溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Kubernetes的架構怎么使用”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Kubernetes的架構怎么使用”吧!
TensorFlow是一個使用數據流圖進行數值計算的開源軟件庫。圖中的節點代表數學運算,而圖中的邊則代表在這些節點之間傳遞的多維數組(張量)。這種靈活的架構可讓您使用一個 API 將計算工作部署到桌面設備、服務器或者移動設備中的一個或多個 CPU 或 GPU。 關于TensorFlow的基礎概念,我就不多介紹了。
下面是一個單機式TensorFlow訓練示意圖,通過Client提交Session,定義這個worker要用哪個cpu/gpu做什么事。
2016年4月TensorFlow發布了0.8版本宣布支持分布式計算,我們稱之為Distributed TensorFlow。這是非常重要的一個特性,因為在AI的世界里,訓練的數據量和模型參數通常會非常大。比如Google Brain實驗室今年發表的論文OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER中提到一個680億個Parameters的模型,如果只能單機訓練,那耗時難于接受。通過Distributed TensorFlow,可以利用大量服務器構建分布式TensorFlow集群來提高訓練效率,減少訓練時間。
通過TensorFlow Replcation機制,用戶可以將SubGraph分布到不同的服務器中進行分布式計算。TensorFlow的副本機制又分為兩種,In-graph和Between-graph。
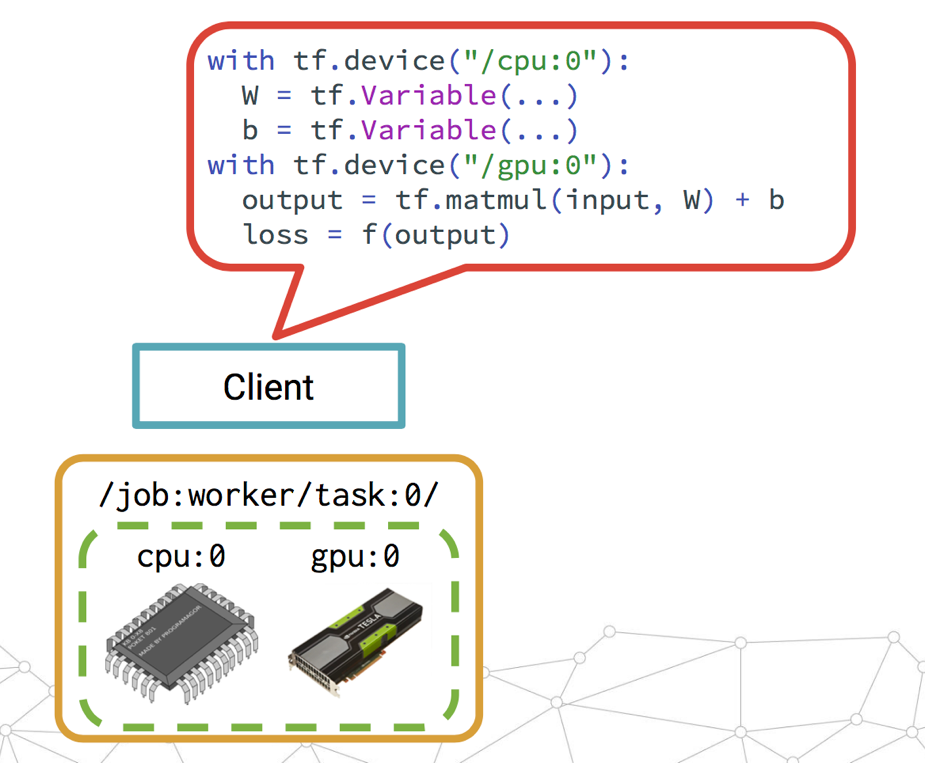
In-graph Replication簡單來講,就是通過單個client session定義這個TensorFlow集群的所有task的工作。
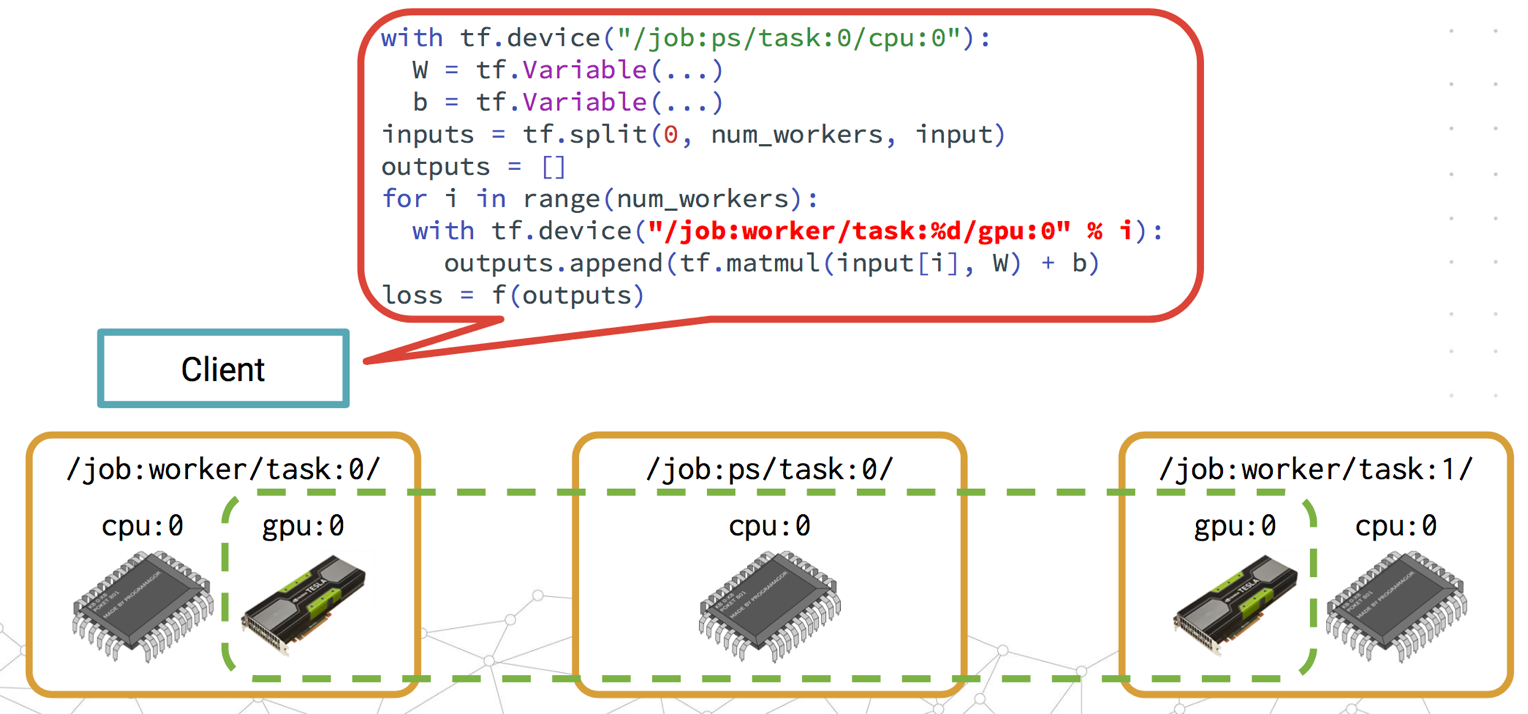
