溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Tensorflow中怎么實現CNN文本分類,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
我們將在這篇文章中使用的數據集是 Movie Review data from Rotten Tomatoes,也是原始文獻中使用的數據集之一。 數據集包含10,662個示例評論句子,正負向各占一半。 數據集的大小約為20k。 請注意,由于這個數據集很小,我們很可能會使用強大的模型。 此外,數據集不附帶拆分的訓練/測試集,因此我們只需將10%的數據用作 dev set。 原始文獻展示了對數據進行10倍交叉驗證的結果。
這里不討論數據預處理代碼,代碼可以在 Github 上獲得,并執行以下操作:
從原始數據文件中加載正負向情感的句子。
使用與原始文獻相同的代碼清理文本數據。
將每個句子加到最大句子長度(59)。我們向所有其他句子添加特殊的操作,使其成為59個字。填充句子相同的長度是有用的,因為這樣就允許我們有效地批量我們的數據,因為批處理中的每個示例必須具有相同的長度。
構建詞匯索引,并將每個單詞映射到0到18,765之間的整數(詞庫大小)。 每個句子都成為一個整數向量。
原始文獻的網絡結構如下圖: 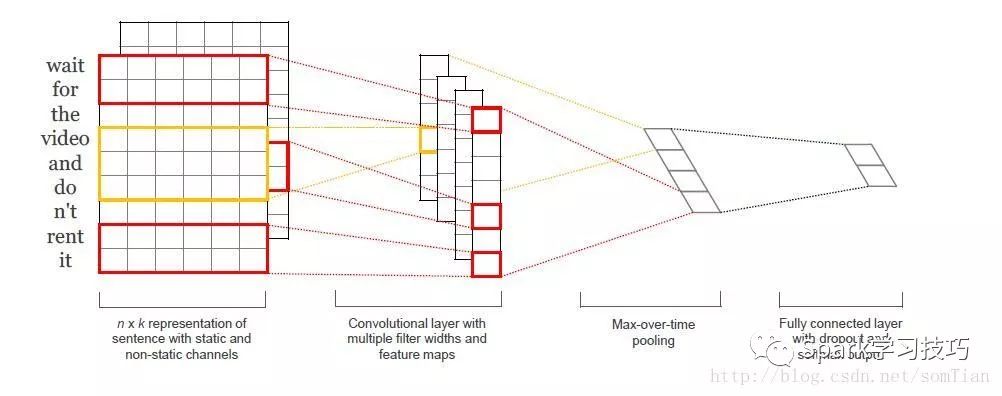
第一層將單詞嵌入到低維向量中。 下一層使用多個過濾器大小對嵌入的字矢量執行卷積。 例如,一次滑過3,4或5個字。 接下來,我們將卷積層的max_pooling結果作為一個長的特征向量,添加dropout正則,并使用softmax層對結果進行分類。
因為這是是一篇教學性質的博客,所以對于原始文獻的模型進行一下簡化:
我們不會對我們的詞嵌入使用預先訓練的word2vec向量。 相反,我們從頭開始學習嵌入。
我們不會對權重向量執行L2規范約束。 《A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification》這篇文章中發現約束對最終結果幾乎沒有影響。(關注公眾號輸入cnn獲取)
原始實驗用兩個輸入數據通道 - 靜態和非靜態字矢量。 我們只使用一個通道。
將這些擴展代碼添加到這里是比較簡單的(幾十行代碼)。 看看帖子結尾的練習。
