溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
HDFS主要用于最初由Yahoo提出的分布式文件系統,以下它的主要用途:
1、保存大數據
2、提供快速讀取大數據的能力
Heroop幀的主要特征是通過將數據和計算分布在集群中的各節點服務器來實現分布式計算的目的。在計算邏輯和所需數據接近這一點上,并行計算分區后進行匯總。
基本模塊
HDFS分離保存Meta數據和用戶數據。Meta的數據被保存在Namicos中,用戶數據被保存在Datan路徑中。服務器之間的通信基于TCP協議。
與GFS(Google File System)同樣,從可靠性的考慮出發,具有將文件的內容復制到多個Datao,之后將數據的復制復制到多個Datannampa的目的和優點。
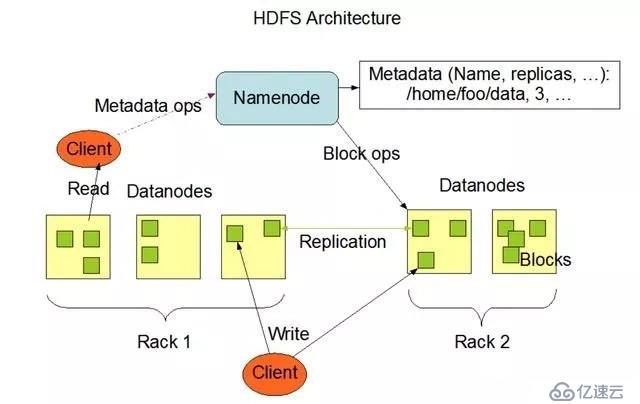
1、 Namamos
Namelos是HDFS的重要點,它保存了HDFS文件系統命名的空間樹,文件和路徑在Nameos中用inpoes顯示。在HDFS系統中,文件的內容被分割為大的block(例如128 Mbytes,根據用戶的需求被配置),各block獨立復制到多個Data南徑中。Namicos將各文件的各個block的復印件存儲在Datanpase的物理位置。
HDFS cial讀HDFS的過程。
讀:當讀HDFS保存的某些文件時,首先對Nameos,當Nameos返回該文件的block的Datan路徑的位置時,可以從最近的Datao讀取數據。
寫:cial在寫文件時,對Namelos的要求,Namicos將Datao寫的位置返回(多個,例如3個Datao),對它要求直接的Datannampas,寫入文件block。每個block,例如寫三個Data號碼路徑,多確保文件block。
如何使用pporela方式寫入數據,簡單來說,將一個Datao的第一Datao數據復制到第二Datao,將第二Datao的數據復制到第三Datapass。
這里有幾個概念:
很多小伙伴,對大數據的概念都是模糊不清的,大數據是什么,能做什么,學的時候,該按照什么線路去學習,學完往哪方面發展,想深入了解,想學習的同學歡迎加入大數據學習群:775908246,有大量干貨(零基礎以及進階的經典實戰)分享給大家,并且有清華大學畢業的資深大數據講師給大家免費授課,給大家分享目前國內最完整的大數據高端實戰實用學習流程體系。

2 、Datao
一個Datao上的block的拷貝由兩個文件表示,第一文件是數據的內容本身,第二個文件包括block meta的數據(包括文件checksm),生成時間。
當Datao啟動時,可以積極連接Namelos,驗證names ple ID和Datao的軟件版本。如果不符合Namelox,Datao會自動關閉。names psteID屬于在初始化文件系統的示例時分配的不同names p糾紛ID的節點。
在HANshake握手后,Datao通過登錄Namelos將Namicos的分配stor記ID(用于識別Datao)登錄到Datanmupas中。
Datao能夠通過Block rep報向Nameos發送登記時保存的block的復印信息。block rep報每1小時發送給Namicos,更新保存的復印信息。這樣的Namicos,知道各自的拷貝保存著哪個Dataman路徑。
如果Databs的周期性(譬如,每3秒),發送Namelox的消息的話,有Namicos10分以內沒領取Data號碼牌這樣的消息,我想這個Datao已經不能提供服務。上面的block的復印件也不能利用。
Holtbated消息是Datao a .總存儲器容量,b .使用的存儲器空間和c .當前傳輸的數據的數目,這些信息可以使用Nameos的空間分配和負載平衡。
因為Nameos沒有直接調整Data南徑,所以使用hittbal的回答發送命令。這些命令是:
3、 Image和Journal
在任何HDFS client發起的事務上,變化被記錄在journal上。checkpoint文件不會更改,它只會被新的checkpoint文件更新。如果checkpoint文件或journal文件丟失或損壞,命名空間信息就會部分或全部丟失,為了避免這種情況,HDFS可以通過配置將checkpoint和journal文件保存在不同的存儲路徑。
4、CheckpointNode和BackupNode
CheckpointNode周期性地將當前的checkpoint和journal組合產生新的checkpoint和一個空的journal。CheckpointNode往往運行在一個與NameNode不同的獨立的服務器上。
BackupNode類似CheckpointNode,也可以周期性地生成checkpoint,但除此之外,它還能夠在內存中保存一份與NameNode同步的image。active NameNode將journal的改動發送給BackupNode。
1、讀寫文件
HDFS實現的是多個讀取模型。
HDFS cial在創建文件之前可以獲取此文件的讀取器。其他沒有出租的cial無法寫入此文件。寫著操作的cial,如果對Namelos的更新關閉了文件,關閉契約。如果軟件過期,cial將被關閉或未更新租賃,其他cial將獲得租賃合同的權限。如果霍華德租賃期限到期(1小時)的話,HDFS租賃合同無法更新。
閱讀可以不受租賃機制影響,并且多個客戶端可以并行讀取該文件。
2、block分布
相同block的不同復印的分布對于HDFS數據的可靠性,讀寫性能重要。默認策略如下:當一個新block創建時,HDFS將一個副本放在writer的所在地節點,第二個和第三個副本放在不同的機架不同的節點,其余更多副本放在另一個節點,原則:復印多個到同一個結點不能放置。兩個以上的復印件不能放在同一個機上。復印數比RK少2倍時。
在一般的網絡結構中,同一臺機器的節點使用一個交換機連接。同一機器的節點之間的網絡的帶寬往往變高。
總的說來:

3 、復印管理
Namicos確保所有block中指定的復印數。當Namelos接到Datao發出的block reping時,block的數量檢測高達-或over -指定的復印數。
如果超過了,Nameos刪除某個副本。
在低于指定的復印數目的情況下,該block具有復制優先順序,僅復印數有一個block具有最高的優先順序。有線程確定新復制在哪里創建。
Nameos必須確保所有復印件不在同一個書架上,如果所有的復印件都在同一個書架上,Nameos必須減少指定的復印件數,從而啟動復印。復印完成后,Nameos檢測復印數大于指定數目,刪除某個副本。通過復制-刪除和復制。
4、平衡器
平衡器用來平衡HDFS集群中節點的磁盤使用率。當某個節點的磁盤使用率大于集群平均使用率超過一定閾值,平衡器會將數據從高磁盤使用率的DataNode節點移動到低使用率的DataNode節點。平衡器會盡量減少跨機架的數據拷貝。
5、block掃描儀
所有Databs都用于檢測block的復印是否破損。另外,如果檢測到損壞,Namicos將會在該復印標記損壞的同時創建新的復印件,并在新復印成功后刪除損壞的復印件。
6、節點結束
集群管理員可以控制Datao的退出,Datao退出時,不會被選為復印的目的地。但仍然可以支持讀者。Nameos將所有block的復印件移到其他Datanpass。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





