溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“VXLAN協議的原理介紹”,在日常操作中,相信很多人在VXLAN協議的原理介紹問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”VXLAN協議的原理介紹”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
VXLAN(Virtual eXtensible Local Area Network,虛擬可擴展局域網),是一種虛擬化隧道通信技術。它是一種 Overlay(覆蓋網絡)技術,通過三層的網絡來搭建虛擬的二層網絡。
簡單來講,VXLAN 是在底層物理網絡(underlay)之上使用隧道技術,借助 UDP 層構建的 Overlay 的邏輯網絡,使邏輯網絡與物理網絡解耦,實現靈活的組網需求。它對原有的網絡架構幾乎沒有影響,不需要對原網絡做任何改動,即可架設一層新的網絡。也正是因為這個特性,很多 CNI 插件(Kubernetes 集群中的容器網絡接口,這個大家應該都知道了吧,如果你不知道,現在你知道了)才會選擇 VXLAN 作為通信網絡。
VXLAN 不僅支持一對一,也支持一對多,一個 VXLAN 設備能通過像網橋一樣的學習方式學習到其他對端的 IP 地址,還可以直接配置靜態轉發表。
一個典型的數據中心 VXLAN 網絡拓撲圖如圖所示:
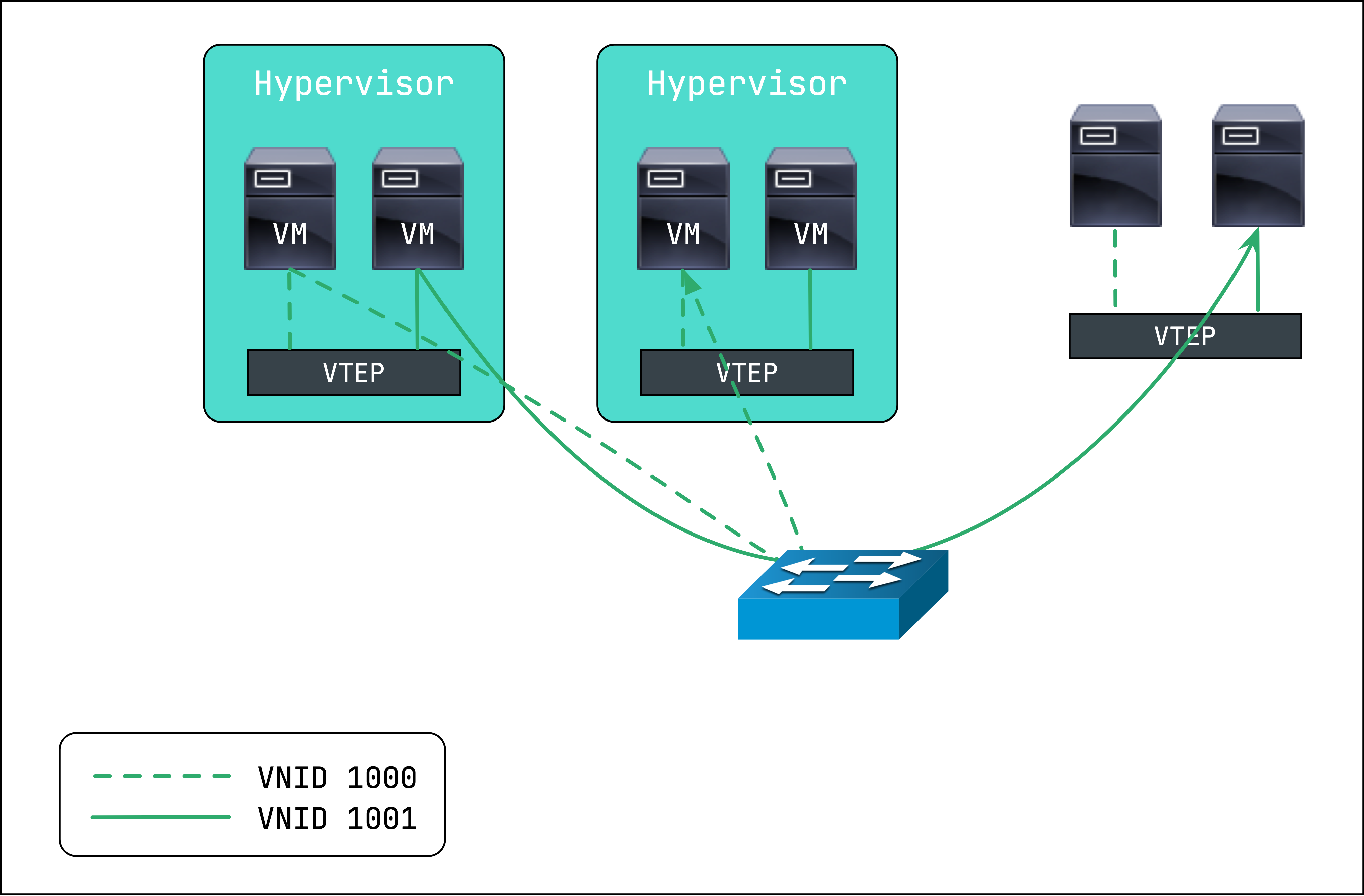
其中 VM 指的是虛擬機,Hypervisor 指的是虛擬化管理器。
與 VLAN 相比,VXLAN 很明顯要復雜很多,再加上 VLAN 的先發優勢,已經得到了廣泛的支持,那還要 VXLAN 干啥?