與之相對地,Between-graph Replication就是每個worker都有獨立的client來定義自己的工作。
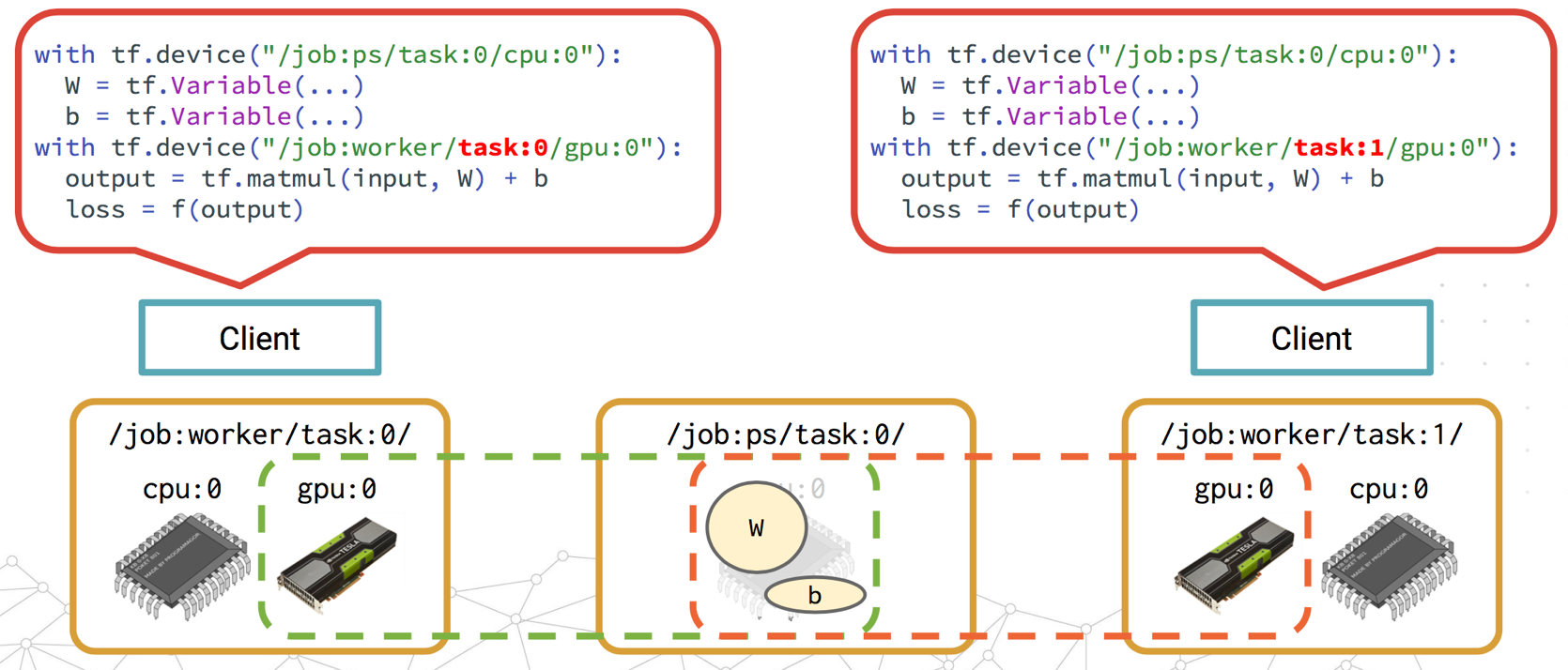
下面是抽象出來的分布式TensorFlow Framework如下:
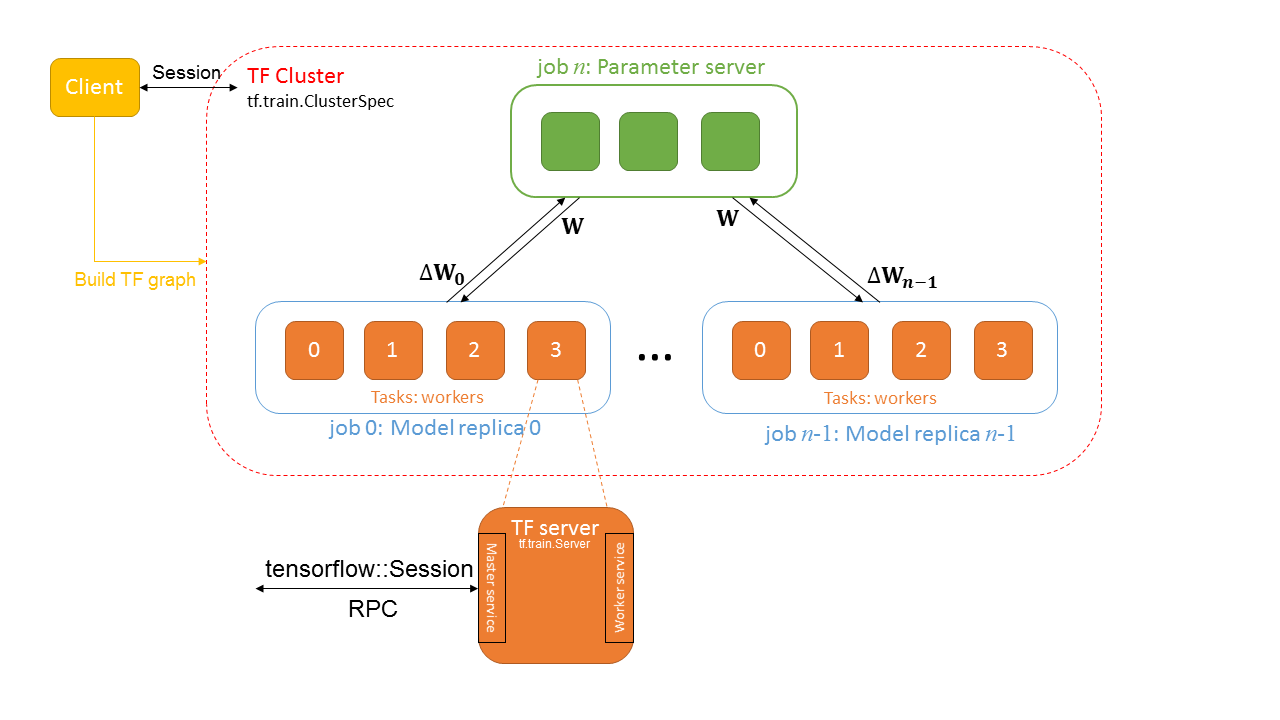
我們先來了解里面的幾個概念:
Cluster
一個TensorFlow Cluster有一個或多個jobs組成,每個job又由一個或多個tasks構成。Cluster的定義是通過tf.train.ClusterSpec來定義的。比如,定義一個由3個worker和2個ps的TensorFlow Cluster的ClusterSpec如下:
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222", //主機名也可以使用IP
"worker1.example.com:2222",
"worker2.example.com:2222"
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222"
]})Client
Client用來build一個TensorFlow Graph,并構建一個tensorflow::Session用來與集群通信。一個Client可以與多個TensorFlow Server交互,一個Server能服務多個Client。
Job
一個Job由tasks list組成,Job分ps和worker兩種類型。ps即parameter server,用來存儲和更新variables的,而worker可以認為是無狀態的,用來作為計算任務的。workers中,一般都會選擇一個chief worker(通常是worker0),用來做訓練狀態的checkpoint,如果有worker故障,那么可以從最新checkpoint中restore。
Task