為了允許各種超參數配置,我們將代碼放入TextCNN類中,在init函數中生成模型圖。
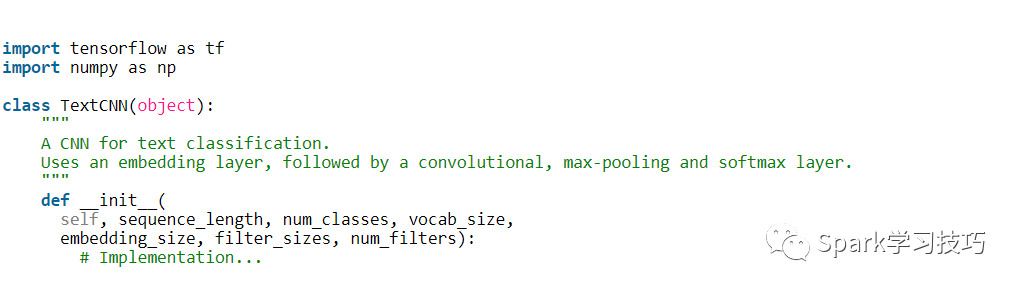
為了實例化類,我們傳遞以下參數:
sequence_length - 句子的長度。注意:我們將所有句子填充到相同的長度(我們的數據集為59)。
num_classes - 輸出層中的類數,在我們的例子中為(消極,積極)。
vocab_size - 我們的詞匯量的大小。 這需要定義我們的嵌入層的大小,它將具有[vocabulary_size,embedding_size]的形狀。
embedding_size - 嵌入的維度。
filter_sizes - 我們想要卷積過濾器覆蓋的字數。 我們將為此處指定的每個大小設置num_filters。 例如,[3,4,5]意味著我們將有一個過濾器,分別滑過3,4和5個字,總共有3 * num_filters個過濾器。
num_filters - 每個過濾器大小的過濾器數量(見上文)。
首先定義網絡的輸入數據

tf.placeholder創建一個占位符變量,當我們在訓練集或測試時間執行它時,我們將其饋送到網絡。 第二個參數是輸入張量的形狀:None意味著該維度的長度可以是任何東西。 在我們的情況下,第一個維度是批量大小,并且使用“None”允許網絡處理任意大小的批次。
將神經元保留在丟失層中的概率也是網絡的輸入,因為我們僅在訓練期間使用dropout。 我們在評估模型時禁用它(稍后再說)。
我們定義的第一層是嵌入層,它將詞匯詞索引映射到低維向量表示中。 它本質上是一個從數據中學習的lookup table。

我們在這里使用了幾個功能:
tf.device(“/ cpu:0”)強制在CPU上執行操作。 默認情況下,TensorFlow將嘗試將操作放在GPU上(如果有的話)可用,但是嵌入式實現當前沒有GPU支持,并且如果放置在GPU上會引發錯誤。
tf.name_scope創建一個名稱范圍,名稱為“embedding”。 范圍將所有操作添加到名為“嵌入”的頂級節點中,以便在TensorBoard中可視化網絡時獲得良好的層次結構。
W是我們在訓練中學習的嵌入矩陣。 我們使用隨機均勻分布來初始化它。 tf.nn.embedding_lookup創建實際的嵌入操作。 嵌入操作的結果是形狀為[None,sequence_length,embedding_size]的三維張量。
