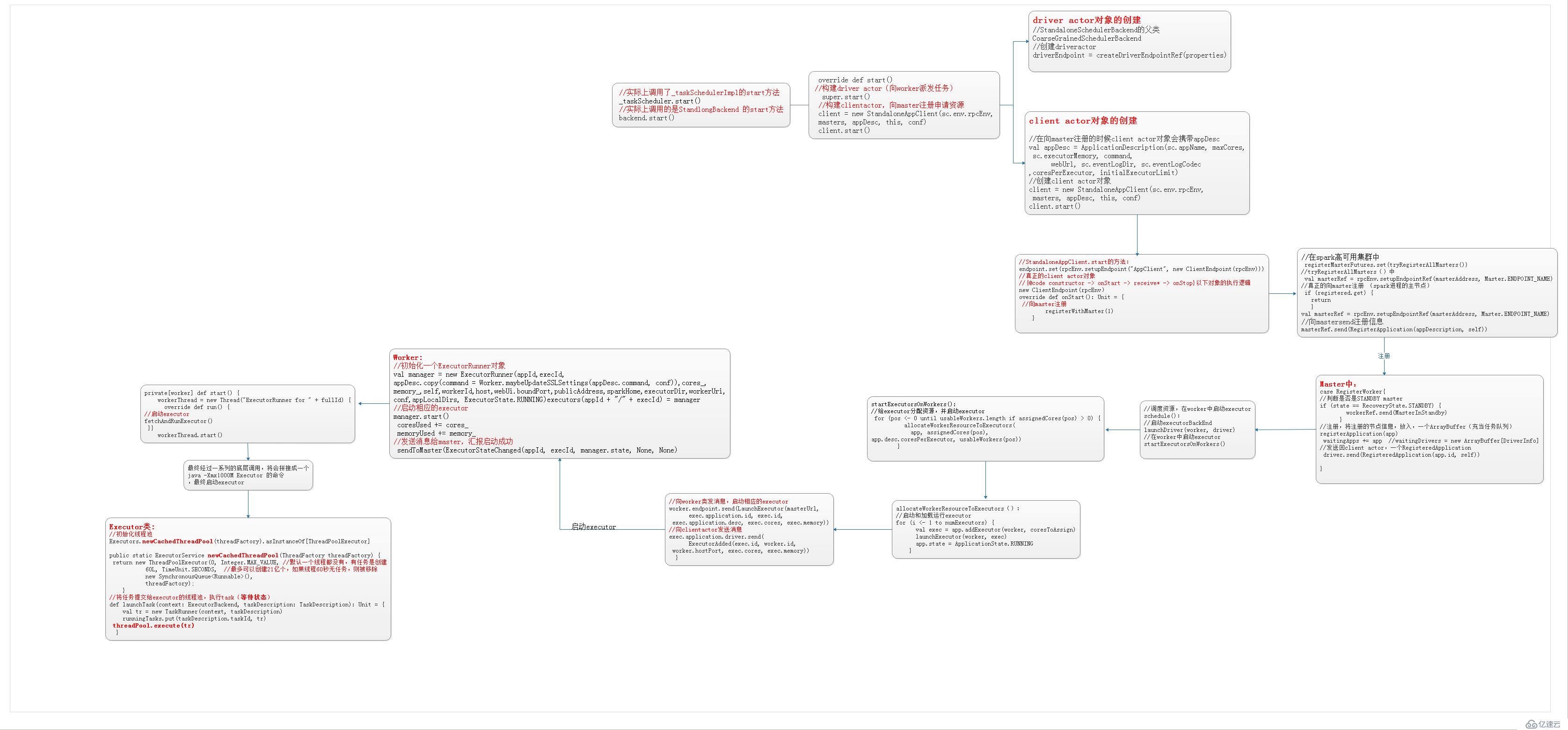

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