每個Task對應一個TensorFlow Server,對應一個單獨的進程。一個Task屬于某個Job,通過一個index來標記它在對應Job的tasks中的位置。每個TensorFlow均實現了Master service和Worker service。Master service用來與集群內的worker services進行grpc交互。Worker service則是用local device來計算subgraph。
關于Distributed TensorFlow的更多內容,請參考官方內容www.tensorflow.org/deplopy/distributed
分布式TensorFlow能利用數據中心所有服務器構成的資源池,讓大量ps和worker能分布在不同的服務器進行參數存儲和訓練,這無疑是TensorFlow能否在企業落地的關鍵點。然而,這還不夠,它還存在一下先天不足:
訓練時TensorFlow各個Task資源無法隔離,很有可能會導致任務間因資源搶占互相影響。
缺乏調度能力,需要用戶手動配置和管理任務的計算資源。
集群規模大時,訓練任務的管理很麻煩,要跟蹤和管理每個任務的狀態,需要在上層做大量開發。
用戶要查看各個Task的訓練日志需要找出對應的服務器,并ssh過去,非常不方便。
TensorFlow原生支持的后端文件系統只支持:標準Posix文件系統(比如NFS)、HDFS、GCS、memory-mapped-file。大多數企業中數據都是存在大數據平臺,因此以HDFS為主。然而,HDFS的Read性能并不是很好。
當你試著去創建一個大規模TensorFlow集群時,發現并不輕松;
TensorFlow的這些不足,正好是Kubernetes的強項:
提供ResourceQuota, LimitRanger等多種資源管理機制,能做到任務之間很好的資源隔離。
支持任務的計算資源的配置和調度。
訓練任務以容器方式運行,Kubernetes提供全套的容器PLEG接口,因此任務狀態的管理很方便。
輕松對接EFK/ELK等日志方案,用戶能方便的查看任務日志。
支持Read性能更優秀的分布式存儲(Glusterfs),但目前我們也還沒對接Glusterfs,有計劃但沒人力。
通過聲明式文件實現輕松快捷的創建一個大規模TensorFlow集群。