TensorFlow的卷積轉換操作具有對應于批次,寬度,高度和通道的尺寸的4維張量。 我們嵌入的結果不包含通道尺寸,所以我們手動添加,留下一層shape為[None,sequence_length,embedding_size,1]。
現在我們已經準備好構建卷積層,然后再進行max-pooling。 注意:我們使用不同大小的filter。 因為每個卷積產生不同形狀的張量,我們需要迭代它們,為它們中的每一個創建一個層,然后將結果合并成一個大特征向量。
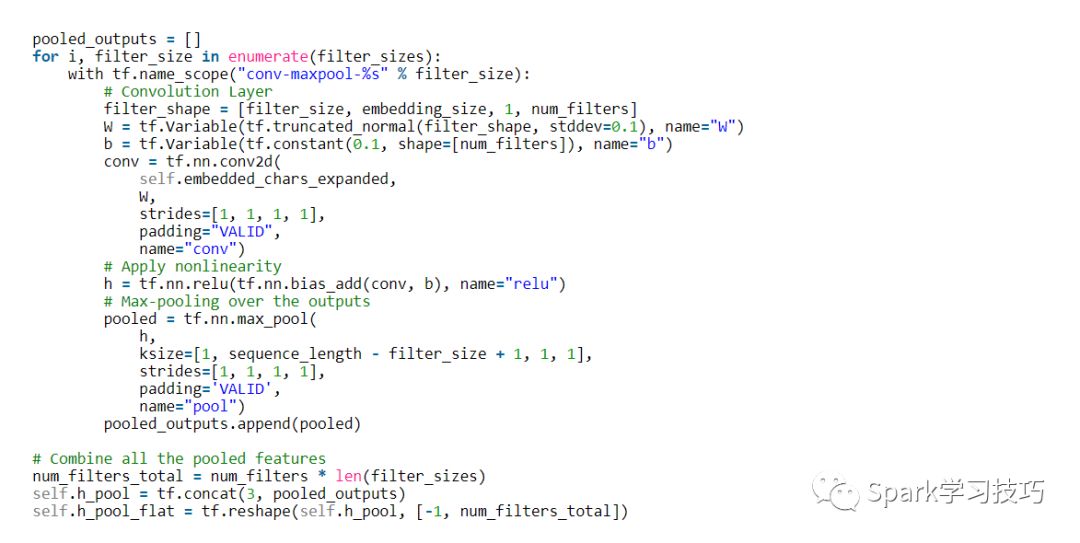
這里,W是我們的濾波器矩陣,h是將非線性應用于卷積輸出的結果。 每個過濾器在整個嵌入中滑動,但是它涵蓋的字數有所不同。 “VALID”填充意味著我們在沒有填充邊緣的情況下將過濾器滑過我們的句子,執行給我們輸出形狀[1,sequence_length - filter_size + 1,1,1]的窄卷積。 在特定過濾器大小的輸出上執行最大值池將留下一張張量的形狀[batch_size,1,num_filters]。 這本質上是一個特征向量,其中最后一個維度對應于我們的特征。 一旦我們從每個過濾器大小得到所有的匯總輸出張量,我們將它們組合成一個長形特征向量[batch_size,num_filters_total]。 在tf.reshape中使用-1可以告訴TensorFlow在可能的情況下平坦化維度。
Dropout可能是卷積神經網絡正則最流行的方法。Dropout背后的想法很簡單。Dropout層隨機地“禁用”其神經元的一部分。 這可以防止神經元共同適應(co-adapting),并迫使他們學習個別有用的功能。 我們保持啟用的神經元的分數由我們網絡的dropout_keep_prob輸入定義。 在訓練過程中,我們將其設置為0.5,在評估過程中設置為1(禁用Dropout)。

使用max-pooling(with dropout )的特征向量,我們可以通過執行矩陣乘法并選擇具有最高分數的類來生成預測。 我們還可以應用softmax函數將原始分數轉換為歸一化概率,但這不會改變我們的最終預測。
這里,tf.nn.xw_plus_b是執行Wx + b矩陣乘法的便利包裝器。

使用分數我們可以定義損失函數。 損失是對我們網絡錯誤的衡量,我們的目標是將其最小化。分類問題的標準損失函數是交叉熵損失 cross-entropy loss。