VLAN tag 總共有 4 個字節,其中有 12 bit 用來標識不同的二層網絡(即 LAN ID),故而最多只能支持 $2^{12}$,即 4096 個子網的劃分。而虛擬化(虛擬機和容器)的興起使得一個數據中心會有成千上萬的機器需要通信,這時候 VLAN 就無法滿足需求了。而 VXLAN 的報文 Header 預留了 24 bit 來標識不同的二層網絡(即 VNI,VXLAN Network Identifier),即 3 個字節,可以支持 $2^{24}$ 個子網。
對于同網段主機的通信而言,報文到底交換機后都會查詢 MAC 地址表進行二層轉發。數據中心虛擬化之后,VM 的數量與原有的物理機相比呈數量級增長,而應用容器化之后,容器與 VM 相比也是呈數量級增長。。。而交換機的內存是有限的,因而 MAC 地址表也是有限的,隨著虛擬機(或容器)網卡 MAC 地址數量的空前增加,交換機表示壓力山大啊!
而 VXLAN 就厲害了,它用 VTEP(后面會解釋)將二層以太網幀封裝在 UDP 中,一個 VTEP 可以被一個物理機上的所有 VM(或容器)共用,一個物理機對應一個 VTEP。從交換機的角度來看,只是不同的 VTEP 之間在傳遞 UDP 數據,只需要記錄與物理機數量相當的 MAC 地址表條目就可以了,一切又回到了和從前一樣。
VLAN 與物理網絡融合在一起,不存在 Overlay 網絡,帶來的問題就是虛擬網絡不能打破物理網絡的限制。舉個例子,如果要在 VLAN 100 部署虛擬機(或容器),那只能在支持 VLAN 100 的物理設備上部署。
VLAN 其實也有解決辦法,就是將所有的交換機 Trunk 連接起來,產生一個大的二層,這樣帶來的問題就是廣播域過分擴大,也包括更多未知的單播和多播,即 BUM(Broadcast,Unknown Unicast,Multicast),同時交換機 MAC 地址表也會有承受不住的問題。