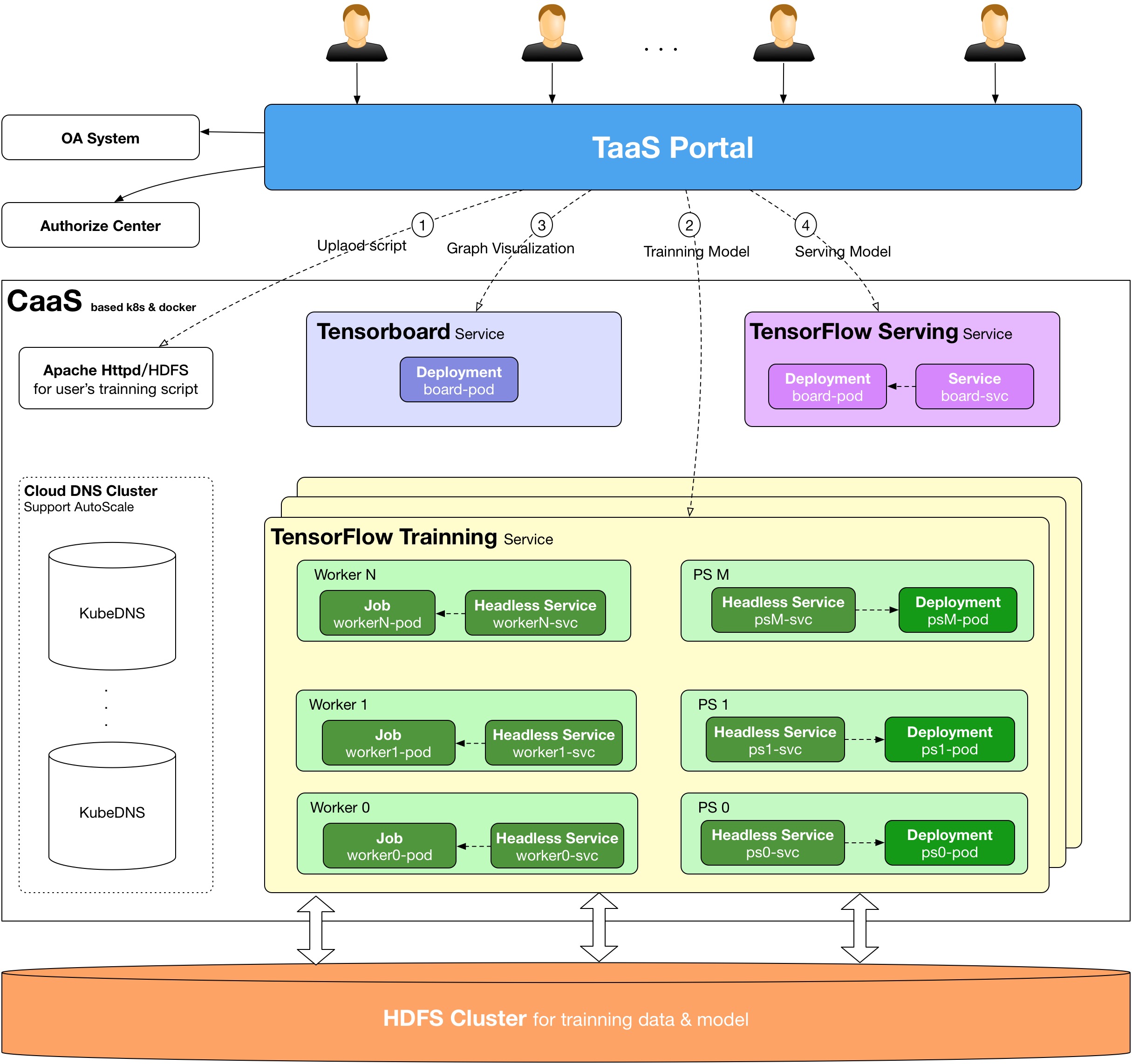
在我們的TensorFlow on Kubernetes方案中,主要用到以下的Kubernetes對象:
Kubernetes Job
我們用Kubernetes Job來部署TensorFlow Worker,Worker訓練正常完成退出,就不會再重啟容器了。注意Job中的Pod Template restartPolicy只能為Never或者OnFailure,不能為Always,這里我們設定restartPolicy為OnFailure,worker一旦異常退出,都會自動重啟。但是要注意,要保證worker重啟后訓練能從checkpoint restore,不然worker重啟后又從step 0開始,可能跑了幾天的訓練就白費了。如果你使用TensorFlow高級API寫的算法,默認都實現了這點,但是如果你是使用底層core API,一定要注意自己實現。
kind: Job
apiVersion: batch/v1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
template:
metadata:
labels:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
spec:
imagePullSecrets:
- name: harborsecret
containers:
- name: {{ name }}-{{ task_type }}-{{ i }}
image: {{ image }}
resources:
requests:
memory: "4Gi"
cpu: "500m"
ports:
- containerPort: 2222