這里,tf.nn.softmax_cross_entropy_with_logits是一個方便的函數,計算每個類的交叉熵損失,給定我們的分數和正確的輸入標簽。 然后求損失的平均值。 我們也可以使用總和,但這比較難以比較不同批量大小和訓練/測試集數據的損失。
我們還為精度定義一個表達式,這是在訓練和測試期間跟蹤的有用數值。

TensorFlow可以看到其結構圖如下:
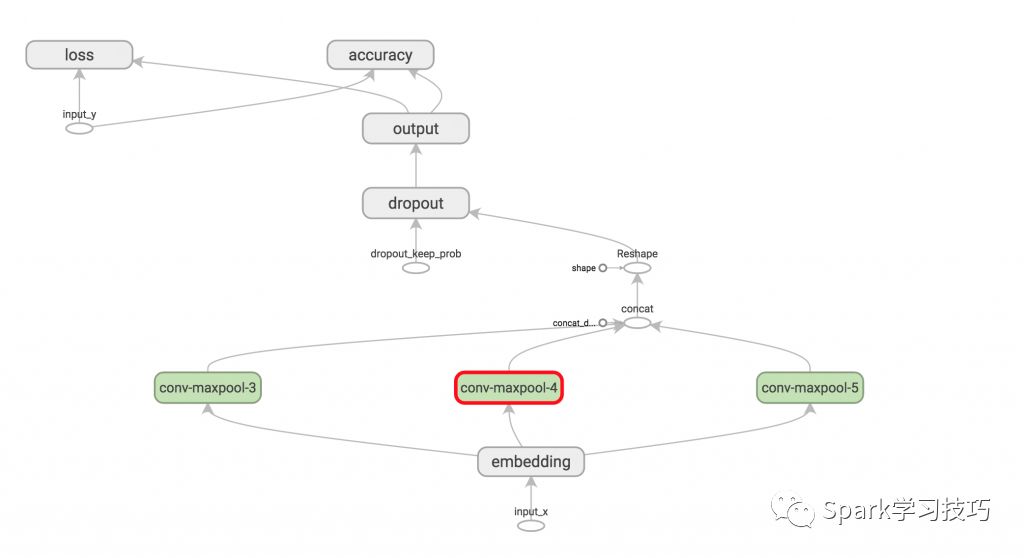
在我們為網絡定義訓練程序之前,我們需要了解一些關于TensorFlow如何使用Sessions和Graphs的基礎知識。如果您已經熟悉這些概念,請隨時跳過本節。
在TensorFlow中, Session是正在執行graph 操作的環境,它包含有關變量和隊列的狀態。每個 Session都在單個graph上運行。如果在創建變量和操作時未明確使用 Session,則使用TensorFlow創建的當前默認 Session。您可以通過在session.as_default()塊中執行命令來更改默認 Session(見下文)。
Graph包含操作和張量。您可以在程序中使用多個Graph,但大多數程序只需要一個Graph。您可以在多個 Session中使用相同的Graph,但在一個 Session中不能使用多Graph。 TensorFlow始終創建一個默認Graph,但您也可以手動創建一個Graph,并將其設置為新的默認Graph,如下圖所示。顯式創建 Session和Graph可確保在不再需要資源時正確釋放資源。
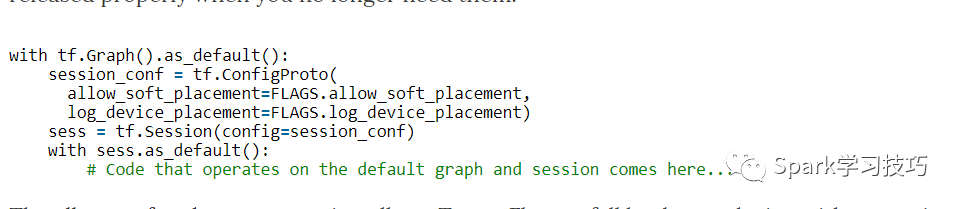
當優選設備不存在時,allow_soft_placement設置允許TensorFlow回退到具有特定操作的設備上。 例如,如果我們的代碼在GPU上放置一個操作,并且我們在沒有GPU的機器上運行代碼,則不使用allow_soft_placement將導致錯誤。 如果設置了log_device_placement,TensorFlow會登錄那些設備(CPU或GPU)進行操作。 這對調試非常有用。 標記是我們程序的命令行參數。
當我們實例化我們的TextCNN模型時,所有定義的變量和操作將被放置在上面創建的默認圖和會話中。

接下來,我們定義如何優化網絡的損失函數。 TensorFlow有幾個內置優化器。 我們正在使用Adam優化器。

