溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關python中怎么實現抽樣分類方法,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
在實踐之前你并不知道哪種算法對你的的數據效果最好。 你需要嘗試用不同的算法去實踐, 然后知道下一步的方向。 這就是我說的算法抽查。
兩種線性算法
邏輯回歸
線性判別分析 非線性機器學習算法
K近鄰算法
樸素貝葉斯。
分類和回歸樹 - CART 是決策樹的一種
支持向量機
有個問題, 什么叫線性, 什么叫非線性?
其實一般的書里面, 并不是這么分類的。 這里可能為了突出線性的重要性。 算法分為線性和非線性。 線性呢, 比如邏輯回歸, LDA。
名字里是回歸, 其實是一種分類方法。
邏輯回歸是一般的線性回歸加了一個sigmoid函數, 于是取值從整個實數域到了-1 到 +1, 于是二分類就很容易理解了, 大于零一種, 小于零一種。
邏輯回歸要求
假設高斯分布
數字的輸入變量
二分類問題:
如果有時間, 應該把重要的機器學習方法再回顧一遍。 主要思想, 實例。 后面可以搞個單獨的系列
# Logistic Regression Classification from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression filename = 'pima-indians-diabetes.data.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(filename, names=names) array = dataframe.values X = array[:,0:8] Y = array[:,8] num_folds = 10 kfold = KFold(n_splits=10, random_state=7) model = LogisticRegression() results = cross_val_score(model, X, Y, cv=kfold) print(results.mean()) # 0.76951469583
LDA 是一種統計技術對于二分類和多分類問題。
它也假設參數是高斯分布
# LDA Classification from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.discriminant_analysis import LinearDiscriminantAnalysis filename = 'pima-indians-diabetes.data.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(filename, names=names) array = dataframe.values X = array[:,0:8] Y = array[:,8] num_folds = 10 kfold = KFold(n_splits=10, random_state=7) model = LinearDiscriminantAnalysis() results = cross_val_score(model, X, Y, cv=kfold) print(results.mean()) # 0.773462064252
可以看到其實scikit learn 給我們做了很多的封裝, 調用過程都是一樣的, 沒有難度。 最簡單的就可以調用然后看效果。
k比鄰 是一種基于距離的度量。 找到k個最近的樣本對一個新的樣本, 然后取得平均值作為預測值。 這里k 的取得就可能有不同的效果。
如下
# KNN Classification from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.neighbors import KNeighborsClassifier filename = 'pima-indians-diabetes.data.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(filename, names=names) array = dataframe.values X = array[:,0:8] Y = array[:,8] num_folds = 10 kfold = KFold(n_splits=10, random_state=7) model = KNeighborsClassifier() results = cross_val_score(model, X, Y, cv=kfold) print(results.mean()) # 0.726555023923
首先 1) 沒有說明k 是多少, 應該有一個默認值, 找api應該可以看到。 2) k比鄰應該是很耗時的, 但是今天的實踐沒有反應, 原因應該是樣本過少。
樸素貝葉斯是基于貝葉斯理論的一種算法。 它有一個重要的假設, 就是每個變量是獨立分布的, 就是沒有關聯。 樸素貝葉斯計算每種參數的可能性以及每個類別的條件概率, 然后來估計新的數據并綜合計算。 這樣得到了新樣本的估計。
假設也是高斯分布, 就可以用高斯分布的密度函數
突然想到, 在實踐中, 是可以PCA 來得到彼此正交的參數, 然后來用樸素貝葉斯是否效果更好??