command: ["/bin/sh", "-c", "export CLASSPATH=.:/usr/lib/jvm/java-1.8.0/lib/tools.jar:$(/usr/lib/hadoop-2.6.1/bin/hadoop classpath --glob); wget -r -nH -np --cut-dir=1 -R 'index.html*,*gif' {{ script }}; cd ./{{ name }}; sh ./run.sh {{ ps_hosts() }} {{ worker_hosts() }} {{ task_type }} {{ i }} {{ ps_replicas }} {{ worker_replicas }}"]
restartPolicy: OnFailureKubernetes Deployment
TensorFlow PS用Kubernetes Deployment來部署。為什么不像worker一樣,也使用Job來部署呢?其實也未嘗不可,但是考慮到PS進程并不會等所有worker訓練完成時自動退出(一直掛起),所以使用Job部署沒什么意義。
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
replicas: 1
template:
metadata:
labels:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
spec:
imagePullSecrets:
- name: harborsecret
containers:
- name: {{ name }}-{{ task_type }}-{{ i }}
image: {{ image }}
resources:
requests:
memory: "4Gi"
cpu: "500m"
ports:
- containerPort: 2222
command: ["/bin/sh", "-c","export CLASSPATH=.:/usr/lib/jvm/java-1.8.0/lib/tools.jar:$(/usr/lib/hadoop-2.6.1/bin/hadoop classpath --glob); wget -r -nH -np --cut-dir=1 -R 'index.html*,*gif' {{ script }}; cd ./{{ name }}; sh ./run.sh {{ ps_hosts() }} {{ worker_hosts() }} {{ task_type }} {{ i }} {{ ps_replicas }} {{ worker_replicas }}"]