而 VXLAN 將二層以太網幀封裝在 UDP 中(上面說過了),相當于在三層網絡上構建了二層網絡。這樣不管你物理網絡是二層還是三層,都不影響虛擬機(或容器)的網絡通信,也就無所謂部署在哪臺物理設備上了,可以隨意遷移。
總的來說,傳統二層和三層的網絡在應對這些需求時變得力不從心,雖然很多改進型的技術比如堆疊、SVF、TRILL 等能夠增加二層的范圍,努力改進經典網絡,但是要做到對網絡改動盡可能小的同時保證靈活性卻非常困難。為了解決這些問題,有很多方案被提出來,Overlay 就是其中之一,而 VXLAN 是 Overlay 的一種典型的技術方案。下面就對 Overlay 做一個簡要的介紹。
Overlay 在網絡技術領域,指的是一種網絡架構上疊加的虛擬化技術模式,其大體框架是對基礎網絡不進行大規模修改的條件下,實現應用在網絡上的承載,并能與其它網絡業務分離,并且以基于 IP 的基礎網絡技術為主。
IETF 在 Overlay 技術領域提出 VXLAN、NVGRE、STT 三大技術方案。大體思路均是將以太網報文承載到某種隧道層面,差異性在于選擇和構造隧道的不同,而底層均是 IP 轉發。VXLAN 和 STT 對于現網設備而言對流量均衡要求較低,即負載鏈路負載分擔適應性好,一般的網絡設備都能對 L2-L4 的數據內容參數進行鏈路聚合或等價路由的流量均衡,而 NVGRE 則需要網絡設備對 GRE 擴展頭感知并對 flow ID 進行 HASH,需要硬件升級;STT 對于 TCP 有較大修改,隧道模式接近 UDP 性質,隧道構造技術屬于革新性,且復雜度較高,而 VXLAN 利用了現有通用的 UDP 傳輸,成熟性極高。
