溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
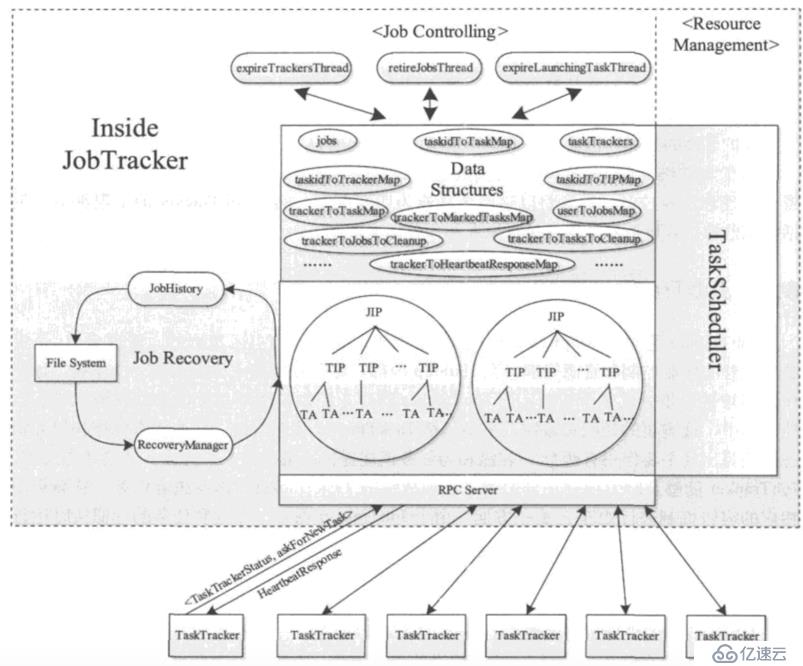
MR編程模型主要分為五個步驟:輸入、映射、分組、規約、輸出。
輸入(InputFormat):
主要包含兩個步驟—數據分片、迭代輸入
數據分片(getSplits):數據分為多少個splits,就有多少個map task;
單個split的大小,由設置的split.minsize和split.maxsize決定;
公式為 max{minsize, min{maxsize, blocksize}};
hadoop2.7.3之前blocksize默認64M,之后默認128M。
決定了單個split大小之后,就是hosts選擇,一個split可能包含多個block(將minsize設置大于128M);
而多個block可能分布在多個hosts節點上(一個block默認3備份,如果4個block就可能在12個節點),getsplits會選擇包含數據最多的一部分hosts。
由此可見,為了讓數據本地話更合理,最好是一個block一個task,也就是說split大小跟block大小一致。
getSplits會產生兩個文件
job.split:存儲的主要是每個分片對應的HDFS文件路徑,和其在HDFS文件中的起始位置、長度等信息(map task使用,獲取分片的具體位置);
job.splitmetainfo:存儲的則是每個分片在分片數據文件job.split中的起始位置、分片大小和hosts等信息(主要是作業初始化時使用,用于map task的本地化)。
迭代輸入:迭代輸入一條條的數據,對于文本數據來說,key就是行號、value當前行文本。
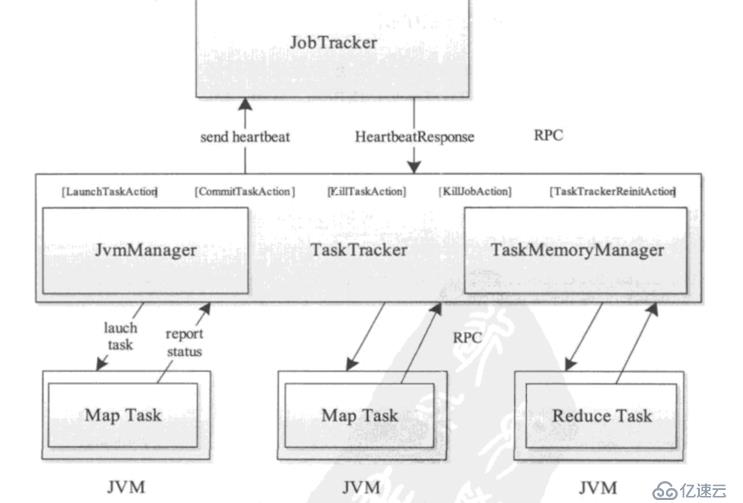
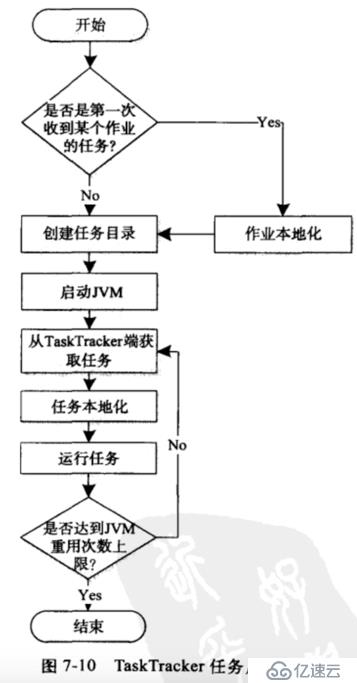