restartPolicy: Always關于TensorFlow PS進程掛起的問題,請參考https://github.com/tensorflow/tensorflow/issues/4713.我們是這么解決的,開發了一個模塊,watch每個TensorFlow集群的所有worker狀態,當所有worker對應Job都Completed時,就會自動去刪除PS對應的Deployment,從而kill PS進程釋放資源。
Kubernetes Headless Service
Headless Service通常用來解決Kubernetes里面部署的應用集群之間的內部通信。在這里,我們也是這么用的,我們會為每個TensorFlow對應的Job和Deployment對象都創建一個Headless Service作為worker和ps的通信代理。
kind: Service
apiVersion: v1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
clusterIP: None
selector:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
ports:
- port: {{ port }}
targetPort: 2222用Headless Service的好處,就是在KubeDNS中,Service Name的域名解析直接對應到PodIp,而沒有service VIP這一層,這就不依賴于kube-proxy去創建iptables規則了。少了kube-proxy的iptables這一層,帶來的是性能的提升。
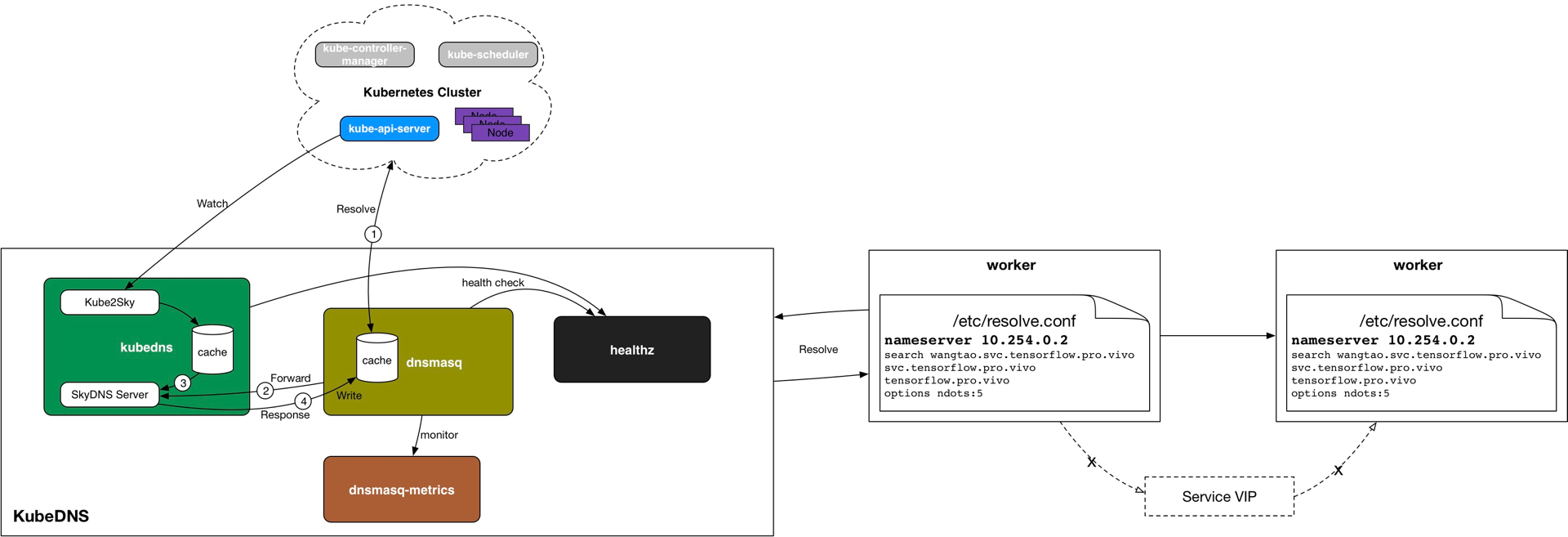