在這里,train_op這里是一個新創建的操作,我們可以運行它們來對我們的參數執行更新。 train_op的每次執行都是一個訓練步驟。 TensorFlow自動計算哪些變量是“可訓練的”并計算它們的梯度。 通過定義一個global_step變量并將其傳遞給優化器,讓TensorFlow對訓練步驟進行計數。 每次執行train_op時,global step 將自動遞增1。
TensorFlow有一個概述(summaries),可以在訓練和評估過程中跟蹤和查看各種數值。 例如,您可能希望跟蹤您的損失和準確性隨時間的變化。您還可以跟蹤更復雜的數值,例如圖層激活的直方圖。 summaries是序列化對象,并使用SummaryWriter寫入磁盤。
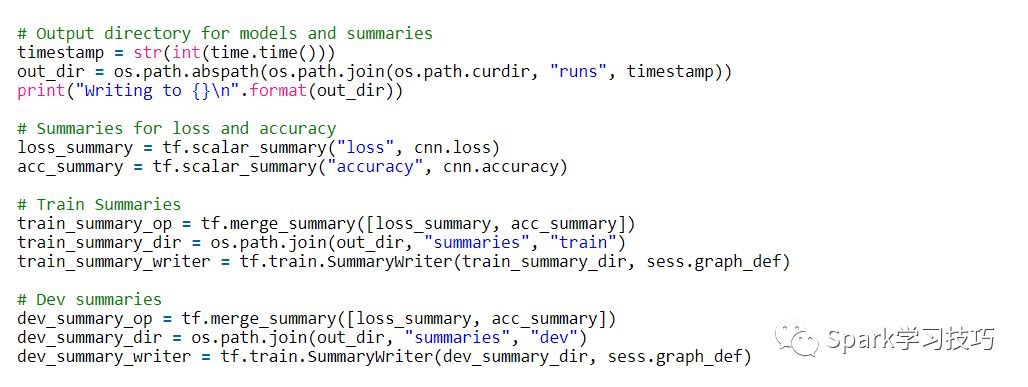
在這里,我們分別跟蹤培訓和評估的總結。 在我們的情況下,這些數值是相同的,但是您可能只有在訓練過程中跟蹤的數值(如參數更新值)。 tf.merge_summary是將多個摘要操作合并到可以執行的單個操作中的便利函數。
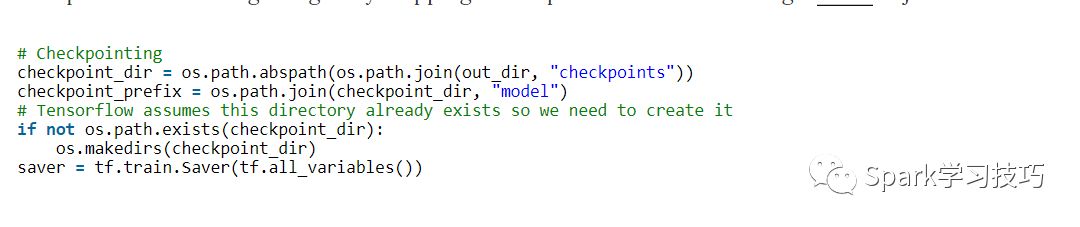
通常使用TensorFlow的另一個功能是checkpointing- 保存模型的參數以便稍后恢復。Checkpoints 可用于在以后的時間繼續訓練,或使用 early stopping選擇最佳參數設置。 使用Saver對象創建 Checkpoints。
在訓練模型之前,我們還需要在圖中初始化變量。
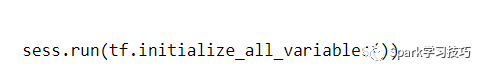
global_variables_initializer函數是一個方便函數,它運行我們為變量定義的所有初始值。也可以手動調用變量的初始化程序。 如果希望使用預先訓練的值初始化嵌入,這很有用。
現在我們來定義一個訓練步驟的函數,評估一批數據上的模型并更新模型參數。
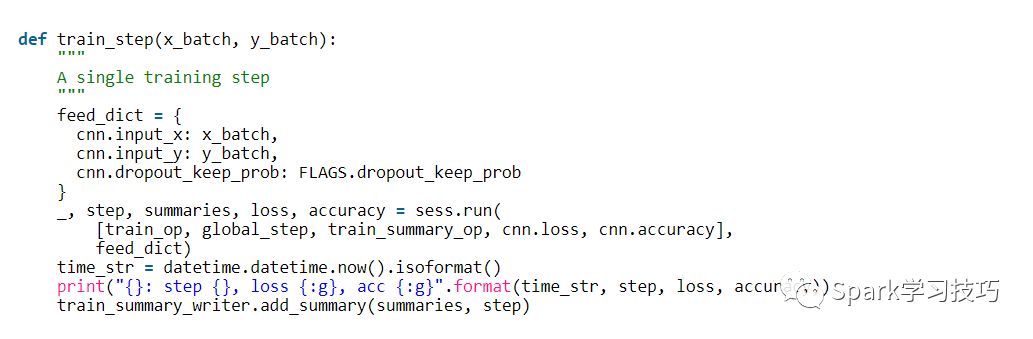
feed_dict包含我們傳遞到我們網絡的占位符節點的數據。您必須為所有占位符節點提供值,否則TensorFlow將拋出錯誤。使用輸入數據的另一種方法是使用隊列,但這超出了這篇文章的范圍。
