溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Kafka 在 Yelp 的應用十分廣泛,Yelp 每天通過各種集群發送數十億條消息,在這背后,Kafka 使用 Zookeeper 完成各種分布式協調任務。
因為Yelp 非常依賴 Kafka,那么問題來了,它是否可以在不引起 Kafka 及其他 Zookeeper 用戶注意的情況下切換 Zookeeper 集群呢?本文將揭曉答案。
Kafka 在 Yelp 的應用十分廣泛。事實上,我們 每天通過各種集群發送數十億條消息。在這背后,Kafka 使用 Zookeeper 完成各種分布式協調任務,例如決定哪個 Kafka broker 負責分配分區首領,以及在 broker 中存儲有關主題的元數據。
Kafka 在 Yelp 的成功應用說明了我們的集群從其首次部署 Kafka 以來經歷了大幅的增長。與此同時,其他的 Zookeeper 重度用戶(例如 Smartstack 和 PaasTA)規模也在增長,給我們的共享 Zookeeper 集群添加了很多負擔。為了緩解這種情況,我們決定讓我們的 Kafka 集群使用專門的 Zookeeper 集群。
由于我們非常依賴 Kafka,因維護造成的任何停機都會導致連鎖反應,例如顯示給業務所有者的儀表盤出現延遲、日志堆積在服務器上。那么問題就來了:我們是否可以在不引起 Kafka 及其他 Zookeeper 用戶注意的情況下切換 Zookeeper 集群?
Zookeeper 有絲分裂
經過團隊間對 Kafka 和 Zookeeper 的幾輪討論和頭腦風暴之后,我們找到了一種方法,似乎可以實現我們的目標:在不會導致 Kafka 停機的情況下讓 Kafka 集群使用專門的 Zookeeper 集群。
我們提出的方案可以比作自然界的 細胞有絲分裂:我們復制 Zookeeper 主機(即 DNA),然后利用防火墻規則(即細胞壁)把復制好的主機分成兩個獨立的集群。

有絲分裂中的主要事件,染色體在細胞核中分裂
讓我們一步一步深入研究細節。在本文中,我們將會用到源集群和目標集群,源集群代表已經存在的集群,目標集群代表 Kafka 將要遷移到的新集群。我們要用到的示例是一個包含三個節點的 Zookeeper 集群,但這個過程本身可用于任何數量的節點。
我們的示例將為 Zookeeper 節點使用以下 IP 地址:
源 192.168.1.1-3
目標 192.168.1.4-6
第 1 階段:DNA 復制
首先,我們需要啟動一個新的 Zookeeper 集群。這個目標集群必須是空的,因為在遷移的過程中,目標集群中的內容將被刪除。
然后,我們將目標集群中的兩個節點和源集群中的三個節點組合在一起,得到一個包含五個節點的 Zookeeper 集群。這么做的原因是我們希望數據(最初由 Kafka 保存在源 Zookeeper 集群中)被復制到目標集群上。Zookeeper 的復制機制會自動執行復制過程。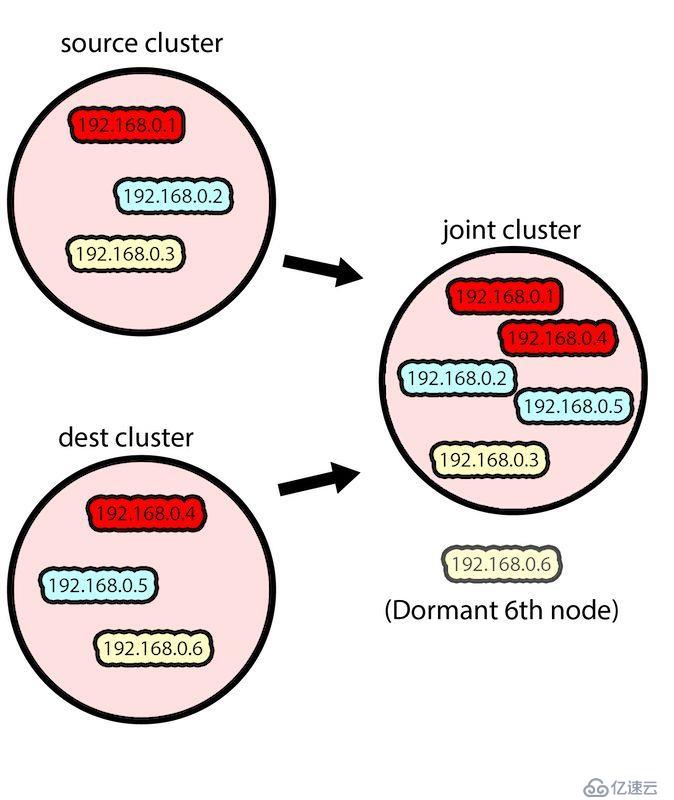
把來自源集群和目標集群的節點組合在一起
每個節點的 zoo.cfg 文件現在看起來都像下面這樣,包含源集群的所有節點和目標集群中的兩個節點:
server.1=192.168.1.1:2888:3888
server.2=192.168.1.2:2888:3888
server.3=192.168.1.3:2888:3888
server.4=192.168.1.4:2888:3888
server.5=192.168.1.5:2888:3888
注意,來自目標集群的一個節點(在上面的例子中是 192.168.1.6)在該過程中保持休眠狀態,沒有成為聯合集群的一部分,并且 Zookeeper 也沒有在其上運行,這是為了保持源集群的 quorum。