在TensorFlow場景中,這是不可小覷的,因為一個TensorFlow Task都會創建一個service,幾萬個service是很正常的事,如果使用Normal Service,iptables規則就幾十萬上百萬條了,增刪一條iptabels規則耗時幾個小時甚至幾天,集群早已奔潰。關于kube-proxy iptables模式的性能測試數據,請參考華為PaaS團隊的相關分享。
KubeDNS Autoscaler
前面提到,每個TensorFlow Task都會創建一個service,都會在KubeDNS中有一條對應的解析規則,但service數量太多的時候,我們發現有些worker的域名解析失敗概率很大,十幾次才能成功解析一次。這樣會影響TensorFlow集群內各個task的session建立,可能導致TensorFlow集群起不來。
為了解決這個問題,我們引入了Kubernetes的孵化項目kubernetes-incubator/cluster-proportional-autoscaler來對KubeDNS進行動態伸縮。關于這個問題的具體的細節,有興趣的同學可以查看我的博文https://my.oschina.net/jxcdwangtao/blog/1581879。
基于上面的方案,我們開發一個TaaS平臺,已經實現了基本的功能,包括算法管理、訓練集群的創建和管理、模型的管理、模型上線(TensorFlow Serving)、一鍵創建TensorBoard服務、任務資源監控、集群資源監控、定時訓練管理、任務日志在線查看和批量打包下載等等,這部分內容可以參考之前在DockOne上分享的文章http://dockone.io/article/3036。
這只是剛開始,我正在做下面的特性:
支持基于訓練優先級的任務搶占式調度: 用戶在TaaS上創建TensorFlow訓練項目時,可以指定項目的優先級為生產(Production)、迭代(Iteration)、調研(PTR),默認為迭代。優先級從高到低依次為**Production --> Iteration --> PTR**。但集群資源不足時,按照任務優先級進行搶占式調度。
提供像Yarn形式的資源分配視圖,讓用戶對自己的所有訓練項目的資源占用情況變得清晰。