# Gaussian Naive Bayes Classification from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.naive_bayes import GaussianNB filename = 'pima-indians-diabetes.data.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(filename, names=names) array = dataframe.values X = array[:,0:8] Y = array[:,8] kfold = KFold(n_splits=10, random_state=7) model = GaussianNB() results = cross_val_score(model, X, Y, cv=kfold) print(results.mean()) # 0.75517771702
決策樹有幾種, 比如 CART, C4.5 決策樹呢基本的想法是遍歷所有特征, 對第一個特征做分類, 然后在每個分支根據第二個分類, 繼續。 知道所有的樣本分類相同, 或者特征用完了。
這里有個問題, 如何選擇第一個分類,有gini法, 最大熵等幾種辦法,選擇合適的特征順序, 構建的決策樹效率更高。
它的缺點, 然后對于離異點會非常敏感, 這個要小心。
當然, 后期的隨機森林, 以及boosting 等做法很多基于決策樹來做, 而且起到了很好的分類效果, 這是后話。
# CART Classification from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.tree import DecisionTreeClassifier filename = 'pima-indians-diabetes.data.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(filename, names=names) array = dataframe.values X = array[:,0:8] Y = array[:,8] kfold = KFold(n_splits=10, random_state=7) model = DecisionTreeClassifier() results = cross_val_score(model, X, Y, cv=kfold) print(results.mean()) # 0.697795625427
支撐向量機, 我感覺這是基本機器學習算法中最復雜的一個。
它的主要思想呢, 就是找到一個切平面可以來區分不同的類別。 - 其實就是二分類。
那么問題來了, 如果平面不能分開呢, 可以引申到多個維度
還有維度如果過高呢, 這里就是核函數的用武之地了。 它可以來解決維度過高的問題, 過高的維度, 甚至無限維對計算是不利的。
在上面這個思想下, SVM 是為了找到距離兩邊的樣本最遠的線, 或者平面。
對于奇異點, 它又增加了一個c, 作為容錯。
對于SVM, 基本思路可能不復雜, 但是推導過程還是不簡單的。 詳情見jly的博客, 當然它是基于幾個牛人的理解。 后面有機會也可以寫以下。
然后對于實踐而言, 有幾個點
核函數的選擇。 高斯, 還是別的
幾個參數的調優。 這個后面也應該又討論。
# SVM Classification from pandas import read_csv from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.svm import SVC filename = 'pima-indians-diabetes.data.csv' names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class'] dataframe = read_csv(filename, names=names) array = dataframe.values X = array[:,0:8] Y = array[:,8] kfold = KFold(n_splits=10, random_state=7) model = SVC() results = cross_val_score(model, X, Y, cv=kfold) print(results.mean()) ## 0.651025290499
本章學習如何用幾種分類算法做抽樣。 下一章是關于回歸的。
這個很容易理解, 拿出來結果比較以下即可。 看代碼
# Compare Algorithms
from pandas import read_csv
from matplotlib import pyplot
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
# load dataset
filename = 'pima-indians-diabetes.data.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
dataframe = read_csv(filename, names=names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
# prepare models
models = []
models.append(('LR', LogisticRegression()))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC()))
# evaluate each model in turn
results = []
names = []
scoring = 'accuracy'
for name, model in models:
kfold = KFold(n_splits=10, random_state=7)
cv_results = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std())
print(msg)
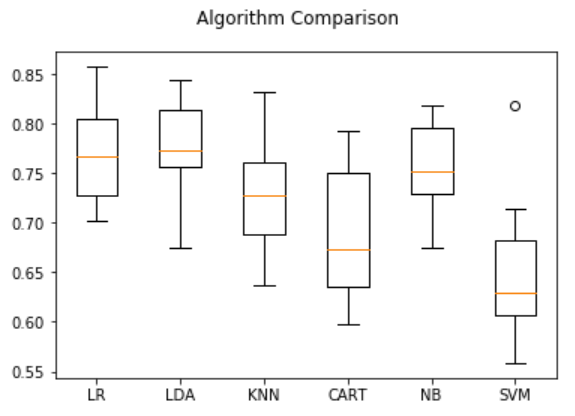
# boxplot algorithm comparison
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(names)
pyplot.show()result
LR: 0.769515 (0.048411) LDA: 0.773462 (0.051592) KNN: 0.726555 (0.061821) CART: 0.691302 (0.069249) NB: 0.755178 (0.042766) SVM: 0.651025 (0.072141)
上述就是小編為大家分享的python中怎么實現抽樣分類方法了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