總體比較,VLXAN 技術具有更大優勢,而且當前 VLXAN 也得到了更多廠家和客戶的支持,已經成為 Overlay 技術的主流標準。
VXLAN 有幾個常見的術語:
VTEP(VXLAN Tunnel Endpoints,VXLAN 隧道端點)
VXLAN 網絡的邊緣設備,用來進行 VXLAN 報文的處理(封包和解包)。VTEP 可以是網絡設備(比如交換機),也可以是一臺機器(比如虛擬化集群中的宿主機)。
VNI(VXLAN Network Identifier,VXLAN 網絡標識符)
VNI 是每個 VXLAN 段的標識,是個 24 位整數,一共有 $2^{24} = 16777216$(一千多萬),一般每個 VNI 對應一個租戶,也就是說使用 VXLAN 搭建的公有云可以理論上可以支撐千萬級別的租戶。
Tunnel(VXLAN 隧道)
隧道是一個邏輯上的概念,在 VXLAN 模型中并沒有具體的物理實體向對應。隧道可以看做是一種虛擬通道,VXLAN 通信雙方認為自己是在直接通信,并不知道底層網絡的存在。從整體來說,每個 VXLAN 網絡像是為通信的虛擬機搭建了一個單獨的通信通道,也就是隧道。
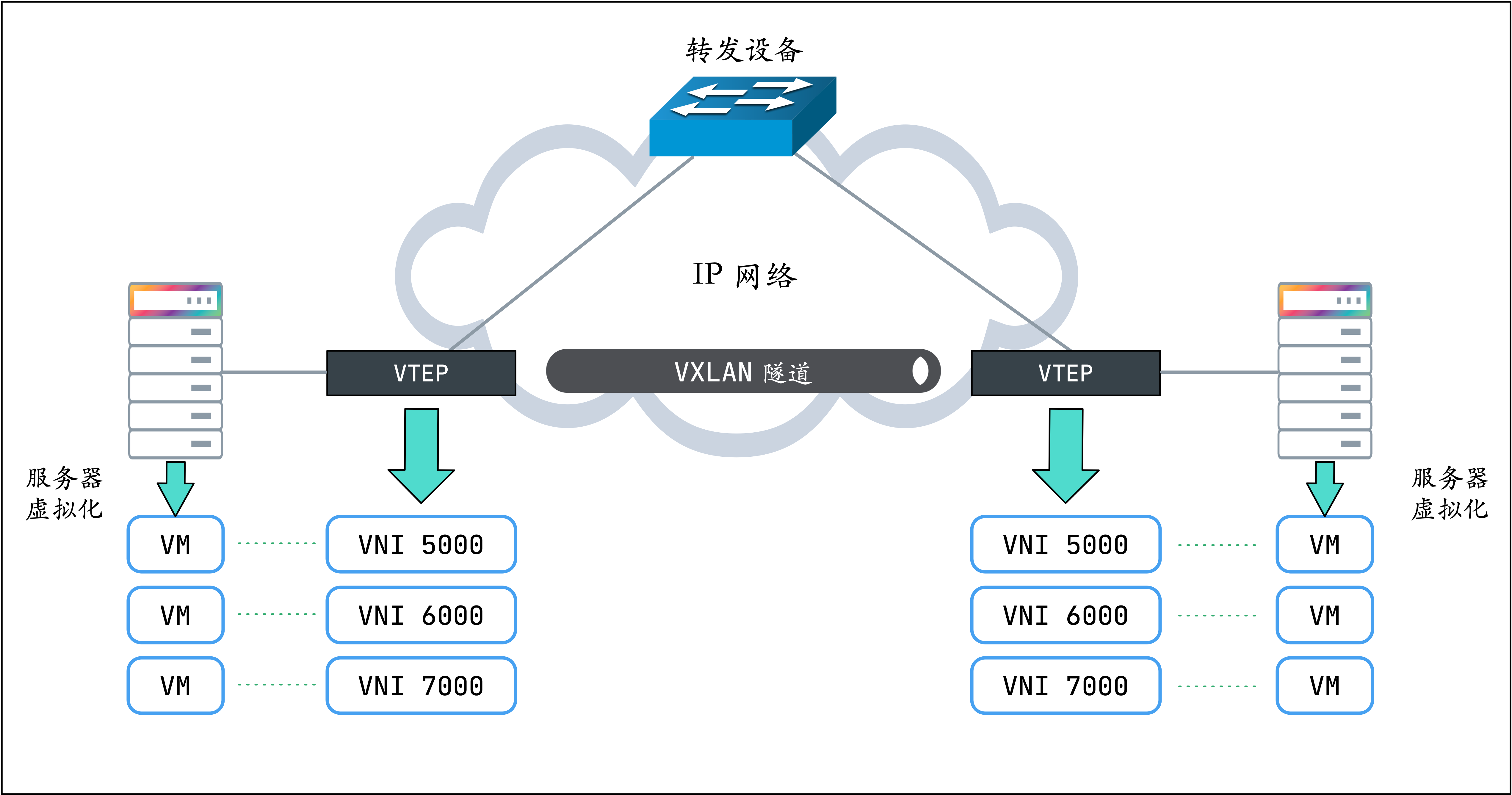
上圖所示為 VXLAN 的工作模型,它創建在原來的 IP 網絡(三層)上,只要是三層可達(能夠通過 IP 相互通信)的網絡就能部署 VXLAN。在 VXLAN 網絡的每個端點都有一個 VTEP 設備,負責 VXLAN 協議報文的解包和封包,也就是在虛擬報文上封裝 VTEP 通信的報文頭部。
物理網絡上可以創建多個 VXLAN 網絡,可以將這些 VXLAN 網絡看成一個隧道,不同節點上的虛擬機/容器能夠通過隧道直連。通過 VNI 標識不同的 VXLAN 網絡,使得不同的 VXLAN 可以相互隔離。