訓練和預測的混合部署,提供數據中心資源利用率。
...
整個過程中,遇到了很多坑,有TensorFlow的,也有Kubernetes的,不過問題最多的還是我們用的CNI網絡插件contiv netplugin,每次大問題基本都是這個網絡插件造成的。Kubernetes是問題最少的,它的穩定性比我預期還要好。
contiv netplugin的問題,在DevOps環境中還是穩定的,在大規模高并發的AI場景,問題就層出不窮了,產生大量垃圾IP和Openflow流表,直接把Node都成NotReady了,具體的不多說,因為據我了解,現在用這個插件的公司已經很少了,想了解的私下找我。
在我們的方案中,一個TensorFlow訓練集群就對應一個Kubernetes Namespace,項目初期我們并沒有對及時清理垃圾Namespace,到后來集群里上萬Namespace的時候,整個Kubernetes集群的相關API性能非常差了,導致TaaS的用戶體驗非常差。
TensorFlow grpc性能差,上千個worker的訓練集群,概率性的出現這樣的報錯grpc_chttp2_stream request on server; last grpc_chttp2_stream id=xxx, new grpc_chttp2_stream id=xxx,這是TensorFlow底層grpc的性能問題,低版本的grpc的Handlergrpc還是單線程的,只能嘗試通過升級TensorFlow來升級grpc了,或者編譯TensorFlow時單獨升級grpc版本。如果升級TensorFlow版本的話,你的算法可能還要做API適配。目前我們通過增加單個worker的計算負載來減少worker數量的方法,減少grpc壓力。
還有TensorFlow 自身OOM機制的問題等等
感謝各位的閱讀,以上就是“Kubernetes的架構怎么使用”的內容了,經過本文的學習后,相信大家對Kubernetes的架構怎么使用這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