此時,聯合集群必須重啟。確保執行一次滾動重啟(每次重啟一個節點,期間至少有 10 秒的時間間隔),從來自目標集群的兩個節點開始。這個順序可以確保源集群的 quorum 不會丟失,并在新節點加入該集群時確保對其他客戶端(如 Kafka)的可用性。
Zookeeper 節點滾動重啟后,Kafka 對聯合集群中的新節點一無所知,因為它的 Zookeeper 連接字符串只有原始源集群的 IP 地址:
zookeeper.connect=192.168.1.1,192.168.1.2,192.168.1.3/kafka
發送給 Zookeeper 的數據現在被復制到新節點,而 Kafka 甚至都沒有注意到。
現在,源集群和目標集群之間的數據同步了,我們就可以更新 Kafka 的連接字符串,以指向目標集群:
zookeeper.connect=192.168.1.4,192.168.1.5,192.168.1.6/kafka
需要來一次 Kafka 滾動重啟,以獲取新連接,但不要進行整體停機。
第 2 階段:有絲分裂
拆分聯合集群的第一步是恢復原始源 Zookeeper 及目標 Zookeeper 的配置文件(zoo.cfg),因為它們反映了集群所需的最終狀態。注意,此時不應重啟 Zookeeper 服務。
我們利用防火墻規則來執行有絲分裂,把我們的聯合集群分成不同的源集群和目標集群,每個集群都有自己的首領。在我們的例子中,我們使用 iptables 來實現這一點,但其實可以兩個 Zookeeper 集群主機之間強制使用的防火墻系統應該都是可以的。
對每個目標節點,我們運行以下命令來添加 iptables 規則:
$source_node_list = 192.168.1.1,192.168.1.2,192.168.1.3
sudo /sbin/iptables -v -A INPUT -p tcp -d $source_node_list -j REJECT
sudo /sbin/iptables -v -A OUTPUT -p tcp -d $source_node_list -j REJECT
這將拒絕從目標節點到源節點的任何傳入或傳出 TCP 流量,從而實現兩個集群的分隔。
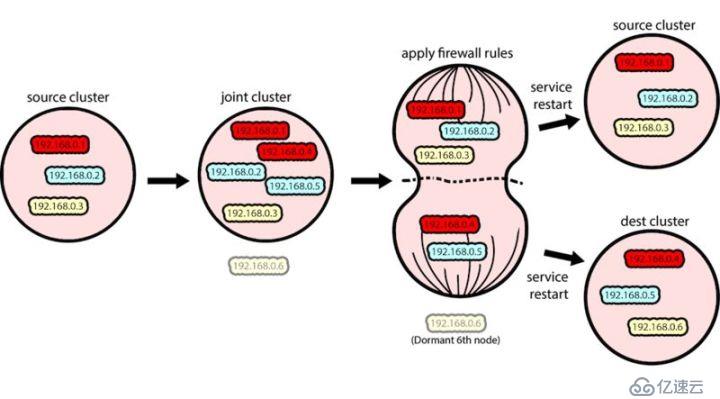
通過防火墻規則分隔源集群和目標集群,然后重啟
分隔意味著現在兩個目標節點與其他節點是分開的。因為它們認為自己屬于一個五節點的集群,而且無法與集群的大多數節點進行通信,所以它們無法進行首領選舉。
此時,我們同時重啟目標集群中每個節點的 Zookeeper,包括那個不屬于聯合集群的休眠節點。這樣 Zookeeper 進程將使用步驟 2 中提供的新配置,而且還會強制在目標集群中進行首領選舉,從而每個集群都會有自己的首領。
從 Kafka 的角度來看,目標集群從發生網絡分區那一刻起就不可用,直到首領選舉結束后才可用。對 Kafka 來說,這是整個過程中 Zookeeper 不可用的唯一一個時間段。從現在開始,我們有了兩個不同的 Zookeeper 集群。
現在我們要做的是清理。源集群仍然認為自己還有兩個額外的節點,我們需要清理一些防火墻規則。
接下來,我們重啟源集群,讓只包含原始源集群節點的 zoo.cfg 配置生效。我們現在可以安全地刪除防火墻規則,因為集群之間不再需要相互通信。下面的命令用于刪除 iptables 規則:
$source_node_list = 192.168.1.1,192.168.1.2,192.168.1.3
sudo /sbin/iptables -v -D INPUT -p tcp -d $source_node_list -j REJECT