map task總共可以五個過程:read、map、collect、splill、conbine。
Read:從數據源讀入一條條數據;
map:將數據傳給map函數,變成另外一對KV
collect階段:
主要是map處理完的數據,先放入內存的環形緩沖區中,待環形緩沖區的值超過一定比例的時候再執行下一步的spill到磁盤;
collect()內部會調用getPartition來進行分區,而環形緩沖區則存儲的是K、V和partition號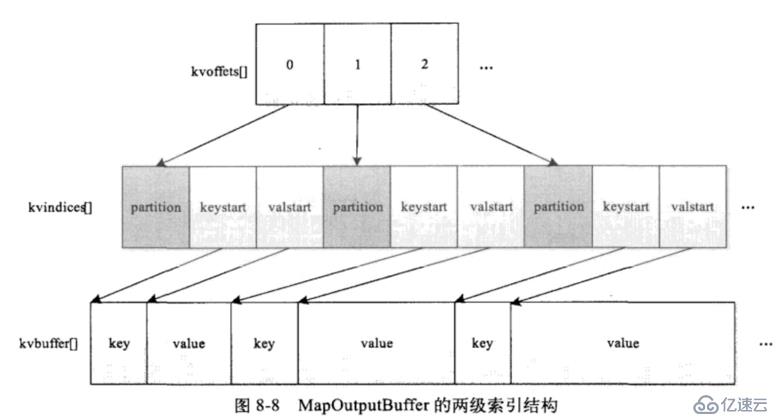
這里采用的兩級索引結構,主要是排序時在同一個partition內排序,所以先排partition,再排partition內部數據。
kvindices中記錄的分區號、key開始的位置、value開始的位置,也就是一對兒KV在kvindices中占用3個int,kvoffsets只記錄一對KV在kvindices中的偏移地址,所以只需要一個int,所以二者按1:3的大小分配內存。
spill過程:
環形緩存區中內存數據在超過一定閾值后會spill到磁盤上,在splill到磁盤上之前會先在內存中進行排序(快速排序);
之后按分區編號分別寫到臨時文件,同一個分區編號后面會有個數字,表示第幾次溢寫,conbine:對多個文件合并,多倫遞歸,沒輪合并最小的n個文件。
reduce總共可分為以下幾個階段:shuffle、merge、sort、reduce、write
shuffle:從JobTracker中獲取已完成的map task列表以及輸出位置,通過http接口獲取數據;
merge:shuffle拉去的數據線放入內存,內存不夠再放入磁盤,會有一個線程不斷地合并內存和磁盤中的數據
sort:reduce從不同的map task中拉取到多個有序文件,然后再做一次歸并排序,則每個reduce獲取到文件就都是有序的了
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