接下來,我們使用session.run執行我們的train_op,它返回我們要求它進行評估的所有操作的值。請注意,train_op什么都不返回,它只是更新我們網絡的參數。最后,我們打印當前培訓批次的丟失和準確性,并將摘要保存到磁盤。請注意,如果批量太小,訓練批次的損失和準確性可能會在批次間顯著變化。而且因為我們使用dropout,您的訓練指標可能開始比您的評估指標更糟。
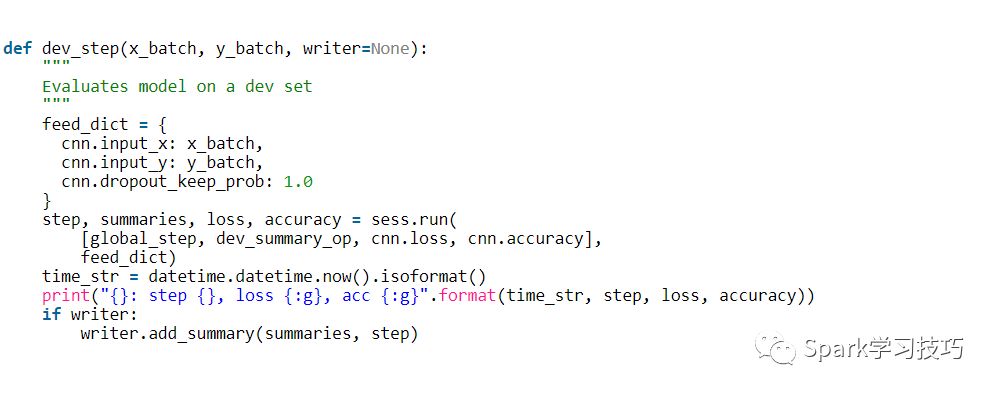
我們寫一個類似的函數來評估任意數據集的丟失和準確性,例如驗證集或整個訓練集。本質上這個功能與上述相同,但沒有訓練操作。它也禁用退出。
最后,準備編寫訓練循環。 迭代數據的批次,調用每個批次的train_step函數,偶爾評估和檢查我們的模型:
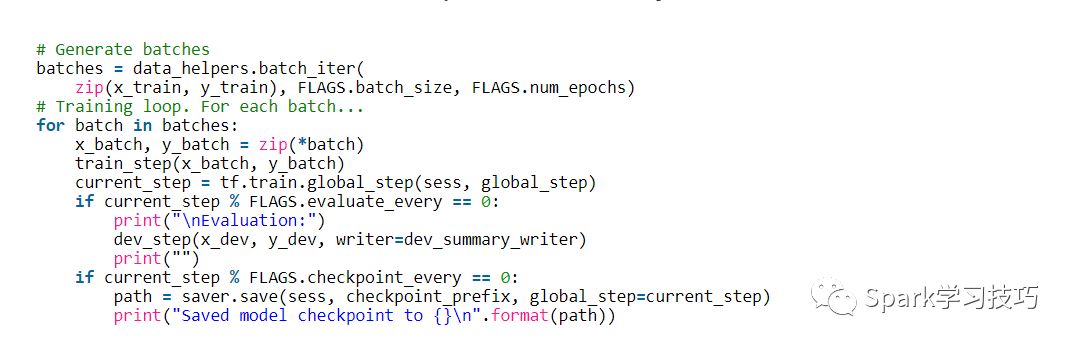
這里,batch_iter是一個批處理數據的幫助函數,而tf.train.global_step是返回global_step值的便利函數。
我們的訓練腳本將summaries寫入輸出目錄,并將TensorBoard指向該目錄,我們可以將圖和我們創建的summaries可視化。
有幾件事情脫穎而出:
我們的訓練指標并不平滑,因為我們使用小批量。 如果我們使用較大的批次(或在整個訓練集上評估),我們會得到一個更平滑的藍線。
因為測試者的準確性顯著低于訓練準確度,我們的網絡在訓練數據似乎過擬合了,這表明我們需要更多的數據(MR數據集非常小),更強的正則化或更少的模型參數。 例如,我嘗試在最后一層為重量添加額外的L2正則,并且能夠將準確度提高到76%,接近于原始文獻。
因為使用了dropout,訓練損失和準確性開始大大低于測試指標。
您可以使用代碼進行操作,并嘗試使用各種參數配置運行模型。 Github提供了代碼和說明。
以下是一些的練習,可以提高模型的性能:
使用預先訓練的word2vec向量初始化嵌入。 為了能夠起作用,您需要使用300維嵌入,并用預先訓練的值初始化它們。
限制最后一層權重向量的L2范數,就像原始文獻一樣。 您可以通過定義一個新的操作,在每次訓練步驟之后更新權重值。
將L2正規化添加到網絡以防止過擬合,同時也提高dropout比率。 (Github上的代碼已經包括L2正則化,但默認情況下禁用)
添加權重更新和圖層操作的直方圖summaries,并在TensorBoard中進行可視化。
看完上述內容,你們對Tensorflow中怎么實現CNN文本分類有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