sudo /sbin/iptables -v -D OUTPUT -p tcp -d $source_node_list -j REJECT
樹立信心分布式壓力測試
我們用于測試遷移過程正確性的主要方法是分布式壓力測試。在遷移過程中,我們通過腳本在多臺機器上運行數十個 Kafka 生產者和消費者實例。當流量生成完成后,所有被消費的數據有效載荷被聚集到單臺主機上,以便檢測是否發生數據丟失。
分布式壓力測試的工作原理是為 Kafka 生產者和消費者創建一組 Docker 容器,并在多臺主機上并行運行它們。所有生成的消息都包含了一個序列號,可以用于檢測是否發生消息丟失。
臨時集群
為了證明遷移的正確性,我們需要構建一些專門用于測試的集群。我們不是通過手動創建 Kafka 集群,然后在測試完以后再關掉它們,而是構建了一個工具,可以在我們的基礎架構上自動生成和關閉集群,從而可以通過腳本來執行整個測試過程。
這個工具連接到 AWS EC2 API 上,并用特定的 EC2 實例標簽激活多臺主機,允許我們的 puppet 代碼配置主機和安裝 Kafka(通過 External Node Classifiers
這個臨時集群腳本后來被用于創建臨時 Elasticsearch 集群進行集成測試,這證明了它是一個非常有用的工具。
zk-smoketest
我們發現,phunt 的 Zookeeper smoketest 腳本 Zookeeper 集群的狀態。在遷移的每個階段,我們在后臺運行 smoketest,以確保 Zookeeper 集群的行為符合預期。
zkcopy
我們的第一個用于遷移的計劃涉及關閉 Kafka、把 Zookeeper 數據子集復制到新集群、使用更新過的 Zookeeper 連接重啟 Kafka。遷移過程的一個更精細的版本——我們稱之為“阻止和復制(block & copy)”——被用于把 Zookeeper 客戶端遷移到存有數據的集群,這是因為“有絲分裂”過程需要一個空白的目標 Zookeeper 集群。用于復制 Zookeeper 數據子集的工具是 zkcopy,它可以把 Zookeeper 集群的子樹復制到另一個集群中。
我們還添加了事務支持,讓我們可以批量管理 Zookeeper 操作,并最大限度地減少為每個 znode 創建事務的網絡開銷。這使我們使用 zkcopy 的速度提高了約 10 倍。
另一個加速遷移過程的核心功能是“mtime”支持,它允許我們跳過復制早于給定修改時間的節點。我們因此避免了讓 Zookeeper 集群保持同步的第 2 個“catch-up”復制所需的大部分工作。Zookeeper 的停機時間從 25 分鐘減少為不到 2 分鐘。
經驗教訓
Zookeeper 集群是輕量級的,如果有可能,盡量不要在不同服務之間共享它們,因為它們可能會引起 Zookeeper 的性能問題,這些問題很難調試,并且通常需要停機進行修復。
我們可以在 Kafka 不停機的情況下讓 Kafka 使用新的 Zookeeper 集群,但是,這肯定不是一件小事。
如果在進行 Zookeeper 遷移時允許 Kafka 停機,那就簡單多了。
歡迎學Java和大數據的朋友們加入java架構交流: 855835163
加群鏈接:https://jq.qq.com/?_wv=1027&k=5dPqXGI
群內提供免費的架構資料還有:Java工程化、高性能及分布式、高性能、深入淺出。高架構。性能調優、Spring,MyBatis,Netty源碼分析和大數據等多個知識點高級進階干貨的免費直播講解 ?可以進來一起學習交流哦
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