VXLAN 的報文結構如下圖所示:
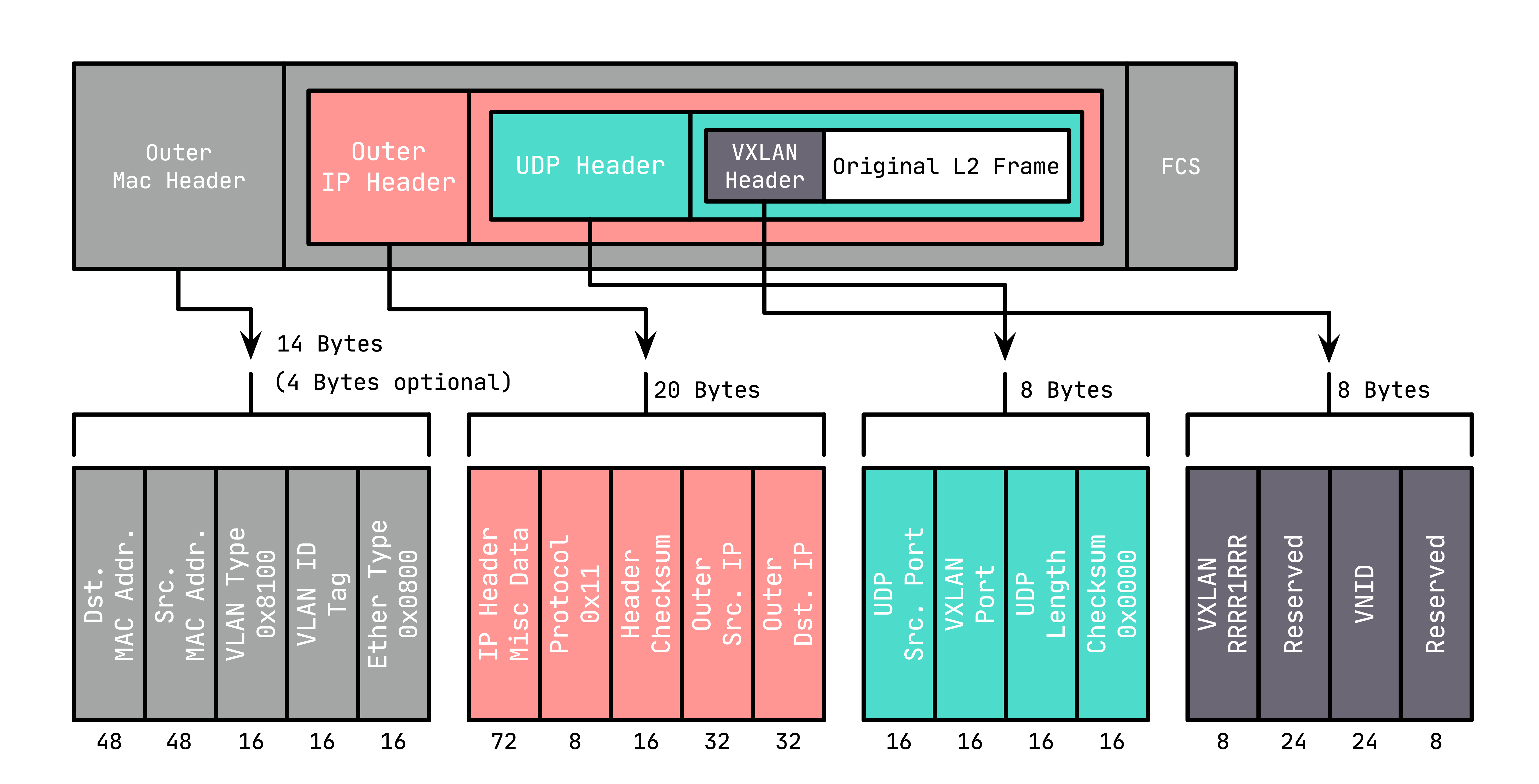
VXLAN Header : 在原始二層幀的前面增加 8 字節的 VXLAN 的頭部,其中最主要的是 VNID,占用 3 個字節(即 24 bit),類似 VLAN ID,可以具有 $2^{24}$ 個網段。
UDP Header : 在 VXLAN 和原始二層幀的前面使用 8 字節 UDP 頭部進行封裝(MAC IN UDP),目的端口號缺省使用 4789,源端口按流隨機分配(通過 MAC,IP,四層端口號進行 hash 操作), 這樣可以更好的做 ECMP。
IANA(Internet As-signed Numbers Autority)分配了4789作為 VXLAN 的默認目的端口號。
在上面添加的二層封裝之后,再添加底層網絡的 IP 頭部(20 字節)和 MAC 頭部(14 字節),這里的 IP 和 MAC 是宿主機的 IP 地址和 MAC 地址。
同時,這里需要注意 MTU 的問題,傳統網絡 MTU 一般為 1500,這里加上 VXLAN 的封裝多出的(36+14/18,對于 14 的情況為 access 口,省去了 4 字節的 VLAN Tag)50 或 54 字節,需要調整 MTU 為 1550 或 1554,防止頻繁分包。

總的來說,VXLAN 報文的轉發過程就是:原始報文經過 VTEP,被 Linux 內核添加上 VXLAN 頭部以及外層的 UDP 頭部,再發送出去,對端 VTEP 接收到 VXLAN 報文后拆除外層 UDP 頭部,并根據 VXLAN 頭部的 VNI 把原始報文發送到目的服務器。但這里有一個問題,第一次通信前雙方如何知道所有的通信信息?這些信息包括:
哪些 VTEP 需要加到一個相同的 VNI 組?
發送方如何知道對方的 MAC 地址?
如何知道目的服務器在哪個節點上(即目的 VTEP 的地址)?
第一個問題簡單,VTEP 通常由網絡管理員來配置。要回答后面兩個問題,還得回到 VXLAN 協議的報文上,看看一個完整的 VXLAN 報文需要哪些信息:
內層報文 : 通信雙方的 IP 地址已經明確,只需要 VXLAN 填充對方的 MAC 地址,因此需要一個機制來實現 ARP 功能。
VXLAN 頭部 : 只需要知道 VNI。一般直接配置在 VTEP 上,要么提前規劃,要么根據內層報文自動生成。
UDP 頭部 : 需要知道源端口和目的端口,源端口由系統自動生成,目的端口默認是 4789。
IP 頭部 : 需要知道對端 VTEP 的 IP 地址,這個是最關鍵的部分。
實際上,VTEP 也會有自己的轉發表,轉發表通過泛洪和學習機制來維護,對于目標 MAC 地址在轉發表中不存在的未知單播,廣播流量,都會被泛洪給除源 VTEP 外所有的 VTEP,目標 VTEP 響應數據包后,源 VTEP 會從數據包中學習到 MAC,VNI 和 VTEP 的映射關系,并添加到轉發表中,后續當再有數據包轉發到這個 MAC 地址時,VTEP 會從轉發表中直接獲取到目標 VTEP 地址,從而發送單播數據到目標 VTEP。
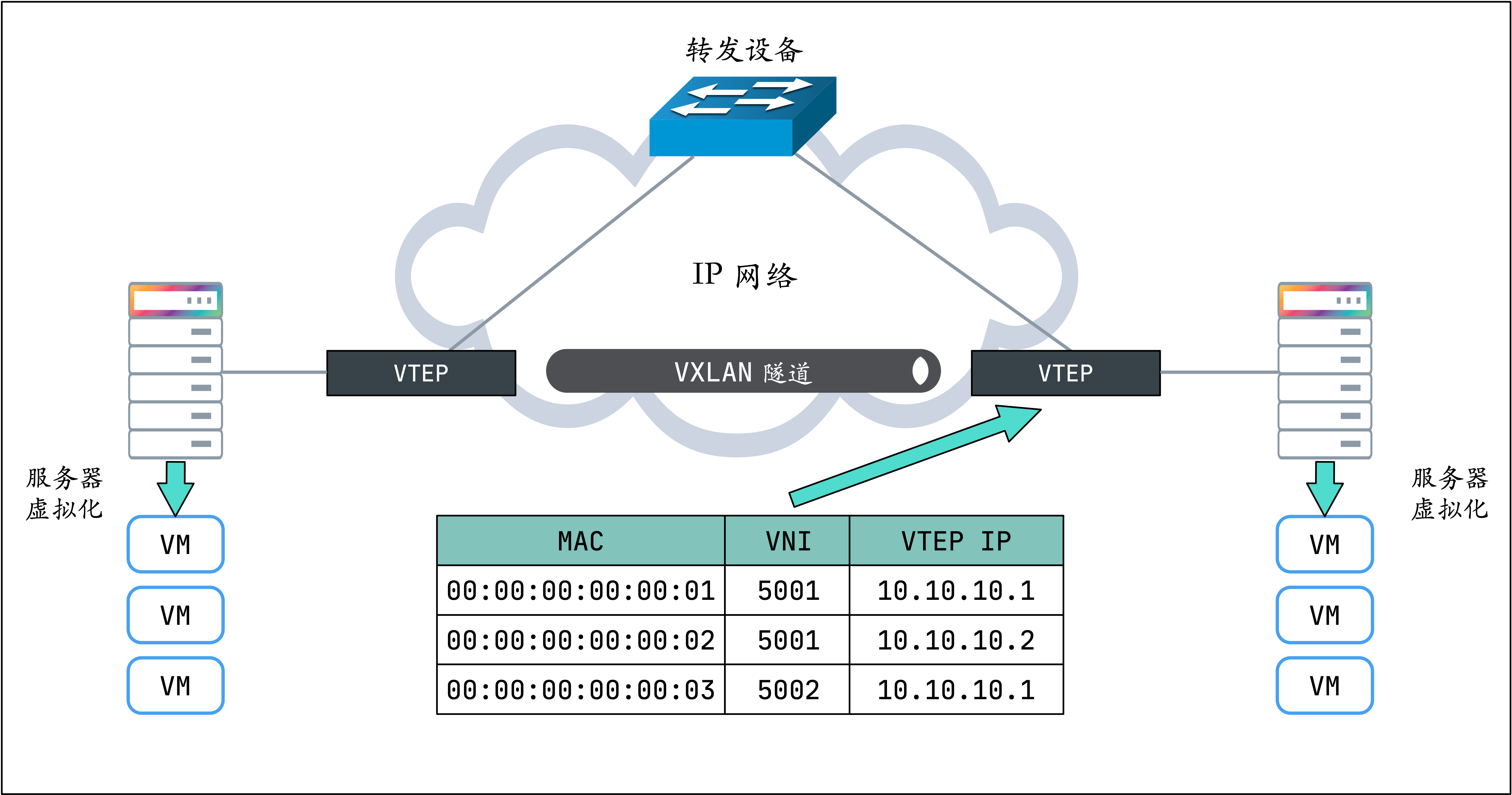
VTEP 轉發表的學習可以通過以下兩種方式:
多播
外部控制中心(如 Flannel、Cilium 等 CNI 插件)
MAC 頭部 : 確定了 VTEP 的 IP 地址,后面就好辦了,MAC 地址可以通過經典的 ARP 方式獲取。
Linux 對 VXLAN 協議的支持時間并不久,2012 年 Stephen Hemminger 才把相關的工作合并到 kernel 中,并最終出現在 kernel 3.7.0 版本。為了穩定性和很多的功能,可能會看到某些軟件推薦在 3.9.0 或者 3.10.0 以后版本的 kernel 上使用 VXLAN。
到了 kernel 3.12 版本,Linux 對 VXLAN 的支持已經完備,支持單播和組播,IPv4 和 IPv6。利用 man 查看 ip 的 link 子命令,可以查看是否有 VXLAN type:
$ man ip-link
搜索 VXLAN,可以看到如下描述:

Linux VXLAN 接口的基本管理如下:
創建點對點的 VXLAN 接口:
$ ip link add vxlan0 type vxlan id 4100 remote 192.168.1.101 local 192.168.1.100 dstport 4789 dev eth0
其中 id 為 VNI,remote 為遠端主機的 IP,local 為你本地主機的 IP,dev 代表 VXLAN 數據從哪個接口傳輸。
在 VXLAN 中,一般將 VXLAN 接口(本例中即 vxlan0)叫做 VTEP。
創建多播模式的 VXLAN 接口:
$ ip link add vxlan0 type vxlan id 4100 group 224.1.1.1 dstport 4789 dev eth0
多播組主要通過 ARP 泛洪來學習 MAC 地址,即在 VXLAN 子網內廣播 ARP 請求,然后對應節點進行響應。group 指定多播組的地址。
查看 VXLAN 接口詳細信息:
$ ip -d link show vxlan0
FDB(Forwarding Database entry,即轉發表)是 Linux 網橋維護的一個二層轉發表,用于保存遠端虛擬機/容器的 MAC地址,遠端 VTEP IP,以及 VNI 的映射關系,可以通過 bridge fdb 命令來對 FDB 表進行操作:
條目添加:
$ bridge fdb add <remote_host_mac> dev <vxlan_interface> dst <remote_host_ip>
條目刪除:
$ bridge fdb del <remote_host_mac> dev <vxlan_interface>
條目更新:
$ bridge fdb replace <remote_host_mac> dev <vxlan_interface> dst <remote_host_ip>
條目查詢:
$ bridge fdb show
到此,關于“VXLAN協議的原理介紹”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





